
了解如何使用 TypeScript、LangChain.js 和 Zep 构建三个基础 LLM 应用。
编者按:这篇文章是与 Zep 团队合作撰写的。 这篇文章逐步介绍了如何使用 TypeScript、LangChain.js 和 Zep 构建三个基础 LLM 应用的过程。我们认为这篇文章对 RAG 和代理访问工具的探索,以及 LangSmith 对模型行为的可视化结合,非常引人注目。而且,我们认为——并希望——更多的开发者将在他们的应用中尝试这些相同的方法!
在 LLM 领域,Python 备受青睐。然而,大多数 Web 应用都是使用 TypeScript、JavaScript 和相关技术构建的。Zep 对 TypeScript 和 JavaScript 提供一流的支持,本文探讨了如何使用 Zep 和 LangChain.js 构建各种类型 LLM 应用的基础。
Zep 的长期记忆存储使开发者可以轻松地将相关文档、聊天记录记忆和丰富的用户数据添加到他们的提示中,而无需管理多个基础设施组件。Zep 还可以自动嵌入聊天记录和文档,减少对第三方嵌入 API 的依赖。
我们将使用的 LangChain 功能概述
我们将构建三种类型应用的基础,所有应用都使用 LangChain 的 ZepMemory 和 ZepVectorStore 类。
- 一个使用
ConversationChain的简单对话机器人。我们将使用它来演示回忆过去对话的能力。 - 一个使用
ConversationalRetrievalQAChain的检索增强生成 (RAG) 应用。我们将演示如何用几本书填充 Zep 的 VectorStore,并向 LLM 询问有关这些书的问题。 - 最后,我们将构建一个 REACT 类型的代理,该代理可以访问两个工具。第一个是
peopleRetriever工具,提供对历史聊天消息的搜索访问,但按人名实体过滤。第二个是bookSearch工具,提供对我们的书籍集合的搜索访问。
我们将使用 LangChain 的新 LangSmith 平台 进行可观测性,从而深入了解我们的链和代理在底层的工作原理。
一个回忆过去对话的简单对话机器人
这个有点简单的例子演示了将历史对话预加载到 Zep 中,并将 ZepMemory 的实例传递给链。
让我们首先在我们的应用中初始化 Zep 并创建一个 sessionId,这是一个代表用户或用户聊天会话的唯一键。然后我们将一些测试数据加载到此会话的聊天记录中。
// Create a new ZepClient instance
const client = await ZepClient.init(ZEP_API_URL, ZEP_API_KEY);
// Create a session ID for our conversation. This ID could represent our user, or a
// conversation thread with a user. i.e. You can map multiple sessions to a single user
// in your data model.
const sessionId = randomUUID();
// add the sample chat history to the Zep memory
const messages = history.map(
({ role, content }: { role: string; content: string }) =>
new Message({ role, content }),
);
const zepMemory = new Memory({ messages });
await client.memory.addMemory(sessionId, zepMemory);
现在让我们为上述会话创建一个初始化的 ZepMemory 实例,并创建我们的链。我们将询问 LLM 我们迄今为止讨论过的内容,让它有机会回顾 Zep 提供的聊天记录。
// Create a new ChatOpenAI model instance. We'll use this for both oru chain and agent.
const model = new ChatOpenAI({
modelName: "gpt-3.5-turbo",
temperature: 0,
});
// Let's create a new ZepMemory instance with very simple configuration.
// We'll use this in our first chain to demonstrate the basics by recalling the
// chat history we've just added to Zep.
const memorySimple = new ZepMemory({
sessionId,
baseURL: ZEP_API_URL,
apiKey: ZEP_API_KEY,
});
// Let's start with a simple chain and ask the LLM what we've discussed so far.
const conversationChain = new ConversationChain({
llm: model,
memory: memorySimple,
});
const res1 = await conversationChain.run("What have we discussed so far?");
console.log(res1);感谢 LangSmith,我们可以看到发送到 LLM 的数据。您将在下面注意到,Zep 已自动总结了冗长的聊天记录,并将其作为系统消息提供给我们的链。Zep 在服务器上异步执行此操作,以避免影响用户体验。
LangSmith 具有共享追踪的巧妙功能,您可以在此处找到此链的追踪。
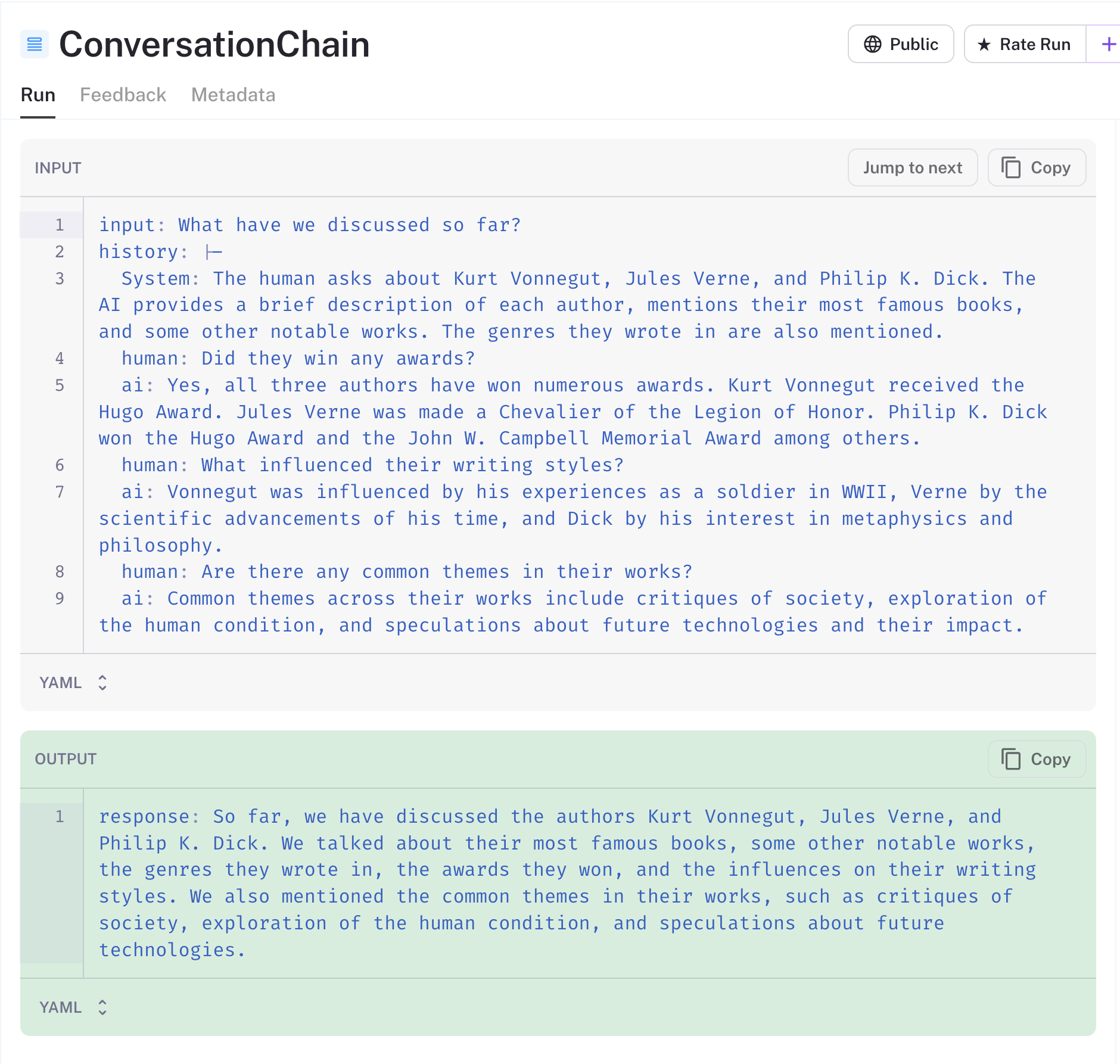
对于对话的每个后续轮次,LangChain 会将 AI 和人类消息持久化到 Zep。这些消息将自动添加到后续的提示中。
除了摘要之外,Zep 还使用命名实体、意图分析和 token 计数来丰富记忆。稍后当我们构建代理时,我们将使用一些这些元数据。
{
"uuid": "d02a90a7-0981-43ae-92bf-95e448f6fff4",
"created_at": "2023-08-17T04:11:43.520994Z",
"role": "AI",
"content": "So far, we have discussed the authors Kurt Vonnegut, Jules Verne, and Philip K. Dick. We talked about their most famous books, some other notable works, the genres they wrote in, the awards they won, and the influences on their writing styles. We also mentioned the common themes in their works, such as critiques of society, exploration of the human condition, and speculations about future technologies.",
"token_count": 88,
"metadata": {
"system": {
"entities": [
{
"Label": "PERSON",
"Matches": [
{
"End": 51,
"Start": 38,
"Text": "Kurt Vonnegut"
}
],
"Name": "Kurt Vonnegut"
},
{
"Label": "PERSON",
"Matches": [
{
"End": 64,
"Start": 53,
"Text": "Jules Verne"
}
],
"Name": "Jules Verne"
},
{
"Label": "PERSON",
"Matches": [
{
"End": 84,
"Start": 70,
"Text": "Philip K. Dick"
}
],
"Name": "Philip K. Dick"
}
]
}
}
}
构建一个基于文档的问答/RAG 类型应用
接下来,我们将使用 Zep 的 VectorStore 来支持 ConversationalRetrievalQAChain 在 Zep 文档集合中搜索。我们下载了三本公共领域的科幻小说,并将使用这些小说进行演示。
我们如何处理分块会显着影响我们应用的性能。由于我们有多本书,并将对每本书进行分块,因此我们在每个块中都包含了文件名作为前缀。这确保了 LLM 可以将块与其来源关联起来。
async function loadDocs(path: string): Promise<Document[]> {
return new DirectoryLoader(path, {
".txt": (path) => new TextLoader(path),
}).load();
}
async function loadDocsIntoVectorStore(
config: IZepConfig,
): Promise<ZepVectorStore> {
const docs = await loadDocs("./books");
console.log(`Loaded ${docs.length} documents`);
// Split the documents into chunks
const splitter = new RecursiveCharacterTextSplitter({
chunkSize: 1000,
chunkOverlap: 200,
separators: ["\n\n", "\n", " ", "", "\r", "\r\n"], // add carriage returns to the list of separators
});
// Split the documents into chunks. We also add the source of the document as a header to each chunk.
const chunks = (
await Promise.all(
docs.map((doc) =>
splitter.splitDocuments([doc], {
chunkHeader: doc.metadata.source
? "SOURCE: " + doc.metadata.source.split("/").pop() + "\n\n"
: "",
appendChunkOverlapHeader: true,
}),
),
)
).flat();
return ZepVectorStore.fromDocuments(chunks, new FakeEmbeddings(), config);
}我们正在创建一个新的 Zep 集合,因此我们传递给 loadDocsIntoStore 函数的配置包括强制性的 embeddingDimensions 和 isAutoEmbedded 字段。第一个字段指定了我们将使用的嵌入模型生成的向量宽度,第二个字段告诉 Zep 是否应该为我们嵌入文档。我们也可以传入嵌入向量。
const config: IZepConfig = {
apiUrl: ZEP_API_URL,
apiKey: ZEP_API_KEY,
collectionName: ZEP_COLLECTION_NAME,
embeddingDimensions: 768, // Set to the width of the model configured in Zep. Use 1536 for OpenAI
isAutoEmbedded: true,
};让我们用文档填充我们的集合,并等待 Zep 嵌入它们。Zep 集合有一个 status 字段,我们可以轮询该字段以确定是否所有现有文档都已嵌入。
// Create a new ZepVectorStore instance and load a document collection into it
const vectorStore = await loadDocsIntoVectorStore(ZEP_COLLECTION_CONFIG);
// Wait for the ZepVectorStore to finish embedding the documents
console.log("Waiting for Zep to finish embedding documents...");
while (true) {
const c = await client.document.getCollection(ZEP_COLLECTION_NAME);
console.log(
`Embedding status: ${c.document_embedded_count}/${c.document_count} documents embedded`,
);
await new Promise((resolve) => setTimeout(resolve, 1000));
if (c.status === "ready") {
break;
}
}接下来,我们将配置我们的记忆和链类,并向 LLM 询问有关书籍的问题。我们使用 memoryKey 和其他字段配置了 ZepMemory。这些需要与链使用的提示对齐,并且取决于链类。
// Let's create a new ZepMemory instance. This will be used to store the current state of the conversation.
// Zep will also auto-summarize and enrich memories for you.
const memory = new ZepMemory({
sessionId,
baseURL: ZEP_API_URL,
apiKey: ZEP_API_KEY,
memoryKey: "chat_history",
inputKey: "question", // The key for the input to the chain
outputKey: "text", // The key for the final conversational output of the chain
});
// Create a new ConversationalRetrievalQAChain instance
// Initialize the chain with the model, the vector store, and the memory
// We'll configure the VectorStore's Retriever to use Maximal Marginal Relevance reranking.
// This will re-rank the search results to ensure that the results are diverse.
const chain = ConversationalRetrievalQAChain.fromLLM(
model,
vectorStore.asRetriever({
searchType: "mmr",
k: 4,
}),
{ memory: memory },
);在上面的代码中,我们将 ZepVectorStore 类作为 LangChain Retriever 传入。在底层,Zep 使用归一化到 [0,1] 的余弦相似度来对搜索结果进行排序。在这里,我们将 Zep 检索器配置为使用最大边际相关性 (MMR) 来重新排序搜索结果以提高多样性。这对于 RAG 应用很有用,但依赖于领域,您应该探索它对您的用例有多大帮助。
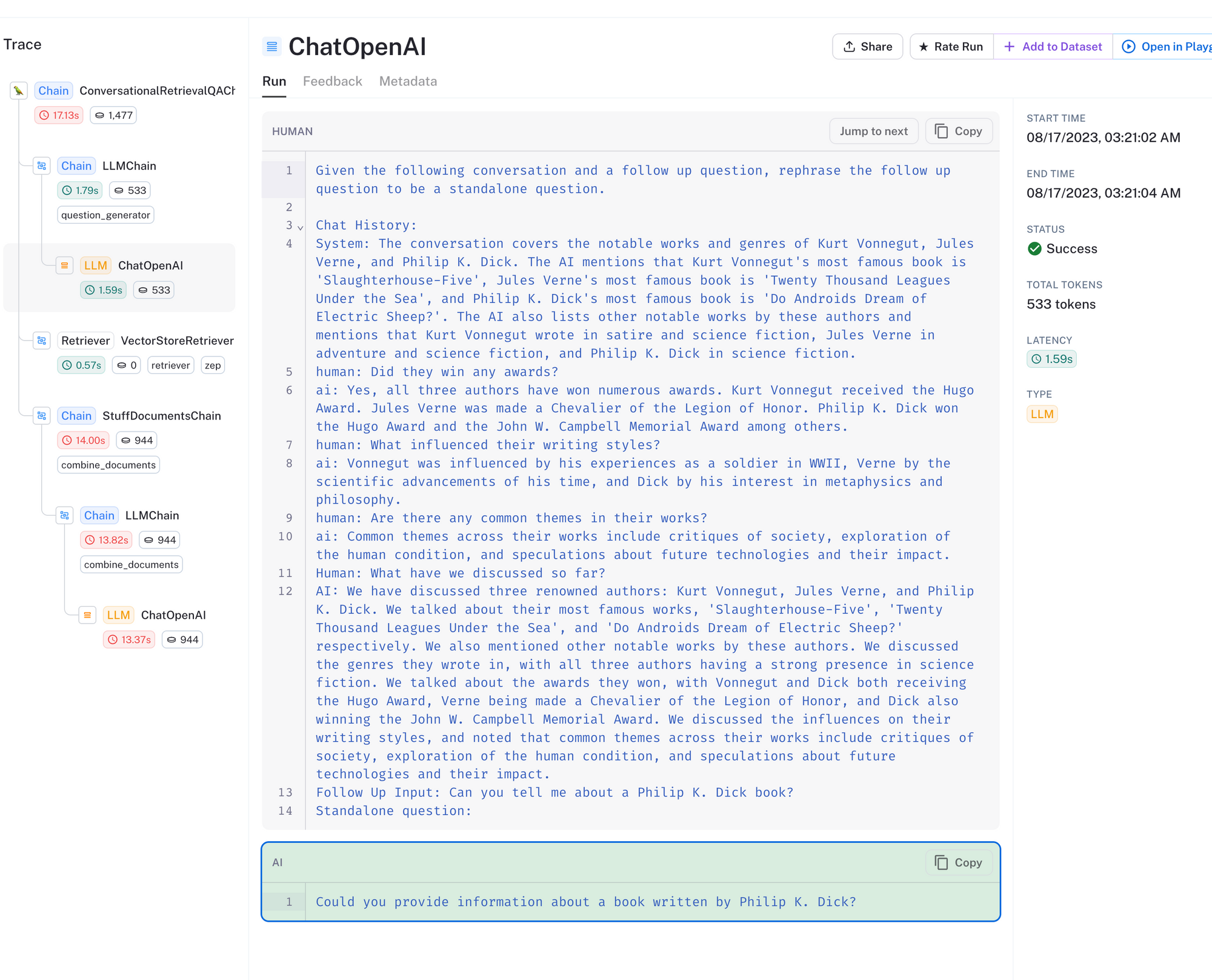
上面是调用链的追踪。对于 ConversationalRetrievalQAChain,会对 LLM 进行多次调用。首先,如上所示,LLM 会收到用户的问题和聊天记录,并被要求根据上下文改写问题。然后,改写后的问题将用于在文档集合中搜索。
当用户的问题本身无法传达足够的上下文来搜索向量数据库时,此方法很有帮助。
我在上面提到过,深思熟虑的分块方法对于我们的应用的工作效果至关重要。数据准备也是如此。在查看向量存储的搜索结果时,我看到第一个结果是古腾堡计划书籍的前言,因为它在向量空间中与我们与书籍相关的查询非常接近。
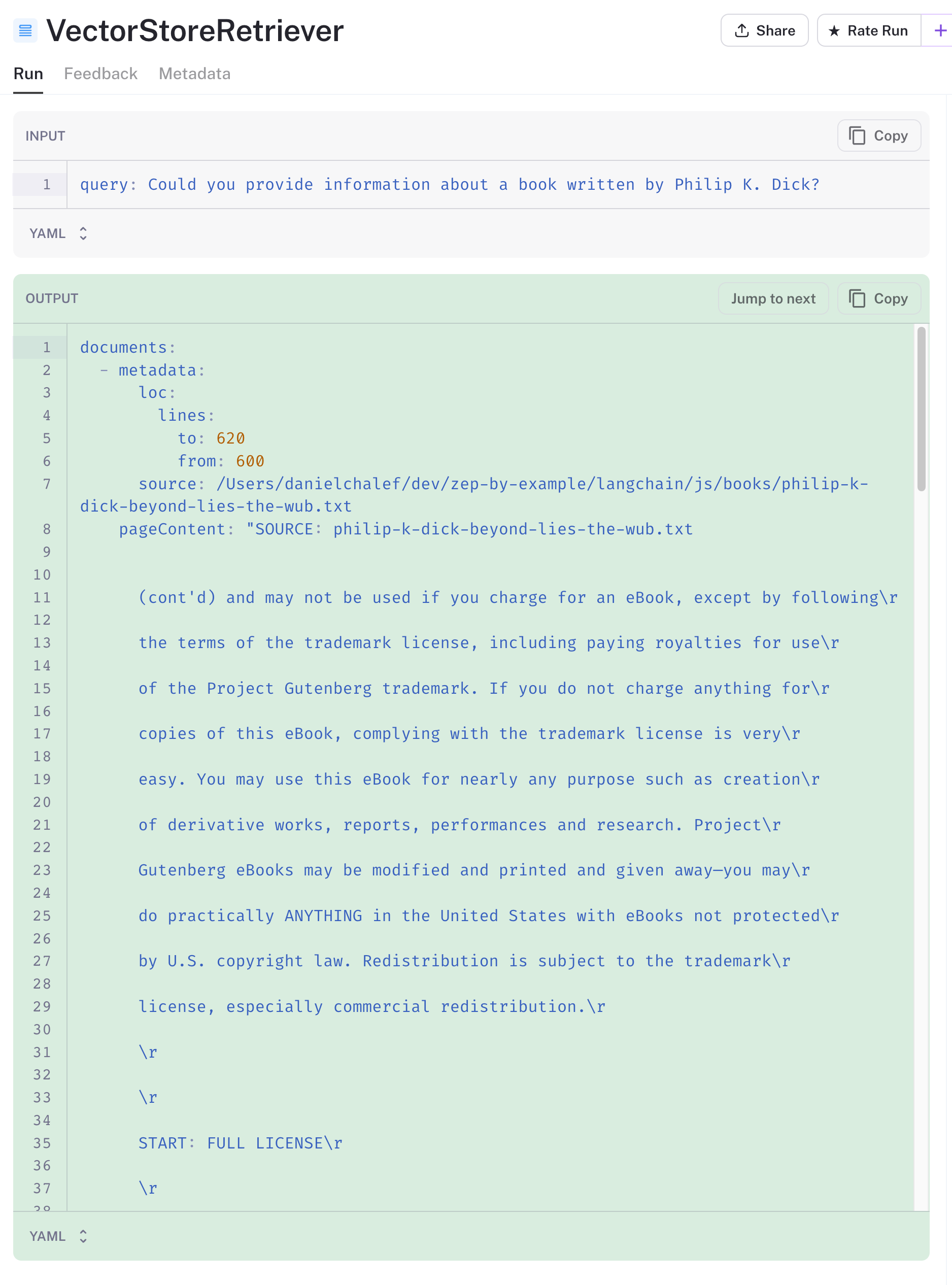
我们可能需要在加载文件并在分块之前删除前言,以改善我们的结果。但是,其他三个结果是相关的。
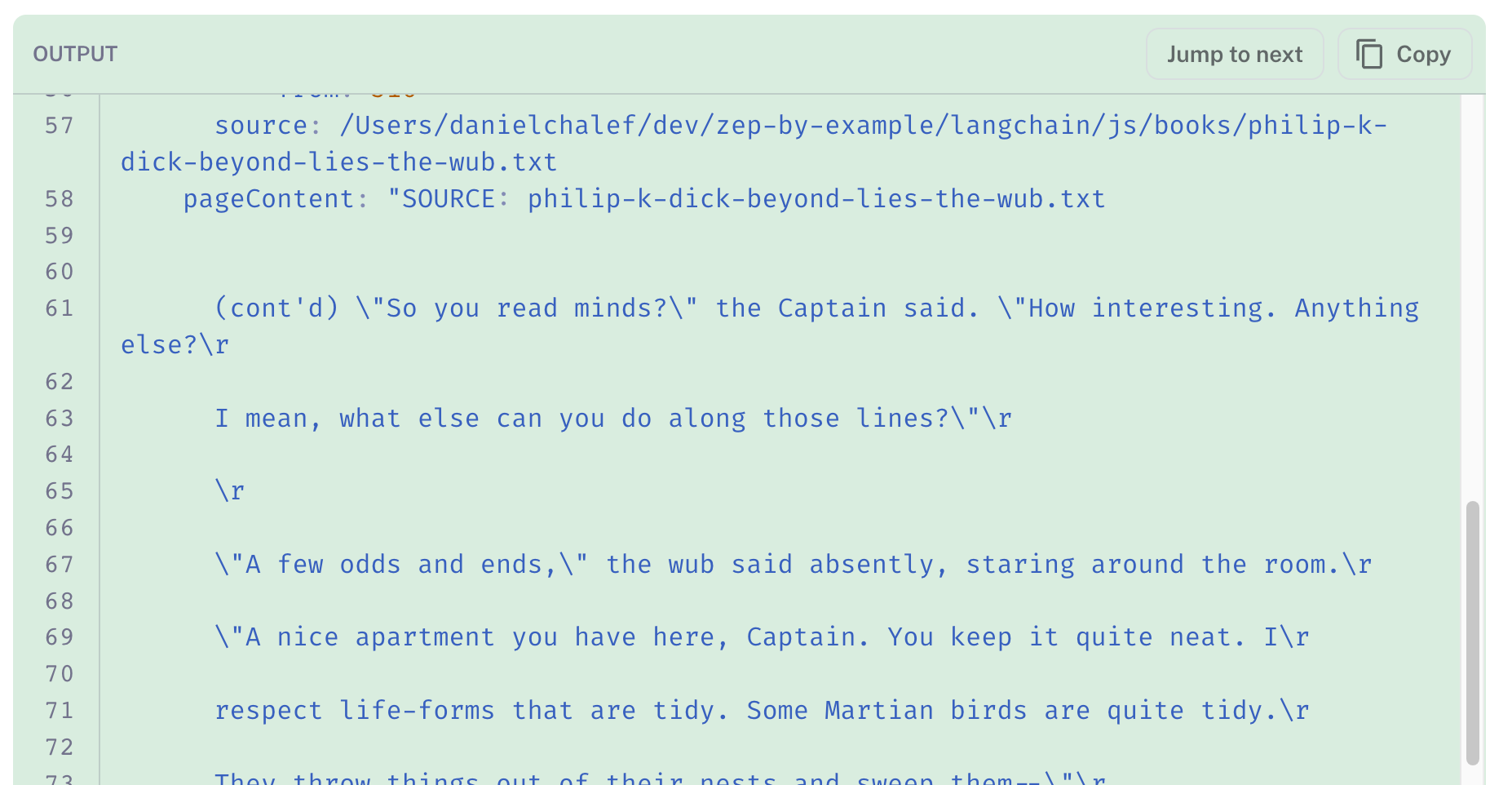
接下来,搜索结果将添加到提示中,以及改写后的问题。LLM 的响应在下面以绿色突出显示。它在理解我们提供给它的文档块方面做得很好。我们添加到每个块的“source”标题确保了返回与 Philip K. Dick 相关的结果。
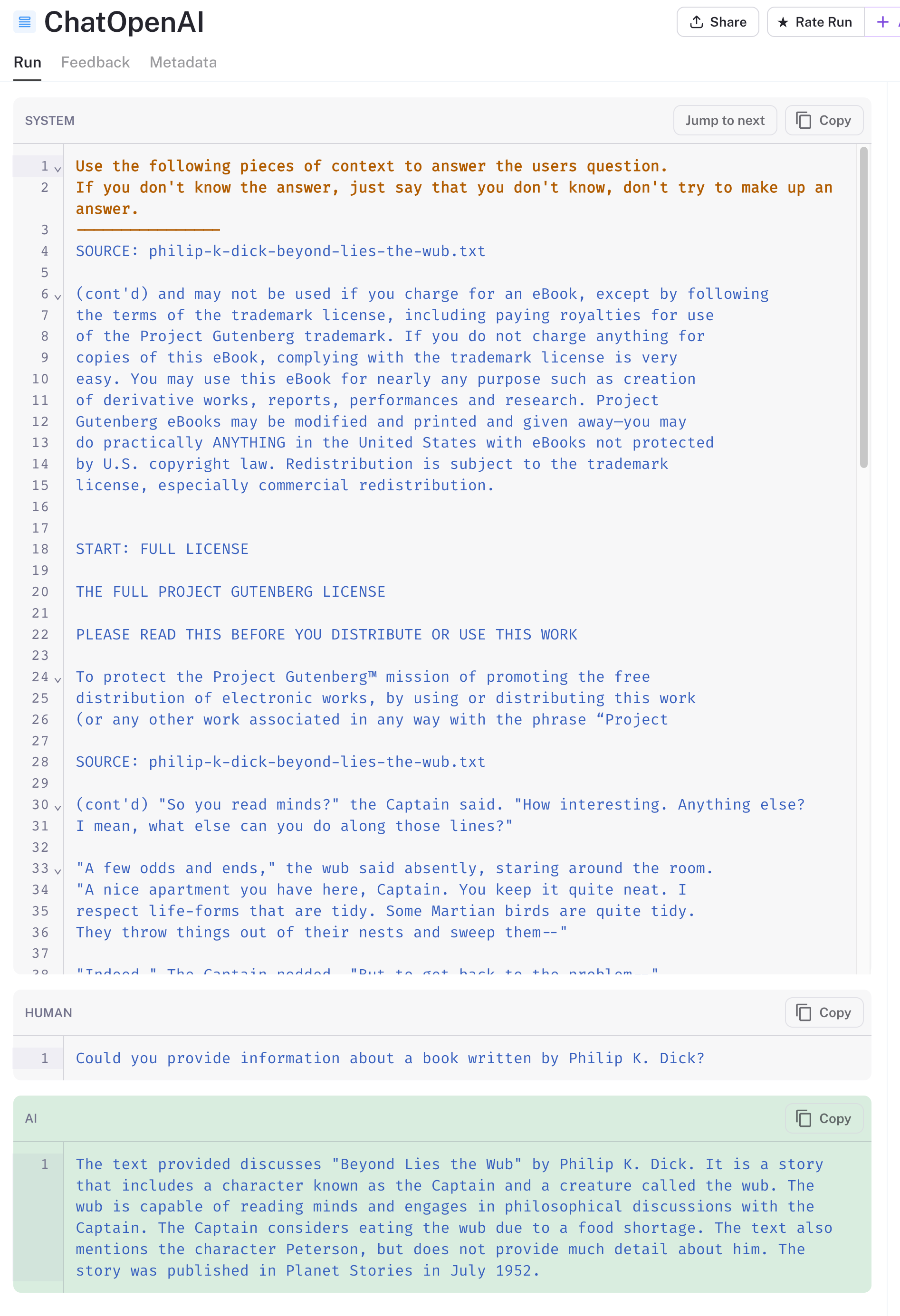
在将搜索结果填充到提示之前,还有其他方法可以总结和优化搜索结果。这些方法确实会增加额外的 LLM 调用成本,因此值得为您的应用探索价值权衡。
构建一个 REACT 类型的代理,将 Zep 记忆检索和搜索作为工具
我们将构建的最后一种类型的应用是一个代理,它使用 Zep 的对话历史记录和向量存储作为工具。我们将在下面快速查看设置,但将花时间在工具本身上。
我们正在使用 initializeAgentExecutorWithOptions 辅助函数来初始化代理,传入我们的工具列表和 LLM。也可以传入 ZepMemory 类,但为了演示的简单性,我们将保持简单。
每个工具都有一个描述,LLM 使用该描述来确定哪个工具最有可能帮助它完成任务。请注意,下面的代理和工具设置相当原始。您可以使用 Zod 和 更复杂的代理使用 Zod 和 OpenAI Functions。
// Let's build an agent!
const zepMemoryRetriever = await new ZepRetriever({
url: ZEP_API_URL,
apiKey: ZEP_API_KEY,
sessionId: sessionId,
});
// Create some tools.
const tools = [
new DynamicTool({
name: "peopleRetriever",
description: `call this if you want to search for authors, characters, or people we may have discussed in the
past. input should be a search string`,
func: async (query) =>
await getPeopleFromMemoryTool(query, zepMemoryRetriever),
}),
new DynamicTool({
name: "bookSearch",
description:
"call this if to search for passages in sci-fi books. input should be a search string",
func: async (query) => await getBookSearchTool(query, vectorStore),
}),
];
const executor = await initializeAgentExecutorWithOptions(tools, model, {
agentType: "zero-shot-react-description",
});Zep 有一个特殊的 LangChain Retriever,恰如其名 ZepRetriever,用于搜索会话的聊天记录。我们在上面的第一个工具 peopleRetriever 中使用了它。正如描述所暗示的那样,此工具搜索历史聊天消息中的人员。该工具还使用 Zep 的实体元数据(针对 PERSON 实体)过滤聊天消息结果。
async function getPeopleFromMemoryTool(
query: string,
retriever: ZepRetriever,
): Promise<string> {
return retriever
.getRelevantDocuments(query, {
metadata: {
where: { jsonpath: '$.system.entities[*] ? (@.Label == "PERSON")' },
},
})
.then((docs) => {
const filteredDocs = docs.filter((doc) => doc.metadata.dist >= 0.8);
return (
filteredDocs.length > 0
? filteredDocs.map((doc) => doc.pageContent)
: ["No results"]
).join("\n\n");
});
}该函数还过滤余弦相似度高于 0.8 的结果,以确保不相关的聊天消息不会返回给 LLM。
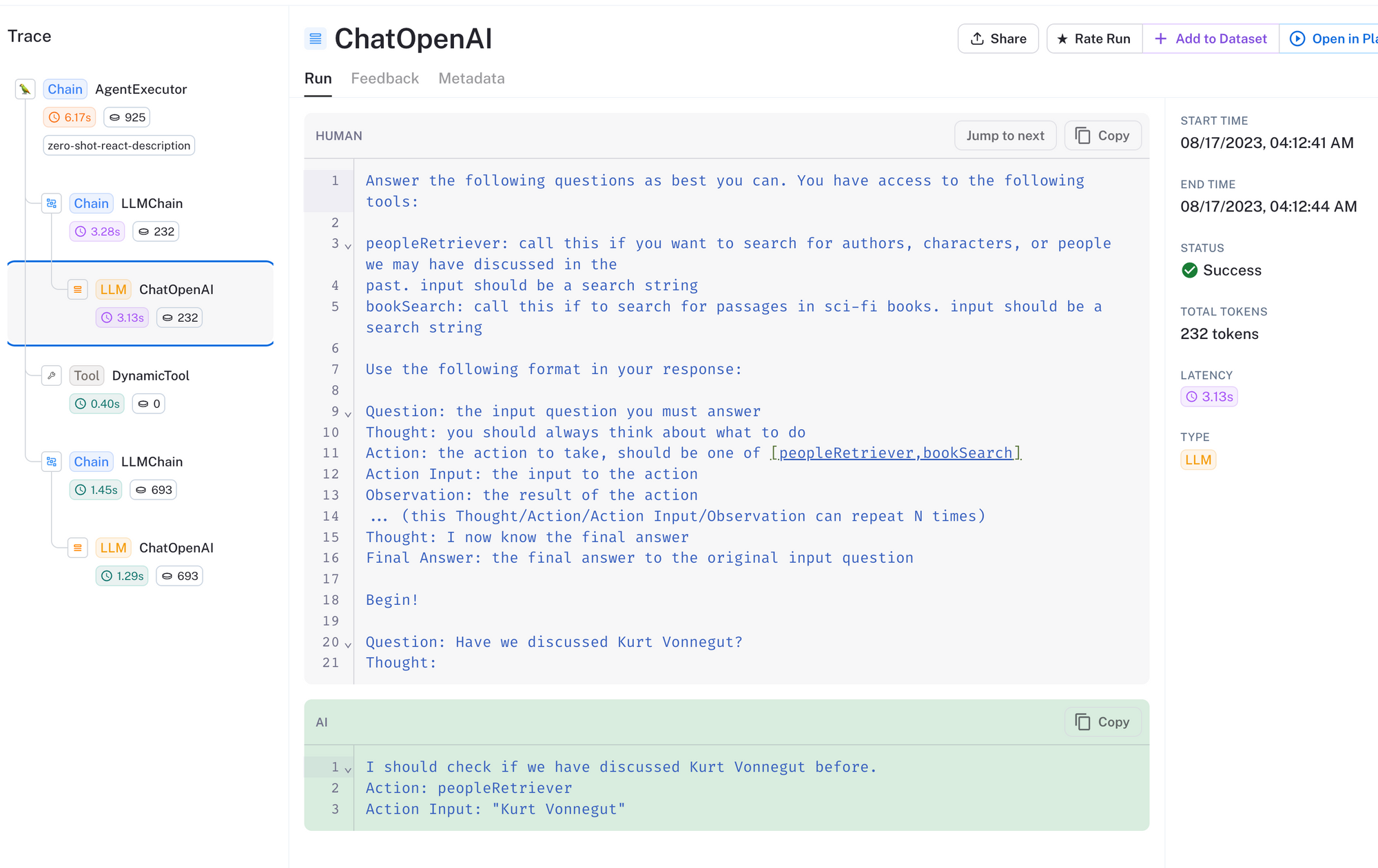
在上面的追踪中,我们可以看到我们询问了代理我们是否之前讨论过 Kurt Vonnegut。代理已正确确定它应该使用 peopleRetriever 工具,输入为 Kurt Vonnegut。
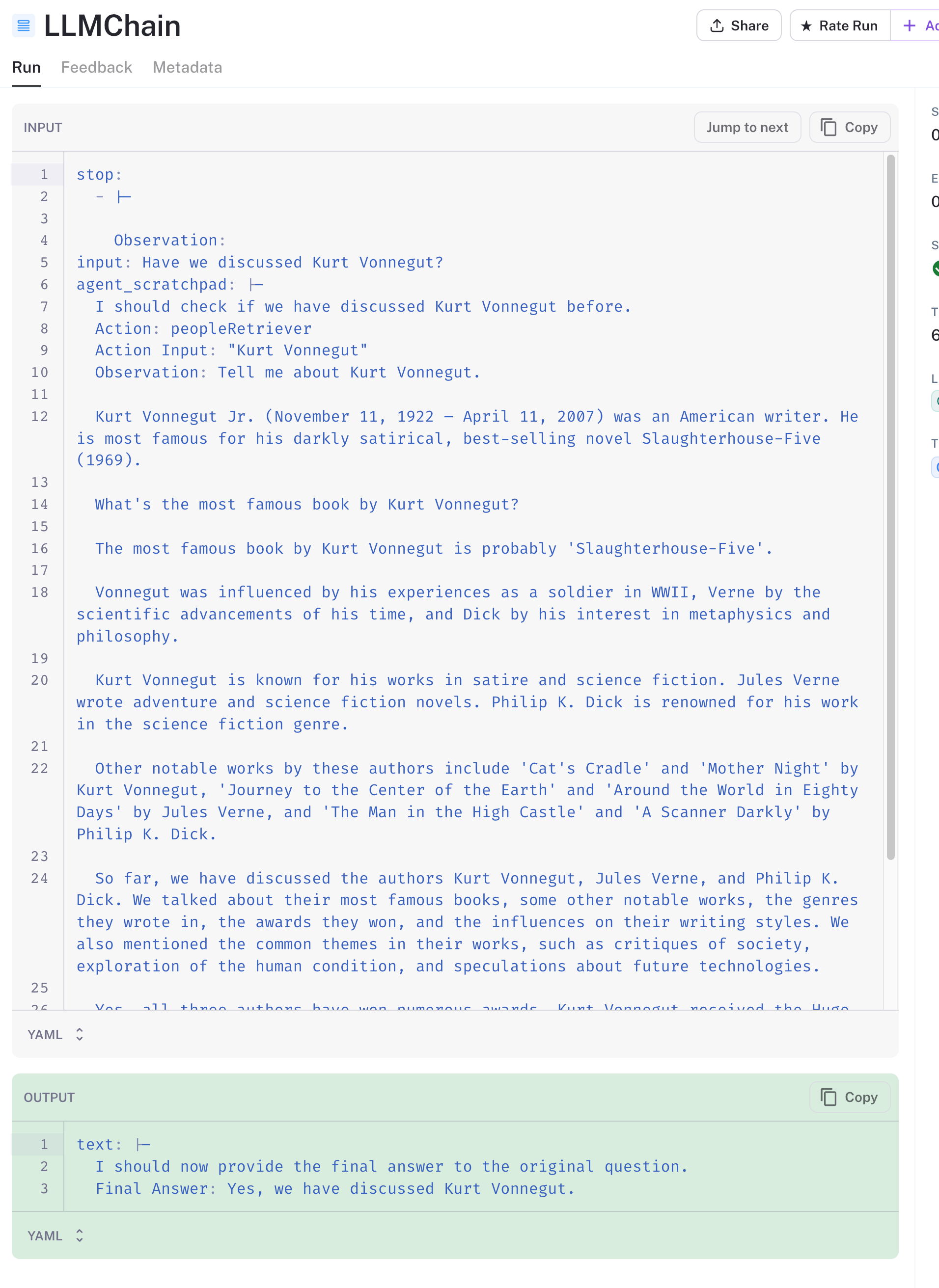
接下来,搜索结果从工具返回,传递给 LLM,并且它已确定我们确实在之前的对话中提到了 Kurt Vonnegut。
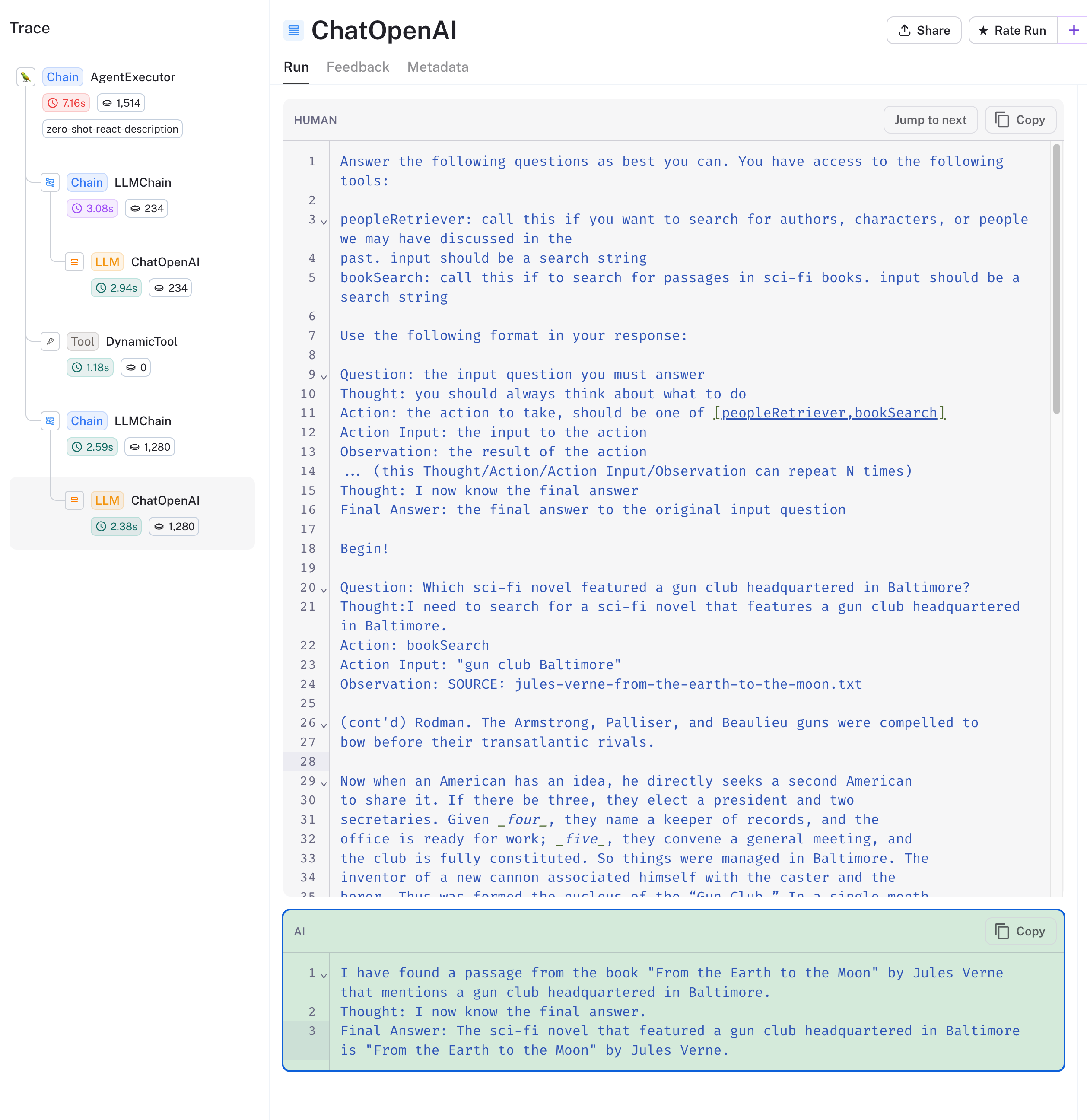
最后,让我们看看代理对 bookSearch 工具的使用。我们向它提出了以下问题:哪部科幻小说以巴尔的摩的枪械俱乐部为特色?
查看 下面的追踪,我们看到代理选择了正确的工具,并在书籍集合中搜索了 gun club Baltimore。向量数据库返回了与查询相关的书籍块,代理回应了儒勒·凡尔纳的《从地球到月球》。
总结
我们探索了如何使用 LangChain.js 和 Zep 构建三种基础 LLM 应用类型,并使用 LangSmith 深入了解了事物的运作方式。
如上所述,我们使用的链、代理和工具相当原始。《LangChain 文档》值得探索,因为您在考虑如何在构建应用时解决不同的问题。当您开始自定义或构建自己的代理和工具时,您将看到 Zep 功能(包括消息元数据)的最大价值。
下一步
- 注册 LangSmith beta 版
- 使用快速入门指南设置 Zep