
编者按:本文与 Xata 团队合作撰写。我们对他们新的集成感到兴奋,并非常享受他们对使用他们实现问答聊天机器人的深入探讨。
在过去的几周里,我们已将四个 Xata 集成合并到 LangChain 存储库中,今天我们很高兴地宣布它们成为 Xata 发布周 的一部分!在这篇博文中,我们将简要介绍 Xata 是什么,以及为什么它是 AI 应用程序的良好数据伴侣。我们还将展示一个代码示例,用于实现一个问答聊天机器人,该机器人根据 Xata 数据库(作为向量存储)中的信息回答问题,并将长期记忆存储在 Xata 中(作为内存存储)。
什么是 Xata?
Xata 是一个由 PostgreSQL 驱动的数据库平台。它将源数据存储在 PostgreSQL 中,但也自动将其复制到 Elasticsearch。这意味着它在同一个简单的无服务器 API 背后,提供了来自 Postgres(ACID 事务、连接、约束等)和 Elasticsearch(BM25 全文搜索、向量搜索、混合搜索)的功能。这涵盖了大多数 AI 应用程序所需的功能,并且由于它基于 PostgreSQL 和 Elasticsearch,因此它可靠且可扩展。
Xata 具有适用于 TypeScript/JavaScript 和 Python 的客户端 SDK,并内置了与 GitHub、Vercel 和 Netlify 等平台的集成。
在 AI 领域,除了此处宣布的 LangChain 集成之外,Xata 还提供与 OpenAI 的深度集成,用于“在您的数据上使用 ChatGPT” 用例。
集成
截至今日,以下集成可用:
- Xata 作为 LangChain 中的向量存储。这允许人们将带有嵌入的文档存储在 Xata 表中,并对它们执行向量搜索。该集成利用了 新近 GA 发布的 Python SDK。该集成支持按元数据进行过滤,元数据在 Xata 列中表示,以获得最佳性能。
- Xata 作为 LangChain.js 中的向量存储。与 Python 集成相同,但适用于您的 TypeScript/JavaScript 应用程序。
- Xata 作为 LangChain 中的内存存储。这允许在 Xata 中存储 AI 聊天会话的聊天消息历史记录,使其充当 LLM 应用程序的“内存”。消息存储在
- Xata 作为 LangChain.js 中的内存存储。 与 Python 集成相同,但适用于 TypeScript/JavaScript。
每个集成都附带一个或两个代码示例,在上面链接的文档页面中。
这四个集成已经使 Xata 成为 LangChain 最全面的数据解决方案之一,而我们才刚刚开始! 在不久的将来,我们计划为 Xata 关键字和混合搜索以及 Xata Ask AI 端点添加自定义检索器。
示例:带记忆的对话式问答
虽然每个 LangChain 集成都至少带有一个最小的代码示例,但在本博文中,我们将看一个更复杂的示例,该示例同时使用 Xata 作为向量存储和内存存储。该应用程序实现了“与您的数据聊天”用例,并允许进行后续问题。完整的代码可以在这个 仓库 中找到,您也可以将其用作 LangChain + Xata 应用程序的入门工具包。
虽然此处的示例应用程序是用 TypeScript 编写的,但在 Jupyter notebook 中可以找到使用 Python LangChain 的类似示例。
代码的主要部分如下所示
import * as dotenv from "dotenv";
import { XataVectorSearch } from "langchain/vectorstores/xata";
import { OpenAIEmbeddings } from "langchain/embeddings/openai";
import { Document } from "langchain/document";
import { ConversationalRetrievalQAChain } from "langchain/chains";
import { BufferMemory } from "langchain/memory";
import { XataChatMessageHistory } from "langchain/stores/message/xata";
import { ChatOpenAI } from "langchain/chat_models/openai";
import { getXataClient } from "./xata.ts";
dotenv.config();
const client = getXataClient();
/* Create the vector store */
const table = "docs";
const embeddings = new OpenAIEmbeddings();
const vectorStore = new XataVectorSearch(embeddings, { client, table });
/* Add documents to the vector store */
const docs = [
new Document({
pageContent: "Xata is a Serverless Data platform based on PostgreSQL",
}),
new Document({
pageContent:
"Xata offers a built-in vector type that can be used to store and query vectors",
}),
new Document({
pageContent: "Xata includes similarity search",
}),
];
const ids = await vectorStore.addDocuments(docs);
// eslint-disable-next-line no-promise-executor-return
await new Promise((r) => setTimeout(r, 2000));
/* Create the chat memory store */
const memory = new BufferMemory({
chatHistory: new XataChatMessageHistory({
table: "memory",
sessionId: new Date().toISOString(), // Or some other unique identifier for the conversation
client,
createTable: false,
}),
memoryKey: "chat_history",
});
/* Initialize the LLM to use to answer the question */
const model = new ChatOpenAI({});
/* Create the chain */
const chain = ConversationalRetrievalQAChain.fromLLM(
model,
vectorStore.asRetriever(),
{
memory,
}
);
/* Ask it a question */
const question = "What is Xata?";
const res = await chain.call({ question });
console.log("Question: ", question);
console.log(res);
/* Ask it a follow up question */
const followUpQ = "Can it do vector search?";
const followUpRes = await chain.call({
question: followUpQ,
});
console.log("Follow-up question: ", followUpQ);
console.log(followUpRes);
/* Clear both the vector store and the memory store */
await vectorStore.delete({ ids });
await memory.clear();
让我们逐部分了解它所做的事情
首先,我们使用 Xata 作为向量存储。在这个向量存储中,我们索引了一些示例文档,但在实际应用中,您可以索引数万个文档。这些是我们的聊天机器人将用来查找用户问题答案的文档。虽然此处未显示,但也可以向这些文档添加自定义元数据列。您可以在 集成页面 上查看示例。
/* Create the vector store */
const table = "docs";
const embeddings = new OpenAIEmbeddings();
const vectorStore = new XataVectorSearch(embeddings, { client, table });
/* Add documents to the vector store */
const docs = [
new Document({
pageContent: "Xata is a Serverless Data platform based on PostgreSQL",
}),
new Document({
pageContent:
"Xata offers a built-in vector type that can be used to store and query vectors",
}),
new Document({
pageContent: "Xata includes similarity search",
}),
];
const ids = await vectorStore.addDocuments(docs);
接下来,我们创建一个聊天内存存储,同样基于 Xata。这会将聊天机器人与用户交换的消息存储在 Xata 表中。每个对话都有一个会话 ID,然后用于检索对话中之前的消息,以便上下文不会丢失。
/* Create the chat memory store */
const memory = new BufferMemory({
chatHistory: new XataChatMessageHistory({
table: "memory",
sessionId: new Date().toISOString(), // Or some other unique identifier for the conversation
client,
createTable: false,
}),
memoryKey: "chat_history",
});
然后,我们初始化客户端以查询模型,在本例中是 OpenAI ChatGPT API
/* Initialize the LLM to use to answer the question */
const model = new ChatOpenAI({});
最后,将它们全部放在一个对话式问答链中
/* Create the chain */
const chain = ConversationalRetrievalQAChain.fromLLM(
model,
vectorStore.asRetriever(),
{
memory,
}
);
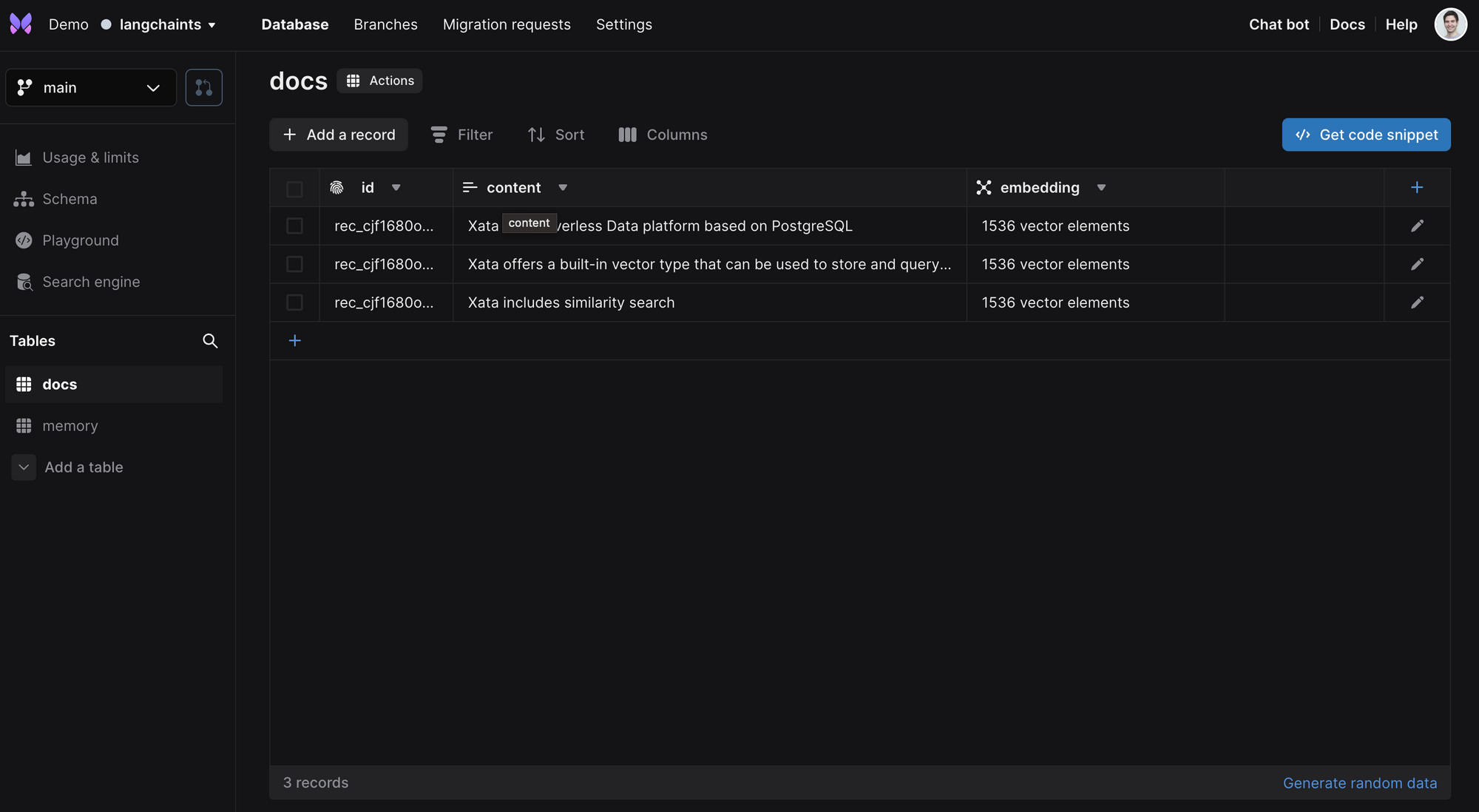
如果您在示例运行时通过 Xata UI 查看数据,您将看到两个表:docs 和 memory。docs 表填充了来自向量存储的文档,具有 content 列和一个 embedding 列,类型为 vector
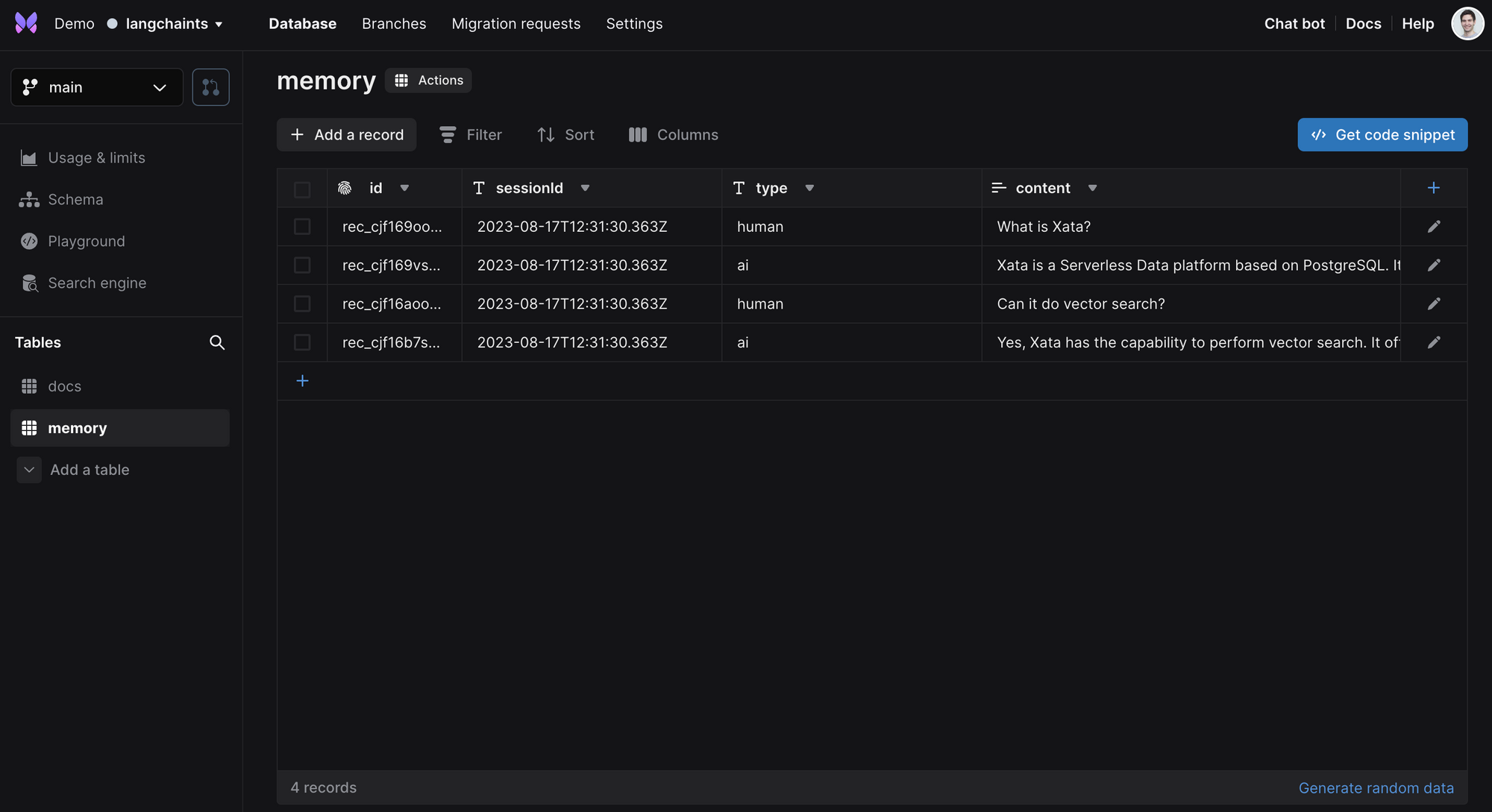
memory 表填充了来自用户和 AI 的问题和答案
内容黑客马拉松
作为发布周的一部分,Xata 还组织了一个内容黑客马拉松,您可以通过创建应用程序、撰写博客、录制视频等方式赢得奖品和礼品。有关详细信息,请参阅 发布周博文。
如果您有任何问题或想法,或者您在将 Xata 与 LangChain 结合使用时需要帮助,请加入我们的 Discord 或在 Twitter 上联系我们。