LangChain 的存在是为了尽可能轻松地开发 LLM 驱动的应用程序。
当我们开始开发时,主要的障碍是构建 LLM 驱动的应用程序,即让一个简单的原型能够工作。我们记得 Nat Friedman 在 2022 年底发推文说“没有足够的尝试”。LangChain 开源软件包旨在解决这个问题,我们现在看到大量的尝试正在发生(Nat 同意)——人们正在构建各种应用,从内部公司文档的聊天机器人到龙与地下城游戏的 AI 地牢管理员。
现在的障碍已经改变。虽然用大约 5 行 LangChain 代码构建应用程序原型很容易,但将应用程序从原型变为生产仍然非常困难。我们今天看到的主要问题是应用程序性能——对于 Twitter 演示来说,大约 30% 的时间可以工作就足够了,但对于生产来说还远远不够。
今天,我们推出 LangSmith,一个旨在帮助开发人员弥合原型和生产之间差距的平台。它专为构建和迭代能够驾驭 LLM 的强大功能并应对其复杂性的产品而设计。
LangSmith 现在处于封闭测试阶段。因此,如果您正在寻找一个强大、统一的系统来调试、测试、评估和监控您的 LLM 应用程序,请在此注册。
我们是如何走到这一步的?
鉴于 LLM 的随机性,回答“这些模型中发生了什么?”这个简单的问题并不容易——而且目前还没有直接的方法——更不用说让它们可靠地工作了。我们听到的构建者遇到了同样的障碍(我们的团队也是如此)
- 了解最终发送给 LLM 调用的提示到底是什么(在所有提示模板格式化之后,最终提示可能很长且难以理解)
- 了解在每个步骤中从 LLM 调用返回的具体内容(在以任何方式进行后处理或转换之前)
- 了解对 LLM(或其他资源)的确切调用序列,以及它们是如何链接在一起的
- 跟踪令牌使用情况
- 管理成本
- 跟踪(和调试)延迟
- 没有好的数据集来评估他们的应用程序
- 没有好的指标来评估他们的应用程序
- 了解用户如何与产品互动
所有这些问题在传统软件工程中都有相似之处。并且,作为回应,出现了一套用于调试、测试、日志记录、监控等的实践和工具,以帮助开发人员抽象出常见的基础设施,并专注于真正重要的事情——构建他们的应用程序。LLM 应用程序开发人员也应该得到同样的待遇。
LangSmith 渴望成为那样的平台。在过去的几个月中,我们一直在与一些早期的设计合作伙伴直接合作,并在我们自己的内部工作流程中对其进行测试,我们发现 LangSmith 在 5 个核心方面帮助了团队
调试
LangSmith 使您可以完全了解事件链中每个步骤的模型输入和输出。这使团队可以轻松地试验新的链和提示模板,并找出意外结果、错误或延迟问题的来源。我们还将公开延迟和令牌使用情况,以便您可以识别哪些调用导致了问题。
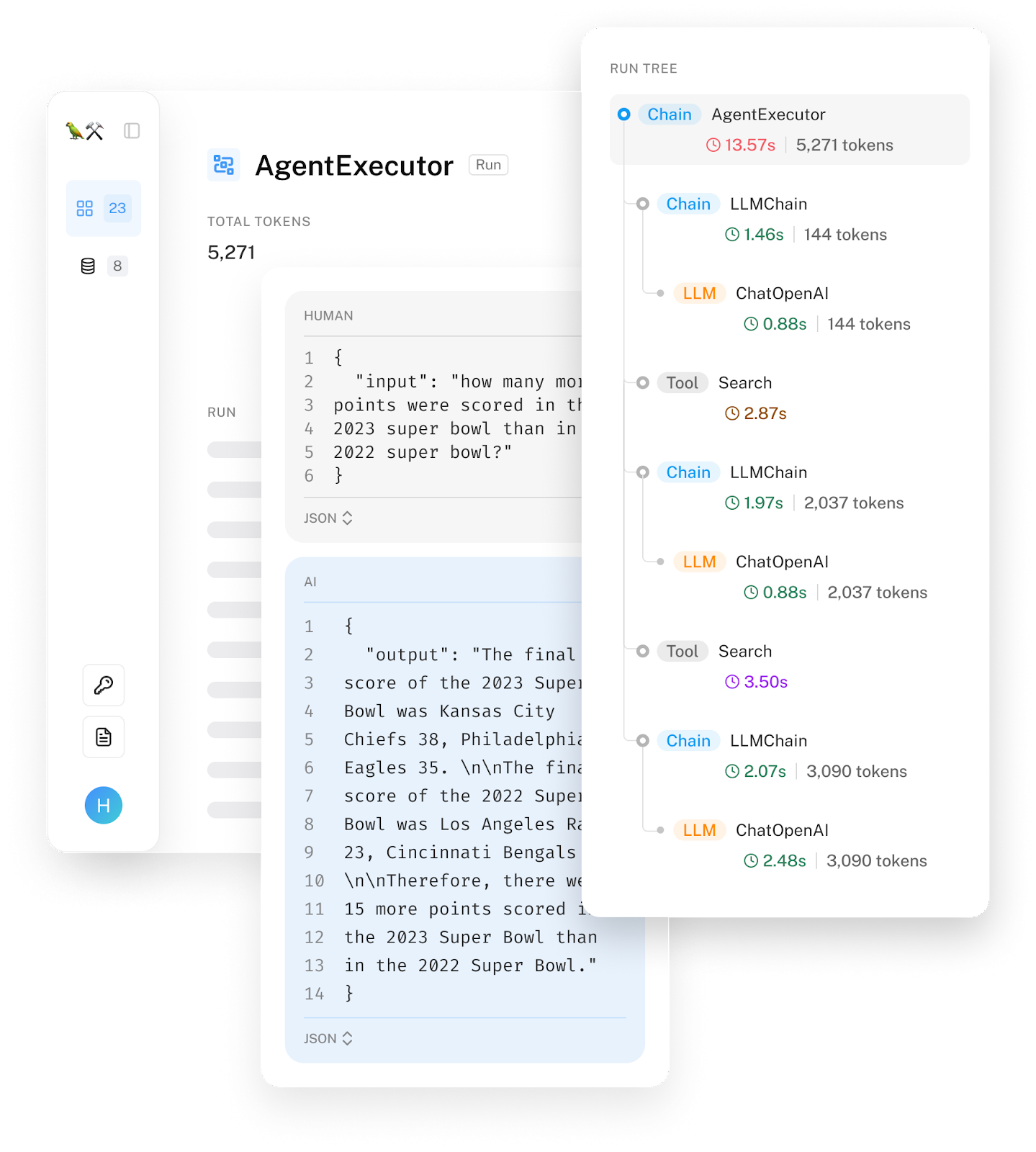
我们还简化了从 UI 更改和重新运行示例的过程。我们在看到团队获取错误示例的日志并复制粘贴到 OpenAI Playground 中以调整提示直到获得良好结果后,添加了此功能。我们希望消除这种摩擦,现在只需单击一个按钮,您就可以从日志转到 Playground,您可以在其中主动编辑。目前 OpenAI 和 Anthropic 模型都支持此功能,并且即将支持更多模型。我们还在努力为通用链提供支持。
这种对模型性能的深入可见性对于开发复杂应用程序的团队特别有帮助。LangSmith 帮助 Streamlit 和 Snowflake 实现了可以智能且可靠地回答有关其数据的代理。
“LangChain 在帮助我们在 Snowflake 原型设计智能代理方面发挥了重要作用,”Snowflake 产品总监 Adrien Treuille 说。“LangSmith 易于集成,并且不可知的开源 API 使其非常灵活,可以适应我们的实施,”Snowflake 高级软件工程师 Richard Meng 补充道。
波士顿咨询集团 还通过依赖相同的基础设施,在 LangChain 框架之上构建了一系列高度定制且高性能的应用程序。
“我们很自豪成为 LangChain 的早期设计合作伙伴和 LangSmith 的用户之一,”BCG 董事总经理兼合伙人 Dan Sack 说。“LangSmith 的使用是为我们的客户带来生产就绪的 LLM 应用程序的关键。LangSmith 易于集成且直观的 UI 使我们能够非常快速地启动并运行评估管道。此外,跟踪和评估复杂的代理提示链变得更加容易,减少了调试和优化提示所需的时间,并使我们有信心进行部署。”
在另一个调试的实际例子中,我们与 DeepLearningAI 合作,为 最近发布的 LangChain 课程 中的学习者提供 LangSmith 的访问权限。这使学生可以轻松地精确地可视化调用的确切顺序,以及链中每个步骤的输入和输出。学生可以准确地了解链、提示和 LLM 正在做什么,这有助于在他们学习创建新的和更复杂的应用程序时建立直觉。
测试
我们看到开发人员努力解决的主要问题之一是:“如果我更改此链/提示,那会对我的输出产生什么影响?” 回答这个问题最有效的方法是整理您关心的示例数据集,然后在该数据集上运行任何已更改的提示/链。LangSmith 首先可以轻松地从跟踪或通过上传您手动整理的数据集来创建这些数据集。然后,您可以轻松地在这些数据集上运行链和提示。
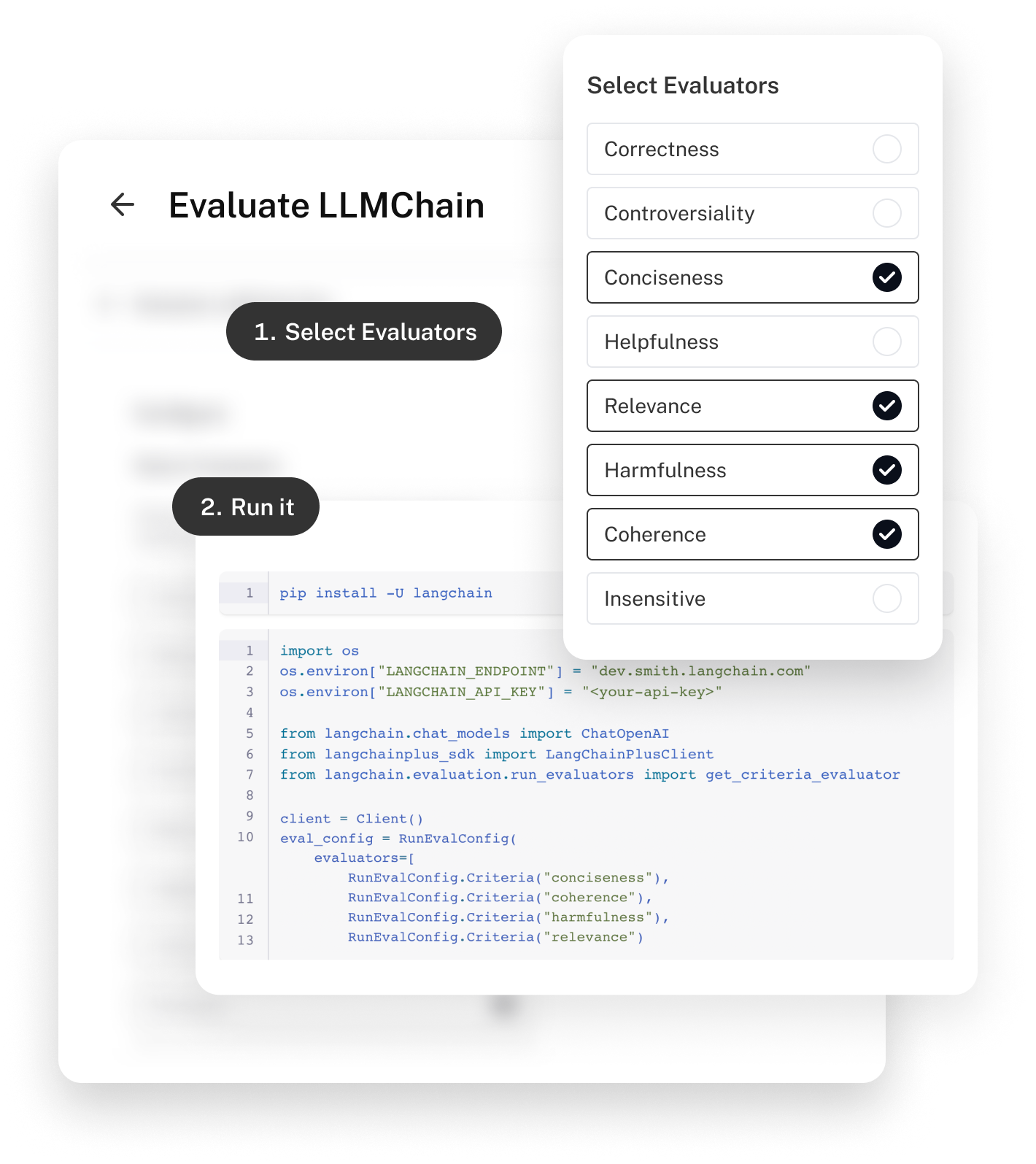
第一个有用的步骤是简单地手动查看新的输入和输出。虽然这看起来可能令人不满意的基本,但实际上有一些好处——我们与之交谈过的许多公司实际上喜欢一些手动接触点,因为它使他们能够更好地了解如何与 LLM 互动。当试图思考如何改进应用程序时,这种直觉可以被证明是非常有价值的。我们希望提供的主要解锁是一个清晰的界面,让开发人员可以轻松地查看每个数据点的输入和输出,因为如果没有这种可见性,他们就无法建立起这种直觉。
今天,我们主要听到希望将其原型投入生产的团队的声音,并且正在缩小他们想要改进的特定提示的范围。Klarna 正在构建行业领先的 AI 集成,这些集成超越了对语言模型的简单调用,而是依赖于一系列调用。当他们专注于特定部分时,LangSmith 提供了他们需要的工具和数据,以确保不会发生回归。
与此同时,我们开始听到越来越多雄心勃勃的团队的声音,他们正在努力寻求更有效的方法。
评估
LangSmith 与我们的开源评估模块集合无缝集成。这些模块有两种主要的评估类型:启发式和 LLM。启发式评估将使用诸如正则表达式之类的逻辑来评估答案的正确性。LLM 评估将使用 LLM 来评估自身。
从长远来看,我们非常看好 LLM 辅助评估。这种方法的批评者会说,它在概念上站不住脚,而且在实践上成本很高(时间和金钱)。但是,我们一直在看到来自顶级实验室的一些 非常引人注目的证据 表明这是一种可行的策略。并且,随着我们共同改进这些模型——包括私有和开源模型——并且使用变得更加普遍,我们预计成本会大幅下降。
监控
虽然调试、测试和评估可以帮助您从原型到生产,但工作不会在您发布后停止。开发人员需要积极跟踪性能,理想情况下,根据反馈优化性能。我们经常看到开发人员依靠 LangSmith 来跟踪其应用程序的系统级性能(如延迟和成本),跟踪模型/链性能(通过将反馈与运行相关联),调试问题(深入研究特定的错误运行),并广泛了解用户如何与他们的应用程序互动以及他们的体验如何。
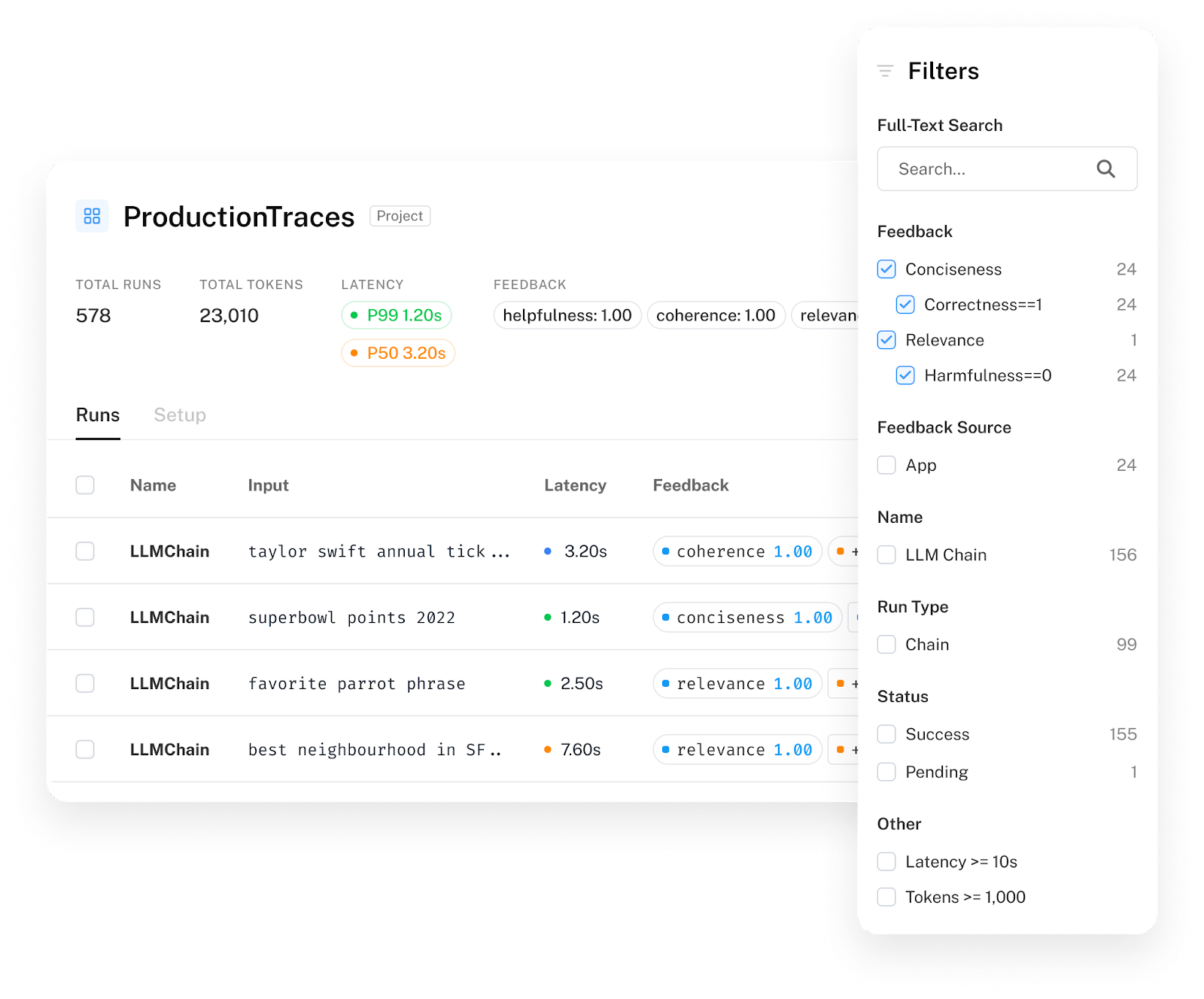
像 Mendable、Multi-On 和 Quivr 这样雄心勃勃的初创公司,他们已经为成千上万的用户提供服务,并且正在积极使用 LangSmith,不仅可以监控总体使用情况,还可以利用这些见解来处理关键问题。
“感谢 Langchain Smith,我们能够分析我们的 LLM 调用,了解不同链方法(stuff vs reduce)在 QA 中的性能并加以改进。它甚至帮助我们调试和理解我们犯的错误。我们一直在使用它来改进我们的提示工程,并期待新功能,”Theodo 的 GenAI 负责人兼 Quivr 的创建者 Stan Girard 说。
一个统一的平台
虽然这些产品领域中的每一个都在开发过程中的特定时间点提供了独特的价值,但我们认为 LangSmith 的长期影响很大一部分将来自拥有一个单一的、完全集成的中心来完成这项工作。我们看到团队使用各种类似鲁布·戈德堡机械的流程来管理他们的 LLM 应用程序,我们希望让这种情况成为过去。
作为一个非常简单的例子,我们认为 LangSmith 的基本要求是帮助用户轻松地从现有日志创建数据集,并立即将其用于测试和评估,从而无缝地将日志记录/调试工作流程连接到测试/评估工作流程。
Fintual 是一家拉丁美洲初创公司,怀揣着通过个性化财务顾问帮助其公民积累财富的远大梦想,他们在 LLM 开发的早期就发现了 LangSmith。“当我们一听到 LangSmith 的消息,我们就将整个开发堆栈转移到了它上面。我们可以内部构建我们需要的评估、测试和监控工具。但这会糟糕 1000 倍,花费我们 10 倍的时间,并且需要 2 倍规模的团队,”Fintual 负责人 Jose Pena 说。
“因为我们正在构建金融产品,所以对准确性、个性化和安全性的要求特别高。LangSmith 帮助我们构建出我们有信心交付给用户的产品。”
我们迫不及待地想将这些好处带给更多团队。我们还有很长的功能路线图,例如分析、Playground、协作、情境学习、提示创建等等。
最后,我们认识到我们无法构建您今天使您的应用程序准备好投入生产所需的所有功能。我们已经可以导出 OpenAI evals 期望格式的数据集,以便您可以在那里贡献它们。这些数据也可以直接用于在 Fireworks 平台 上微调您的模型(我们的目标是使其易于插入其他微调系统)。最后,我们已将日志导出为通用格式,并与 Context 等团队合作,以确保您可以将它们加载到他们的分析引擎中并在其中运行分析。
我们迫不及待地想看看您构建什么。