作者:Edo Liberty, Guillermo Rauch, Ori Goshen, Robert Nishihara, Harrison Chase
2030年的人工智能
人工智能正在飞速发展。对于大多数人来说,速度太快了。十年前,一切都围绕着大数据和机器学习。深度学习还是一个“热门”词汇,刚刚开始兴起。“人工智能”一词仍然是人类水平智能这一未来梦想的代名词。这项技术主要被超大规模企业用于广告优化、搜索、在线媒体中的信息流排名、购物中的产品推荐、在线滥用预防以及其他一些核心用例。五年前,当公司开始努力解决特征工程和模型部署问题时,机器学习运维(ML Ops)风靡一时。他们的目标主要与数据标注、客户流失预测、推荐、图像分类、情感分析、自然语言处理和其他标准的机器学习任务有关。大约一年前,大型语言模型(LLM)和基础模型彻底改变了我们对人工智能的期望。公司开始投资聊天机器人和由检索增强生成(RAG)驱动的知识中心,以实现客户支持、法律发现、医疗病史等的自动化。展望2024年及以后,代理和副驾驶似乎将成为中心舞台。并且,解决幻觉问题,同时使大型语言模型在面向用户的产品中更值得信赖和可用,将成为主要焦点。我们不知道在那之后人工智能会是什么样子,更不用说2030年了。我们非常肯定没有人知道。
然而,在这一令人眼花缭乱的创新狂潮中,几乎所有基于人工智能的解决方案的基础设施组件都出人意料地保持不变。
有些东西不会改变...
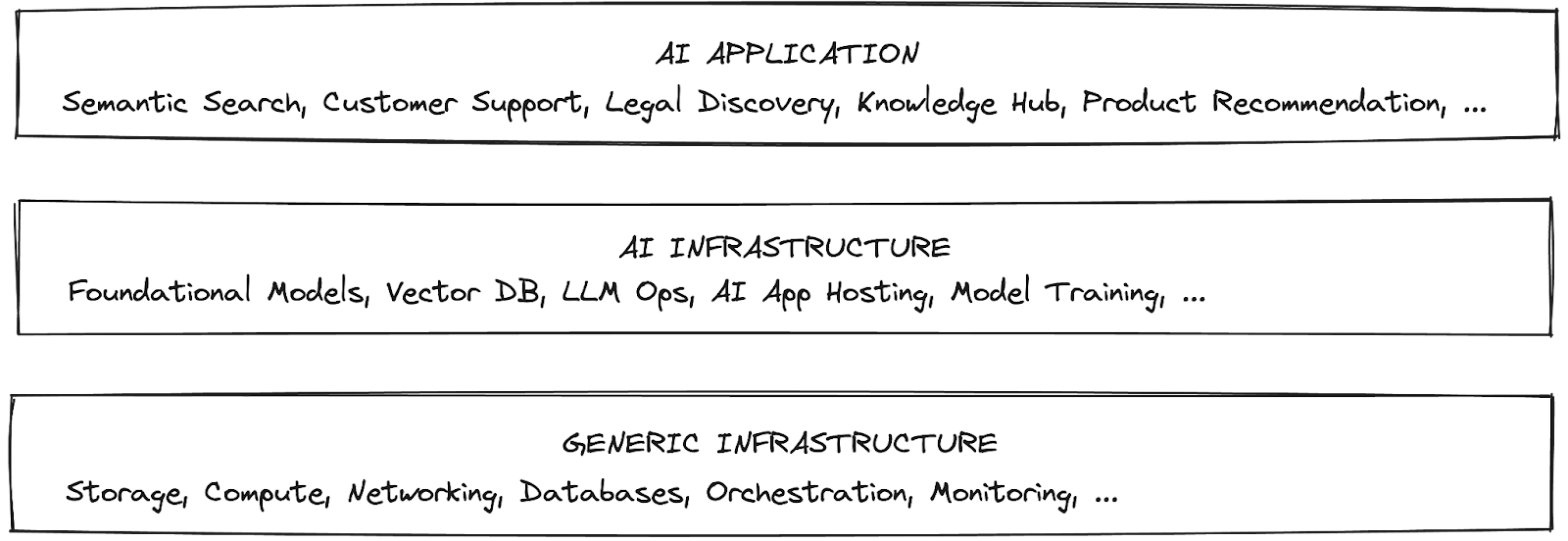
虽然有许多人工智能产品架构,但一些核心的基础设施构建模块似乎为几乎所有架构提供动力。这些包括模型训练和托管、预训练的基础模型、向量数据库、模型管道和数据操作、标注、评估框架以及人工智能应用托管等能力。
这些组件并不新鲜。谷歌的广告服务多年来一直在使用向量搜索进行候选生成。Meta在十多年前就开始构建用于信息流排名模型训练的分布式神经网络训练。与此同时,亚马逊正在生成用于购物推荐的多模态嵌入,而微软则将基于向量的检索和排名构建到必应(Bing)中。这些只是一些例子。
市场其余部分面临的主要挑战是,人工智能技术栈被限制在超大规模企业中。这些是唯一有规模来证明其开发合理性和有才能来支持它的公司。其他公司则面临着放弃和做出巨大努力进行内部构建的艰难选择。像优步(Uber)、奈飞(Netflix)、雅虎(Yahoo)、Salesforce、Pinterest等公司,与它们的业务规模相比,它们在人工智能人才和技术方面的投资非常显著(且具有远见卓识)。
今天,公司不再有这种困境。他们可以选择简单地使用人工智能基础设施(来自像我们这样的公司)。事实上,这些工具现在唾手可得,易于使用且价格实惠。但是,我们有点超前了...
未来的挑战
在描述新的技术栈之前,我们概述人工智能应用将面临的当前和未来挑战。请注意,人工智能应用面临所有其他软件服务面临的所有挑战。诸如代码质量、部署、正常运行时间、速度、正确性等问题。以下列表仅指出独特的新的挑战。
多模态数据和模型很快将成为常态。今天基于文本的应用将被图像和视频淹没。现有服务将变得数据密集得多,并且必须重新思考其在整个技术栈中的接口。
数据正在增长并变得更加复杂。大量文本和多模态数据将不得不被模型处理,并实时提供给人工智能应用。此类应用期望通过含义访问数据作为知识来源。大多数工程师熟悉的传统数据库,在这种应用中会非常吃力。
硬件正在变化。一个蓬勃发展的硬件加速器生态系统将开始缓解当今的一些计算短缺问题,但利用(和混合使用)广泛且不断发展的加速器集合的需求将对可移植性和性能优化提出新的挑战。
应用开发正变得更加以人工智能为中心,并与先进的工具和人工智能能力紧密集成。这意味着传统的Web开发正变得更加存储和计算密集型。
模型训练也在转型。随着基础模型的出现,我们不再(仅仅)从头开始进行模型开发。需要模型再训练和微调的能力。虽然这大大减轻了计算负担,但也对模型定制和组合提出了新的挑战,这将使我们本已紧张的模型评估能力更加紧张。
云中心化正在成为关键的成功因素。在数据引力和模型引力之间进行权衡需要新的云原生服务,这些服务在其计算、存储和网络使用方面非常动态和优化。此外,云可移植性和跨云功能正成为许多人的核心设计原则。这就是为什么实际上整个人工智能技术栈仅作为主要云提供商的云原生服务提供。
毋庸置疑,内部构建这些能力对于大多数人来说是不可行的,对于几乎所有人来说也是不必要的。为了利用这些新机会,企业将需要学习如何使用正确的基础设施。该基础设施必须满足这些需求,而且还必须面向未来。这意味着要针对灵活性、迭代速度和通用适用性进行优化。
人工智能技术栈
基础模型:模型预计将转换文档或执行任务。转换通常意味着生成向量嵌入,用于摄取到向量数据库中,或生成特征以完成任务。任务包括文本和图像生成、标注、摘要、转录等。训练此类模型和在生产中高效运行它们都非常具有挑战性且极其昂贵。像AI21 Labs这样的公司提供一流的大型语言模型(LLM),这些模型针对嵌入和生成进行了高度优化,并且AI21 Labs还构建高度专业化的模型来解决特定的业务挑战。它们不仅被托管,而且还不断地被重新训练和改进。
模型训练和部署:人工智能工作负载的决定性特征之一是它们的计算密集程度。因此,成功的人工智能团队在构建时会考虑到规模。他们对规模的需求来自更大的模型、更多的数据量以及爆炸式增长的模型构建和部署数量。仅仅计算支持一个普通的检索增强生成(RAG)应用的嵌入就需要数百个GPU运行数天。
对规模的需求带来了围绕性能、成本和可靠性的巨大软件工程挑战,所有这些都不能以牺牲开发者速度为代价。Anyscale开发了Ray,这是一个开源项目,被用作整个科技行业人工智能基础设施的基础,并用于训练像GPT-4这样的一些世界上最大的模型。
向量数据库:知识是人工智能的核心,语义检索是使模型能够实时获取相关信息的关键。为此,向量数据库已经成熟和专门化,能够以毫秒级的速度搜索数十亿个嵌入,并且仍然具有成本效益。Pinecone最近推出了其新架构的云原生和无服务器向量数据库。它现在让公司可以无限扩展,并以前所未有的速度构建高性能应用(如检索增强生成(RAG))。许多公司通过这款新产品将其数据库支出减少了高达50倍。
人工智能应用托管:人工智能应用为应用渲染、交付和安全技术栈带来了独特的全新挑战。首先,与传统网站不同,人工智能应用本质上更具动态性,使得传统的CDN缓存效果较差,并且依赖于服务器渲染和流式传输来满足用户的速度和个性化需求。随着人工智能领域快速发展,快速迭代新模型、提示、实验和技术至关重要,并且应用流量可能会呈指数级增长,这使得无服务器平台特别有吸引力。在安全性方面,人工智能应用已成为机器人攻击的常见目标,目的是窃取或拒绝大型语言模型(LLM)资源或抓取专有数据。Next.js和Vercel正在大力投资于面向生成式人工智能(GenAI)公司的产品基础设施,从而提高开发者的迭代速度,并为最终用户提供快速、安全的交付。
大型语言模型(LLM)开发者工具包:构建大型语言模型(LLM)应用需要将上述所有组件组合在一起,以构建系统的“认知架构”。拥有像LangChain这样的大型语言模型(LLM)工具包来将这些不同的组件组合在一起,可以使工程师能够更快地构建更高质量的应用。此工具包中的重要组件包括:灵活创建自定义链的能力(您很可能希望自定义您的认知架构)、各种集成(有许多不同的组件需要连接)以及一流的流式传输支持(大型语言模型(LLM)应用的重要用户体验考虑因素)。
大型语言模型(LLM)运维(Ops):构建原型是一回事,将其投入生产完全是另一回事。除了托管应用的后勤保障(上面已介绍)之外,还出现了一整套围绕应用可靠性的问题。常见的问题包括能够测试和评估不同的提示或模型,能够跟踪和调试单个调用以找出系统中哪里出了问题,以及能够随着时间的推移监控反馈。LangSmith——由LangChain团队构建但独立于该框架的平台——是解决这些问题的综合解决方案。
我们的承诺
作为构建新人工智能技术栈的首席执行官们,我们致力于使您的人工智能应用面向未来。我们致力于构建最佳的构建模块。我们致力于不断改进我们产品之间的集成。我们承诺包含其他人工智能产品和服务,并与之共同发展。我们承诺在您的需求随着时间推移而演变时与您同在。我们致力于您在未来几年内成功利用人工智能。
作者简介
Edo Liberty,Pinecone首席执行官
Edo Liberty是Pinecone的创始人兼首席执行官,Pinecone是用于大规模向量搜索的托管数据库。Edo之前曾担任AWS的研究主管和亚马逊人工智能实验室主管以及雅虎研究实验室主管,负责构建横向机器学习平台。Edo在特拉维夫大学获得物理学和计算机科学学士学位,并在耶鲁大学获得计算机科学博士学位。之后,他在耶鲁大学应用数学项目担任博士后研究员。他是75多篇关于机器学习、系统和优化方面的学术论文和专利的作者。
Guillermo Rauch,Vercel首席执行官
Guillermo Rauch是Vercel的创始人兼首席执行官,也是Next.js的创建者,Next.js为网络上领先的生成式人工智能公司提供支持。Guillermo之前共同创立了LearnBoost和Cloudup,并在2013年被Automattic收购之前担任公司的首席技术官。Guillermo来自阿根廷,自十岁起就是一名开发人员,并且热衷于为开源社区做出贡献。
Ori Goshen,AI21 Labs联合首席执行官
Ori Goshen是一位经验丰富的企业家,也是以色列国防军(IDF)精英情报部门8200的毕业生。在创立AI21 Labs之前,他共同创立了网络分析公司Crowdx(被Cellwize收购)。在此之前,Goshen先生曾在Fring(被Genband收购)担任产品经理,并领导开发了首个面向iPhone和Android的VoIP和消息应用。Goshen先生在技术和产品领导职位方面拥有超过15年的经验。
Robert Nishihara,Anyscale首席执行官
Robert Nishihara是Ray的创建者之一,Ray是一个分布式框架,用于无缝扩展和生产化人工智能工作负载。优步(Uber)、OpenAI、奈飞(Netflix)、亚马逊(Amazon)等创新公司使用Ray来扩展机器学习训练、推理和数据摄取工作负载。Robert与他在加州大学伯克利分校RISE实验室的联合创始人一起开发了Ray。他获得了机器学习博士学位,并共同创立了Anyscale以将Ray商业化。在此之前,他在哈佛大学主修数学。
Harrison Chase,LangChain首席执行官
Harrison Chase是LangChain的联合创始人兼首席执行官,LangChain是一家围绕流行的开源Python/Typescript软件包成立的公司。LangChain的目标是尽可能轻松地使用大型语言模型(LLM)来开发上下文感知的推理应用。在创立LangChain之前,他曾在Robust Intelligence(一家专注于机器学习模型测试和验证的机器学习运维(MLOps)公司)领导机器学习团队,在Kensho(一家金融科技初创公司)领导实体链接团队,并在哈佛大学学习统计学和计算机科学。