
编者按:这篇博文是与 Zep 合作撰写的,Zep 是 LangSmith BETA 版本的早期用户。我们收到了很多关于 LangChain 应用程序延迟的问题 - 延迟来自哪里,如何改进。这是一个非常棒的演练,展示了 LangSmith 如何让您轻松诊断应用程序中延迟的原因,以及 LangChain 生态系统的不同组件(在本例中为 Zep)如何用于改进延迟。
摘要
糟糕的聊天机器人响应时间可能会导致用户沮丧和客户流失。LangChain 的新 LangSmith 服务可以简单轻松地了解是什么导致了 LLM 应用中的延迟。在本文中,我们使用 LangSmith 来诊断性能不佳的 LangChain 应用程序,并演示了我们如何使用 Zep 内存存储将性能提升了一个数量级。
本文的源代码:https://github.com/getzep/zep-by-example/tree/main/langchain/python/langsmith-latency
如果您曾经等待网页加载几秒钟并决定点击其他地方,那么您并不孤单。关于网站速度缓慢及其 对用户参与度和转化率的影响,已经有很多文章进行了阐述。聊天机器人的响应时间也一样。虽然响应过快可能会 将用户推入恐怖谷,但响应缓慢也是有问题的。用户会变得 沮丧,并且不太可能再次使用您的服务。他们也可能认为 聊天机器人不公平,并且不愿意分享个人信息。
不幸的是,构建一个缓慢的聊天机器人非常容易。在多个链、高 LLM 延迟以及使用聊天历史、摘要和来自向量数据库的结果丰富提示之间,很多因素都会影响您的机器人响应速度。
检测和分析您的应用程序可能具有挑战性,并且非常耗时。LangChain 的新 LangSmith 服务 非常出色地完成了这项工作,并且无需手动检测您的应用程序。在本文中,我将带您了解一个简单的聊天机器人应用程序示例,虽然简单,但与您可能正在构建的应用程序并无不同。
我的聊天机器人太慢了
我使用 LangChain 构建了一个聊天机器人应用程序,但我的用户不满意并正在流失。
用户希望与机器人进行对话,并希望机器人不会忘记对话中先前消息的上下文和细节。因此,在构建机器人时,我使用了 LangChain 内存类。我还使用了一个 Retriever,由 Chroma 的向量数据库支持,以回忆起遥远过去的有关消息。将来,我也许还会使用 Retriever 来根据业务文档来 grounding 我的应用程序。像许多 Langchain 开发人员一样,我使用了 OpenAI 的 API 来进行 LLM 完成和文档嵌入。
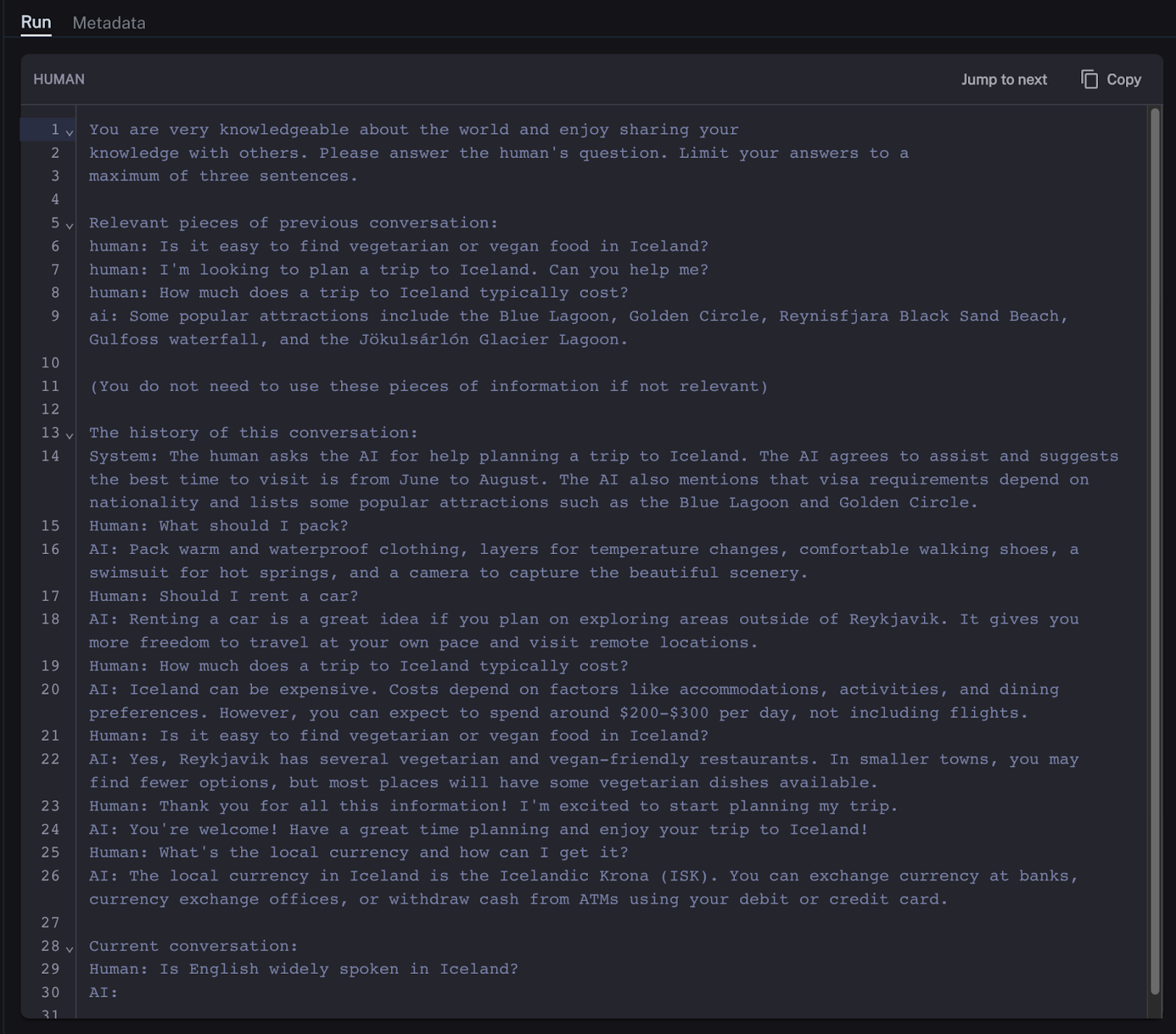
使用内存实例和 Retriever,我的链会将聊天历史记录注入到发送给 LLM 的提示中。LLM 上下文窗口是有限的,并且大型提示成本更高,LLM 响应时间也更长。因此,我不想将整个聊天历史记录都发送给 LLM。相反,我希望将其限制为最近的消息,并让我的链总结更久远过去的消息。提示看起来会像这样
LangSmith 来救援
如前所述,我的聊天应用程序太慢了,我的用户正在流失。我真的想弄清楚为什么会发生这种情况。过去,我必须在应用程序的许多不同地方进行检测,以捕获各种操作的计时,这是一项耗时且棘手的工作。幸运的是,LangChain 团队已经为我们检测了 LangChain 代码库,LangSmith 使理解应用程序的性能变得简单。我所要做的就是配置我的 LangSmith API 密钥,并在我的代码中添加几个描述性标签。
为了进行调查,我整理了一个简单的测试套件,使用了 30 条消息,其中 20 条预加载到 LangChain 内存类中,10 条用于实验本身。实验的每次运行都将这 10 条消息传递给链。我这样做五次,以便了解实验的差异。
LangSmith 中的结果如下所示。10 条消息的每次运行都有一个唯一的名称,并且是多个链运行的父级。
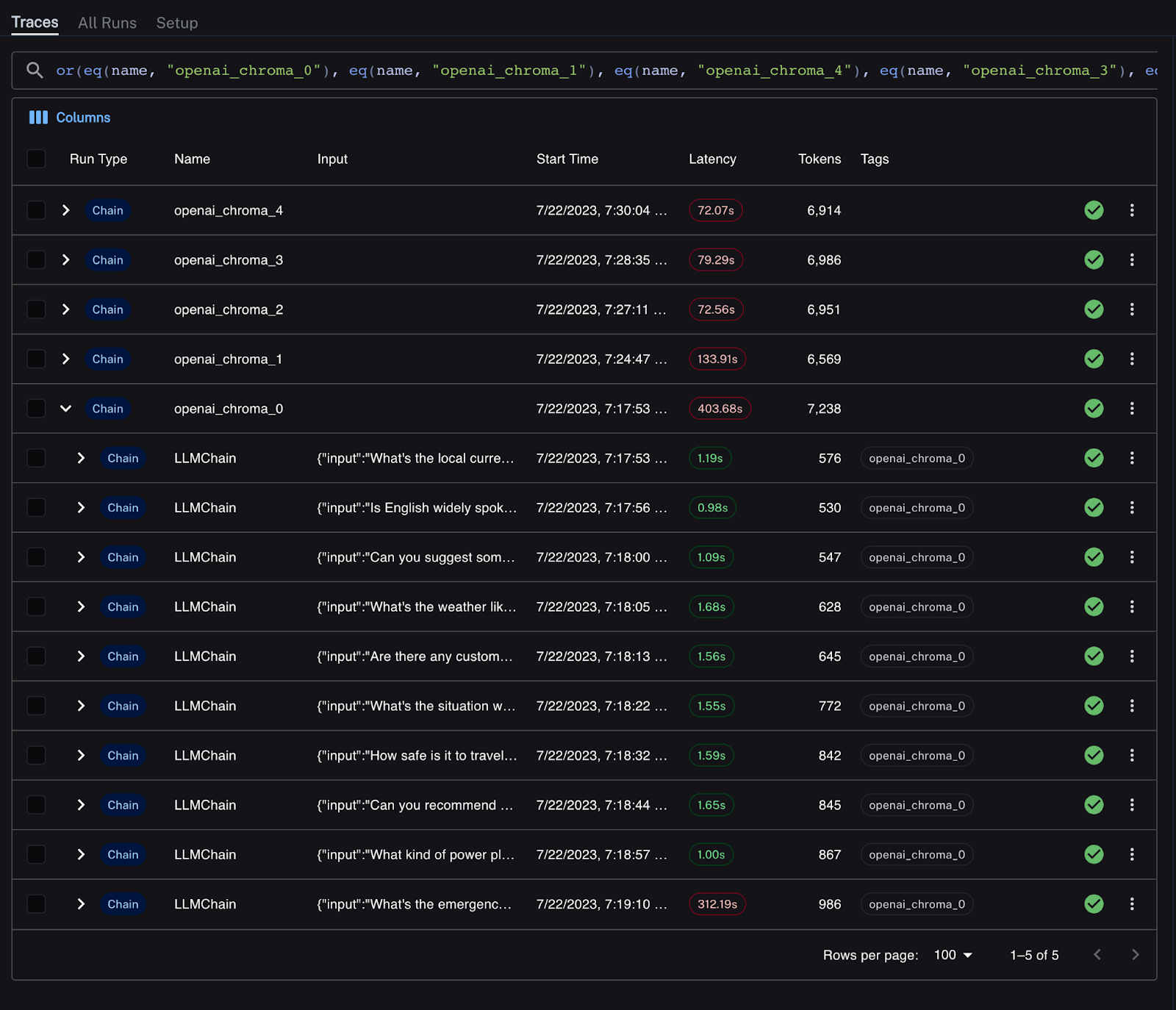
延迟在 LangSmith UI 中清晰可见,不良延迟以红色标记。我可以轻松地深入研究实验的每次运行,以更好地了解发生这种情况的原因。所有实验运行都很慢,响应每条消息的平均时间超过 7-13 秒。其中一次运行是明显的异常值。
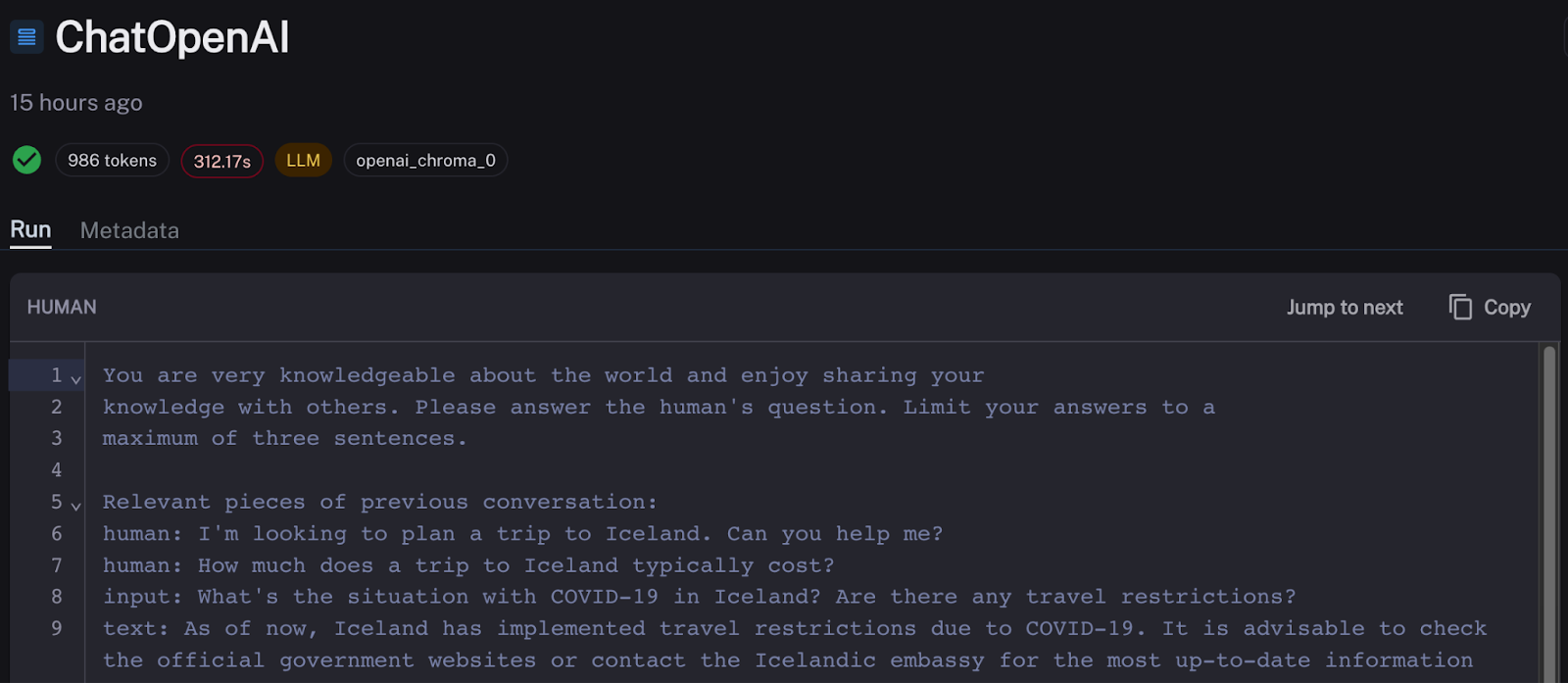
深入研究该链,我看到 OpenAI API 的响应时间很差,响应请求花费了 5 分多钟。可能是初始请求失败,并且进行了重试。不幸的是,OpenAI API 有时会出现速率限制和高延迟差异。
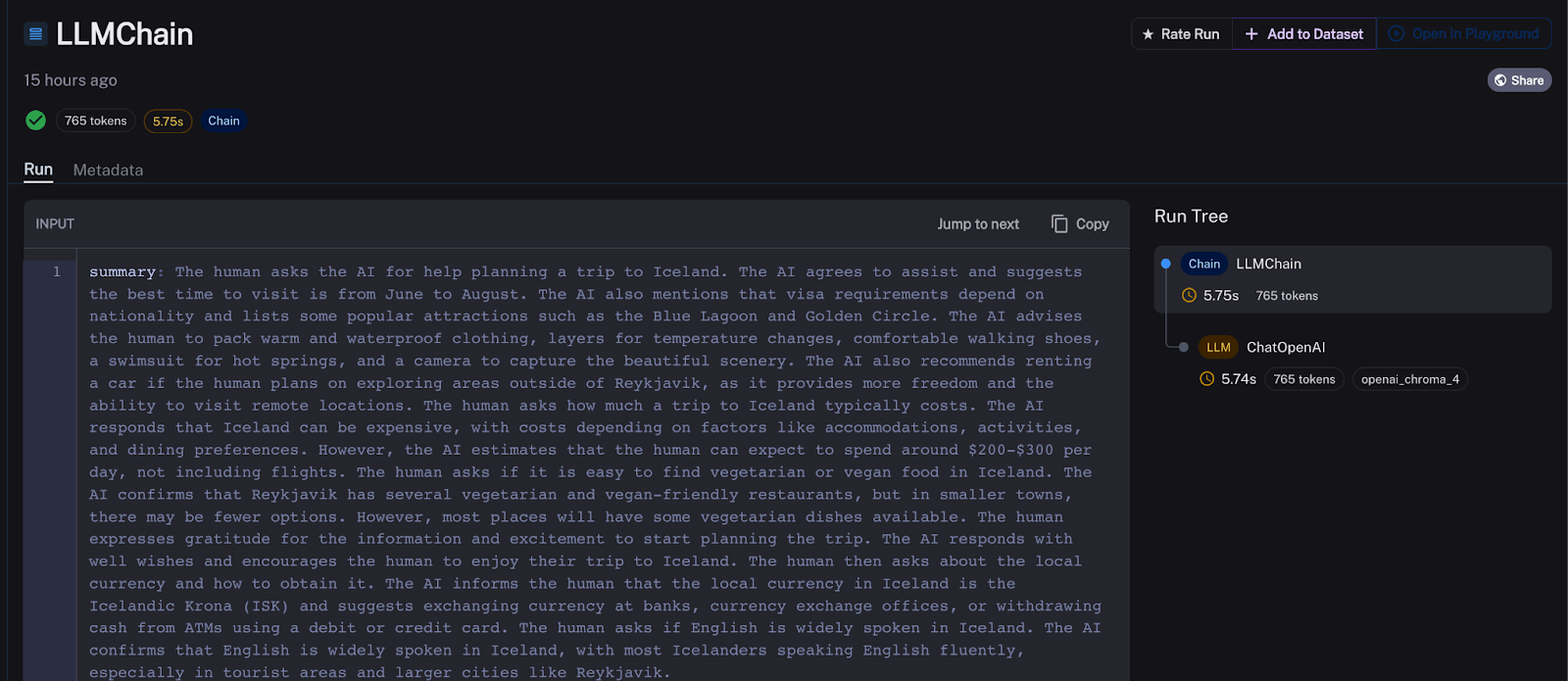
让我们把异常值放在一边,努力理解为什么我们聊天机器人的每个消息轮次都很慢。我注意到我的链响应用户花费的大部分时间是 ConversationSummaryBufferMemory 的摘要链造成的。对于任意选择的响应轮次,摘要几乎占用了 7 秒总响应时间中的 6 秒。而且这种情况在我们聊天机器人每次运行时都会发生。这不好。
使用 Zep 作为替代内存服务
Zep 是一个开源的长期记忆存储,用于持久化、总结、嵌入、索引和丰富 LLM 应用/聊天机器人历史记录。重要的是,Zep 速度很快。摘要、嵌入和消息丰富都在聊天循环之外异步发生。它还支持无状态应用程序架构,因为聊天历史记录不像 ConversationSummaryBufferMemory 和许多其他 LangChain 内存类那样保存在内存中。
Zep 的 ZepMemory 和 ZepRetriever 类在 LangChain 代码库的 Python 和 JS 中发布,并且是 LangChain 本地类的直接替代品。使用 Zep 重新运行实验非常简单。我使用 Zep 的 docker-compose 设置安装了 Zep 服务器,并修改了我的代码。
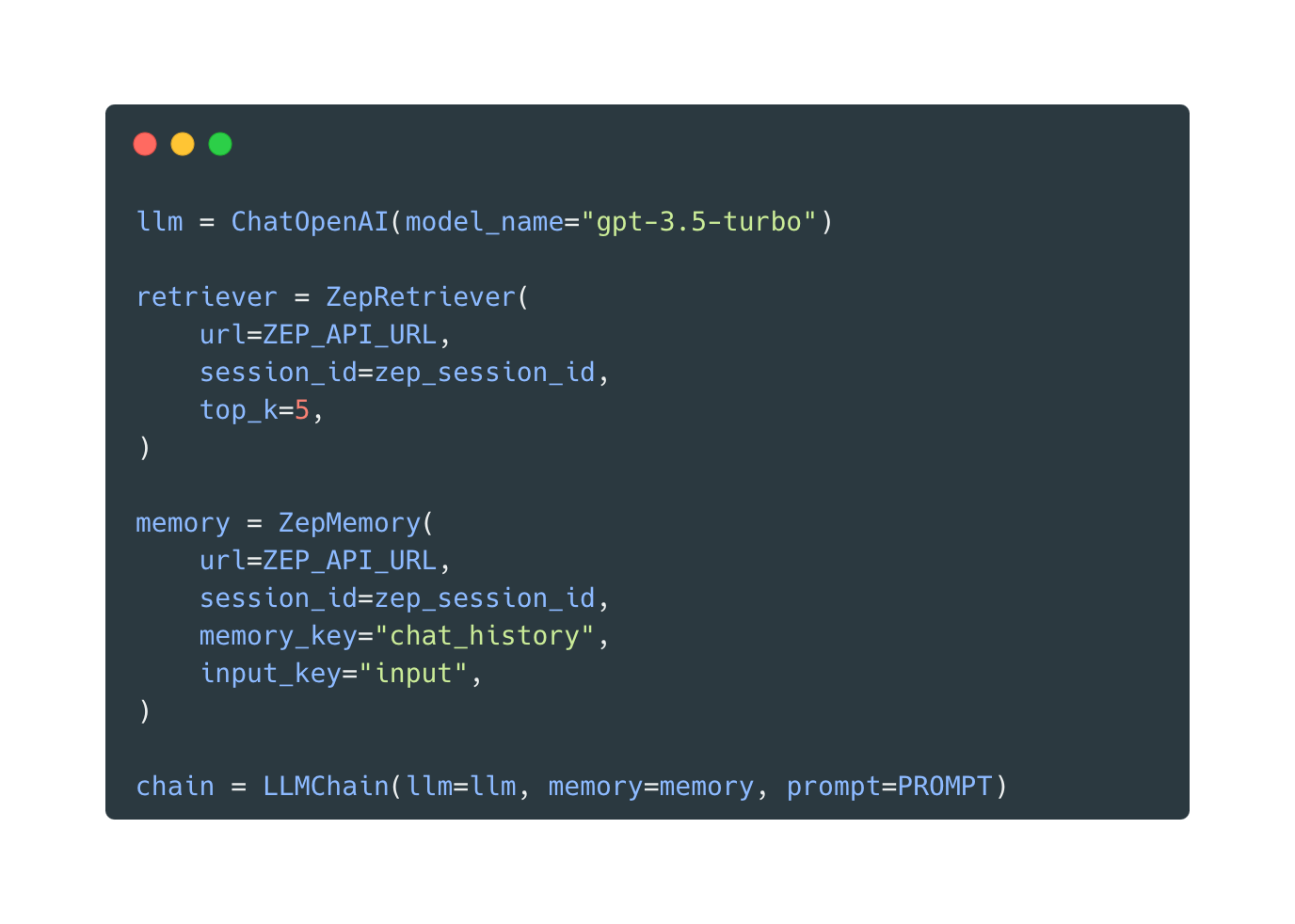
我也不需要使用单独的向量数据库来语义检索历史聊天记忆。Zep 会自动嵌入和索引消息。
LangSmith 中的结果如下所示。每次实验运行的总链运行时降至约 16 秒,几乎完全由 OpenAI API 延迟解释。Zep 在后台生成摘要,这些摘要由 ZepMemory 实例自动添加到我的提示中,以及最新的聊天历史记录。
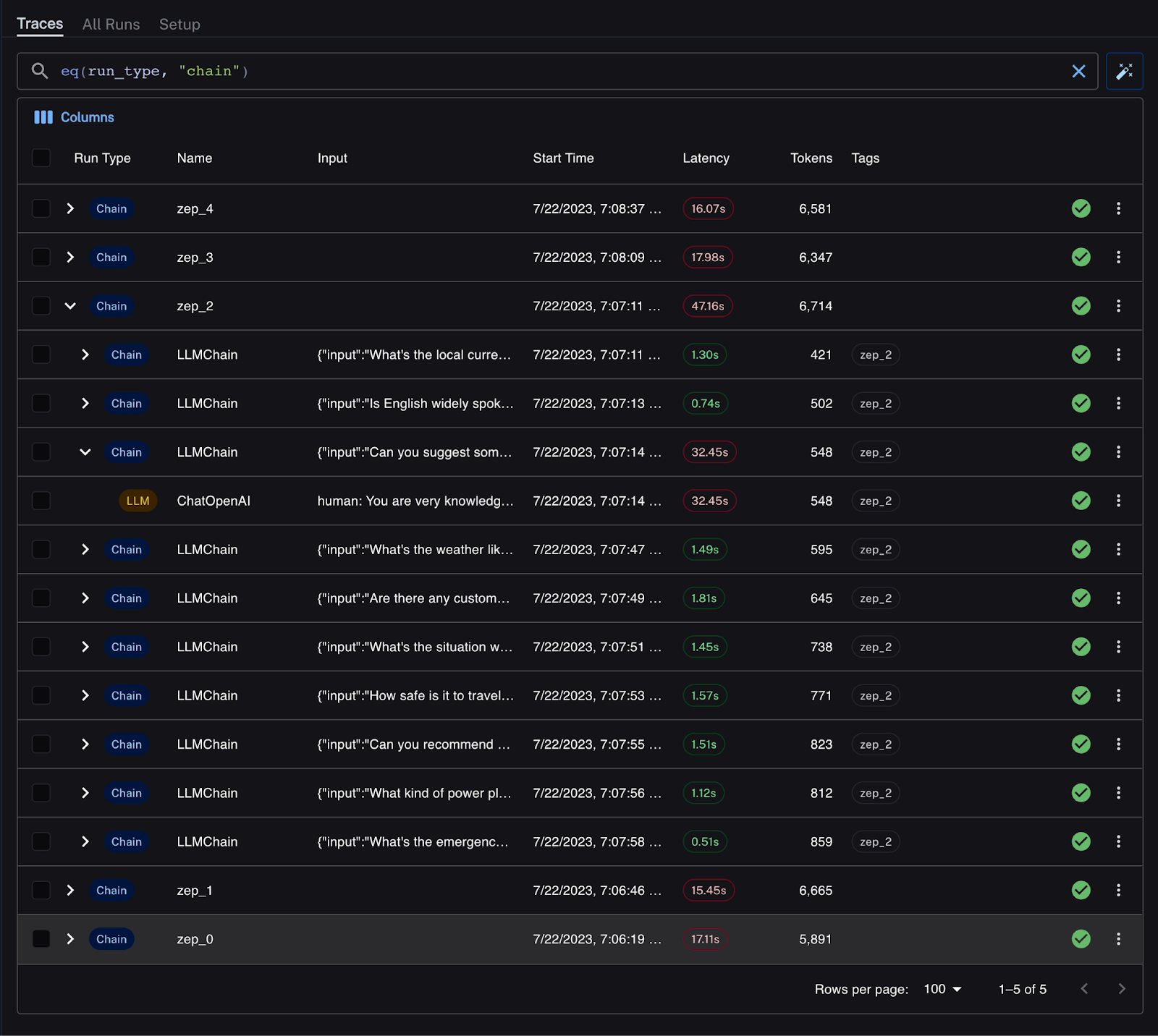
有一个异常值的链运行:OpenAI 的 API 尖峰延迟再次出现!
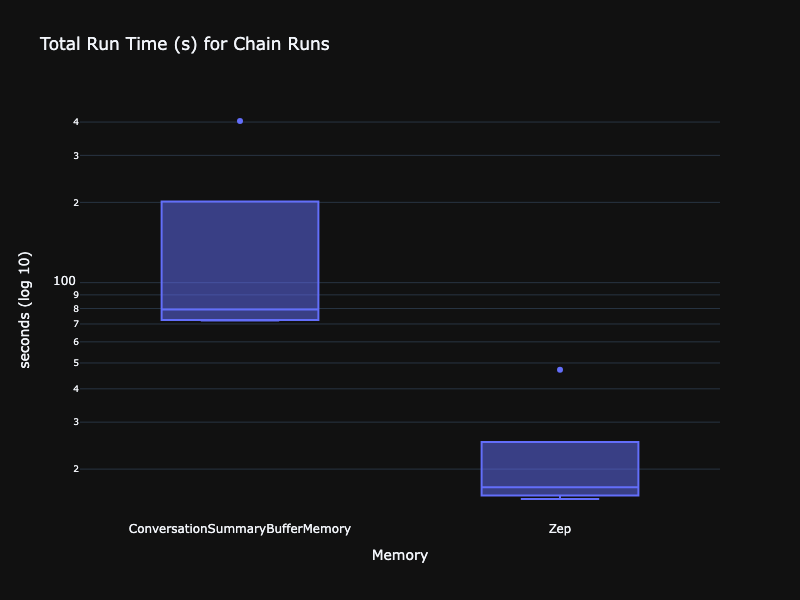
让我们更定量地看一下数据。首先比较每次实验的运行时分布、p95 和 p99。我们进行了 5 次实验,并且使用 ConversationSummaryBufferMemory 和 ZepMemory 对两个链都进行了运行。下图对延迟使用了对数刻度。正如我们在上面看到的,Zep 的运行时低了一个数量级。

为了稳妥起见,我还分析了 VectorStoreRetrieverMemory 对应用程序响应时间的影响,如下所示。
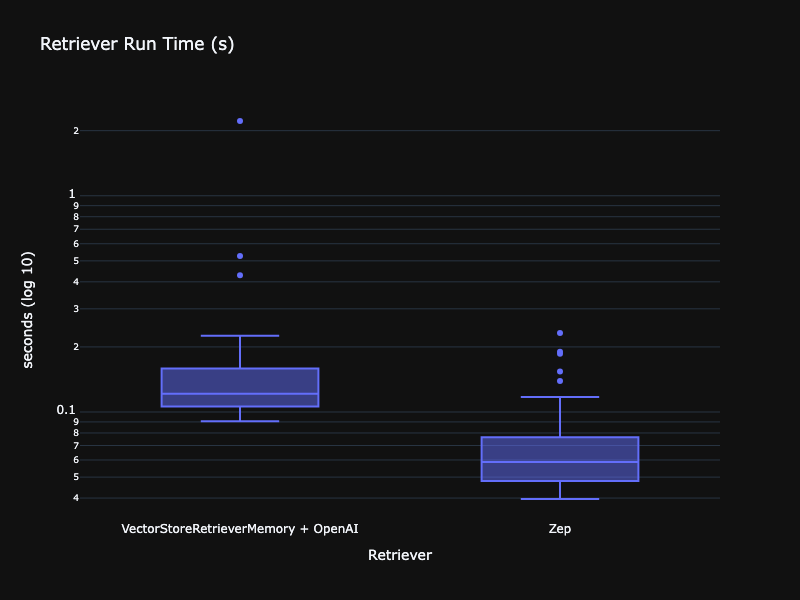
虽然 VectorStoreRetrieverMemory 肯定没有 ConversationSummaryBufferMemory 那么有问题,但 VectorStoreRetrieverMemory 和 OpenAI 用于嵌入仍然比使用 ZepRetriever 慢得多。Zep 可以配置为使用在 Zep 服务中运行的 SentenceTransformer 嵌入模型,这 比调用 OpenAI 嵌入服务提供更低的延迟。
总结
我演示了如何使用新的 LangSmith 服务诊断 LangChain 聊天机器人应用程序延迟问题。这里的罪魁祸首是 ConversationSummaryBufferMemory 实现,我轻松地将其替换为 Zep,从而在延迟方面看到了数量级的改进。LangSmith 是一个出色的平台,不仅可以诊断延迟问题,还可以提供用于测试和评估链的正确性等的工具。
实验设置
我在我的 Apple M1 Pro 14 英寸 16GB RAM 上运行了所有测试。对于 Zep 结果,我运行了标准的 Zep v0.8.1 docker-compose 设置,Docker 配置为 4GB RAM 和 4 个核心。
用于所有测试的 LLM 是 OpenAI 的 gpt-3.5-turbo,对于嵌入,我使用了 OpenAI text-embedding-ada-002 模型。对于软件,我使用了 LangChain 0.0.239、ChromaDB 0.4.2 和 Python 3.11。
所有测试连续运行 5 次。所有运行都从从历史对话创建的新向量 DB 集合或索引开始。运行之间有一个短暂的冷却期。