背景
在他们的演示日上,OpenAI 报告了他们与一位客户合作进行的一系列 RAG 实验。虽然评估指标将取决于您的具体应用,但了解哪些方法有效,哪些方法无效是很有意思的。下面,我们详细介绍每种提及的方法,并展示如何为您自己实施每种方法。理解并在您的应用程序上运用这些方法的能力至关重要:通过与许多合作伙伴和用户的交流,我们发现没有“一刀切”的解决方案,因为不同的问题需要不同的检索技术。
这些方法如何融入 RAG 堆栈
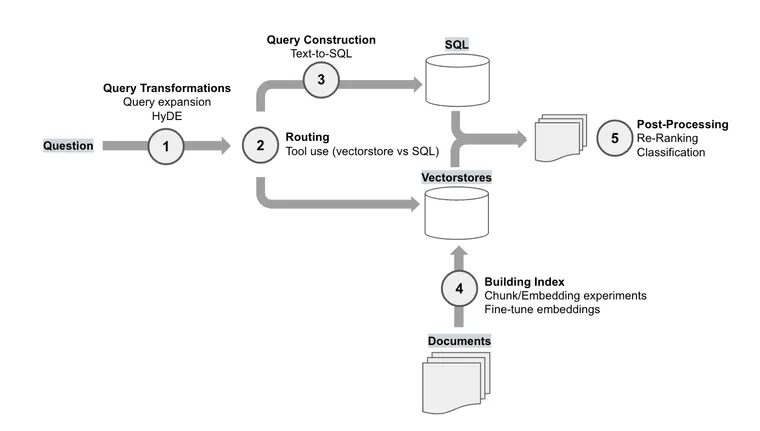
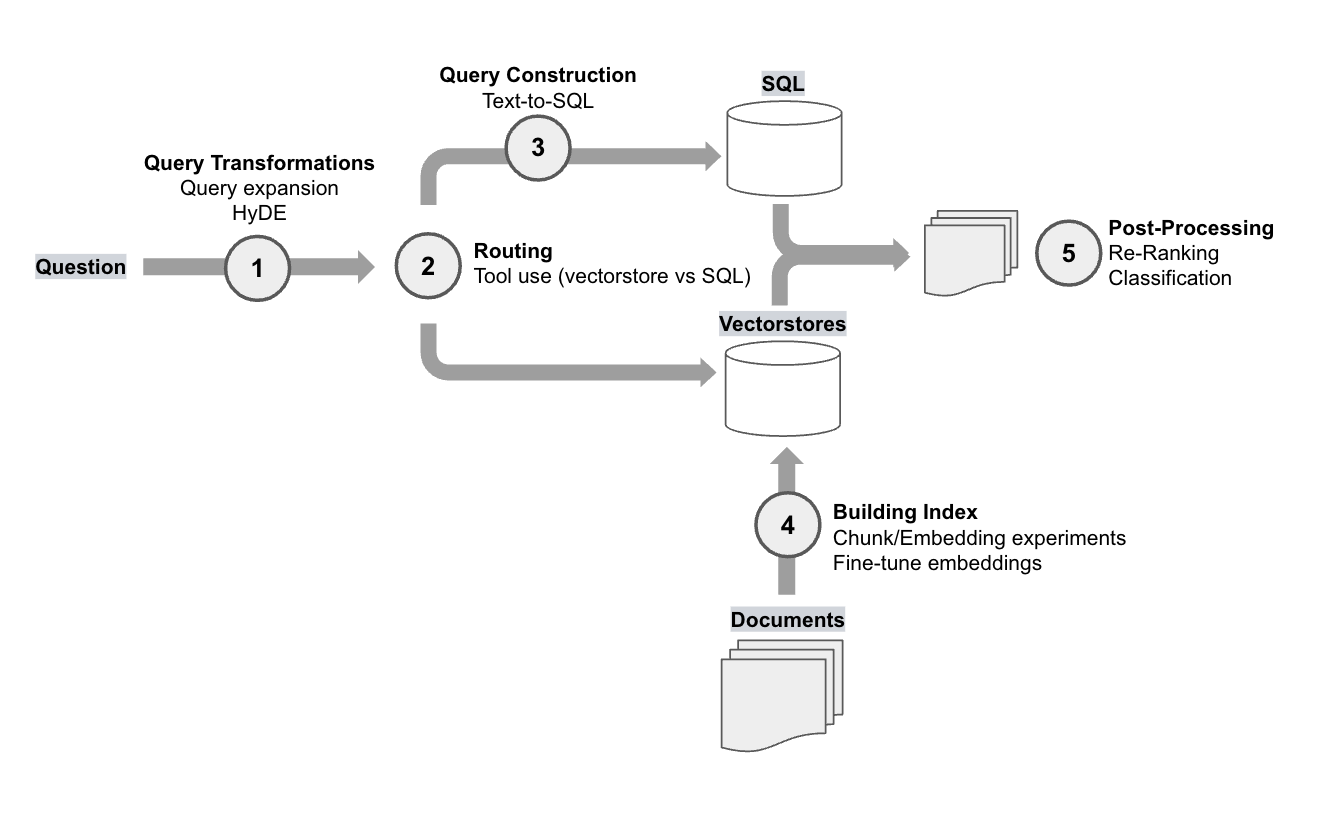
首先,我们可以将这些方法归类为几个 RAG 类别。下图显示了每个 RAG 实验及其类别,并将它们放置在 RAG 堆栈中
基线
基于距离的向量数据库检索将查询嵌入(表示)在高维空间中,并根据“距离”查找相似的嵌入文档。OpenAI 研究中使用的基本案例检索方法是余弦相似度。LangChain 拥有 超过 60 个 向量存储集成,其中许多允许配置相似性搜索中使用的距离函数。关于各种距离指标的有用博客文章可以在 Weaviate 和 Pinecone 中找到。
查询转换
然而,由于查询措辞的细微变化,或者如果嵌入未能很好地捕捉数据的语义,检索可能会产生不同的结果。查询转换是一组专注于修改用户输入以改进检索的方法。 请参阅我们最近关于该主题的博客 此处。
OpenAI 报告了两种方法,您可以尝试一下:
- 查询扩展:LangChain 的 多查询检索器 使用 LLM 从不同角度为给定的用户输入查询生成多个查询,从而实现查询扩展。对于每个查询,它检索一组相关文档,并取所有查询的唯一并集。
- HyDE:LangChain 的 HyDE (假设文档嵌入) 检索器为传入的查询生成假设文档,嵌入它们,并在检索中使用它们(参见 论文)。其思想是,这些模拟文档可能比问题与所需的源文档具有更高的相似性。
其他值得考虑的想法:
- 回溯提示:对于推理任务,这篇 论文 表明,可以使用回溯问题将答案合成扎根于更高层次的概念或原则中。例如,关于物理学的问题可以抽象为关于用户查询背后物理原理的问题和答案。最终答案可以从输入问题以及回溯答案中得出。 请参阅这篇 博客文章 和 LangChain 实现 以了解更多信息。
- 重写-检索-阅读:这篇 论文 重写用户问题以改进检索。 请参阅 LangChain 实现 以了解更多信息。
路由
当跨多个数据存储进行查询时,将问题路由到适当的来源变得至关重要。OpenAI 的演示报告称,他们需要在两个向量存储和一个 SQL 数据库之间路由问题。LangChain 支持路由,使用 LLM 将用户输入门控到一组定义的子链中,就像本例中一样,这些子链可以是不同的向量存储。
查询构建
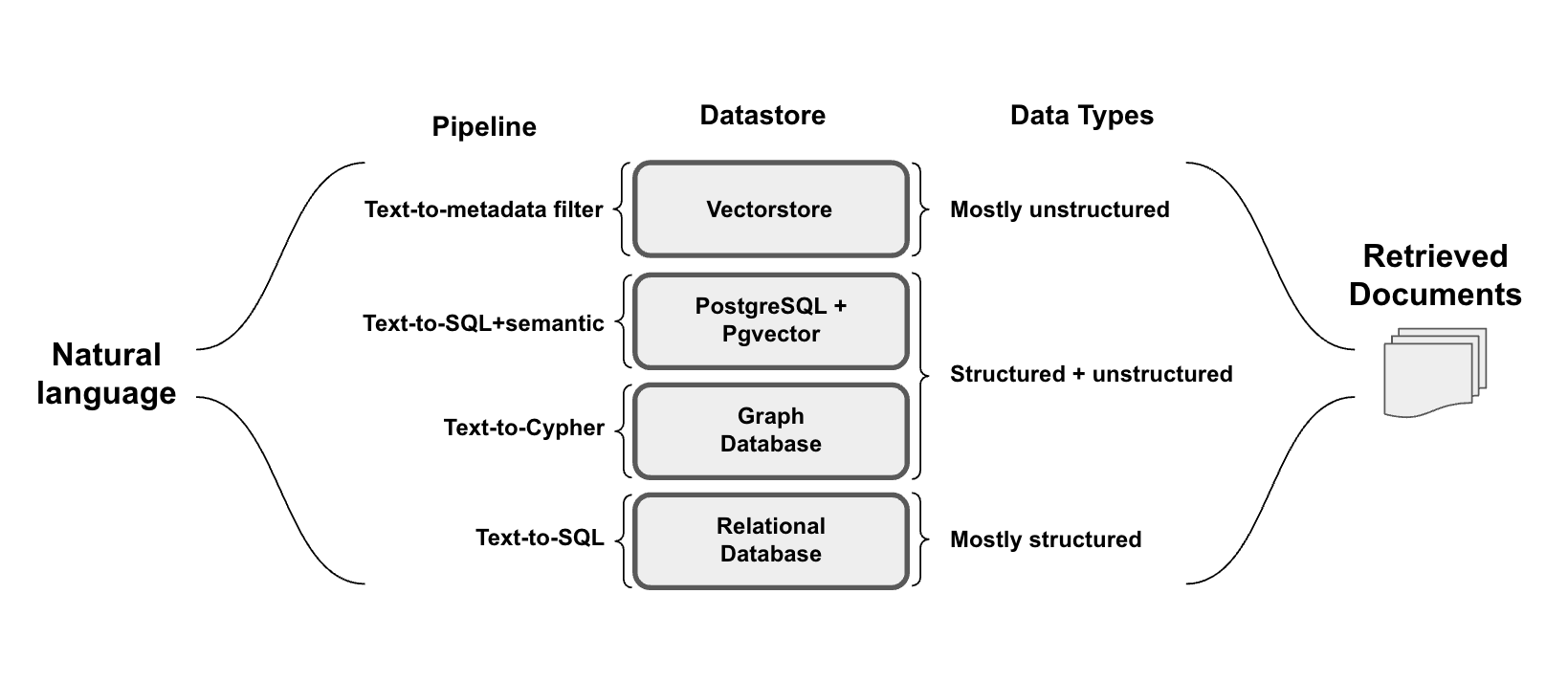
由于 OpenAI 研究中提到的数据源之一是关系型 (SQL) 数据库,因此需要从用户输入生成有效的 SQL,以便提取必要的信息。LangChain 支持 文本到 SQL,这在我们最近的 最新博客 中进行了深入回顾,该博客专注于查询构建。
其他值得考虑的想法:
构建索引
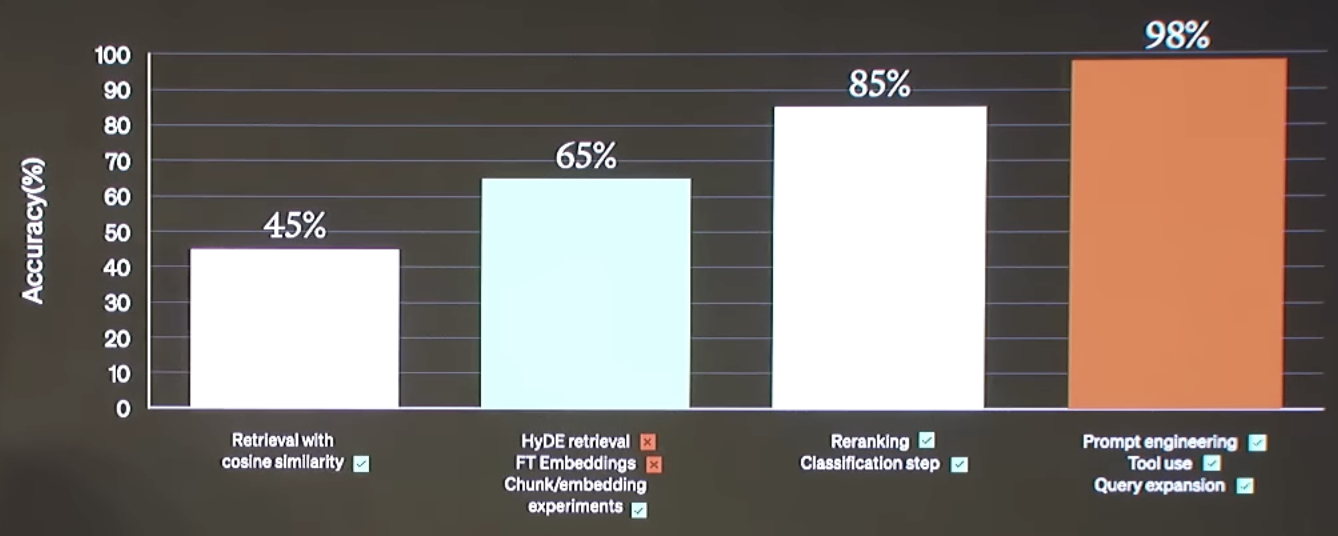
OpenAI 报告称,仅仅通过实验文档嵌入期间的块大小,性能就得到了显着提升。由于这是索引构建中的核心步骤,我们有一个 开源 Streamlit 应用程序,您可以在其中测试块大小。
虽然他们没有报告通过嵌入微调获得显着性能提升,但 有利的结果 已被报告。虽然 OpenAI 指出这可能不是建议作为“唾手可得的成果”,但我们分享了 微调指南,并且 HuggingFace 提供了一些 非常 好的 教程,更深入地探讨了这一点。
后处理
在检索文档之后但在 LLM 摄取之前处理文档,对于许多应用程序来说是一个重要的策略。我们可以使用后处理来强制执行检索文档的多样性或新近度,这在我们从多个来源汇集文档时尤其重要。
OpenAI 报告了两种方法:
- 重新排序:LangChain 与 Cohere ReRank 端点的集成是一种方法,可用于文档压缩(减少冗余),尤其是在我们检索大量文档的情况下。 与此相关的是,RAG-fusion 使用倒数排名融合(参见 博客 和 实现)来重新排序从检索器返回的文档,类似于 多查询(如上所述)。
- 分类:OpenAI 根据内容对每个检索到的文档进行分类,然后根据分类选择不同的提示。这结合了两个想法:LangChain 支持 标记 of 文本 (例如,使用函数调用来强制执行输出模式)进行分类。 如上所述,逻辑路由 也可以用于基于标签进行路由(或在逻辑路由链本身中包含语义标记过程)。
其他值得考虑的想法:
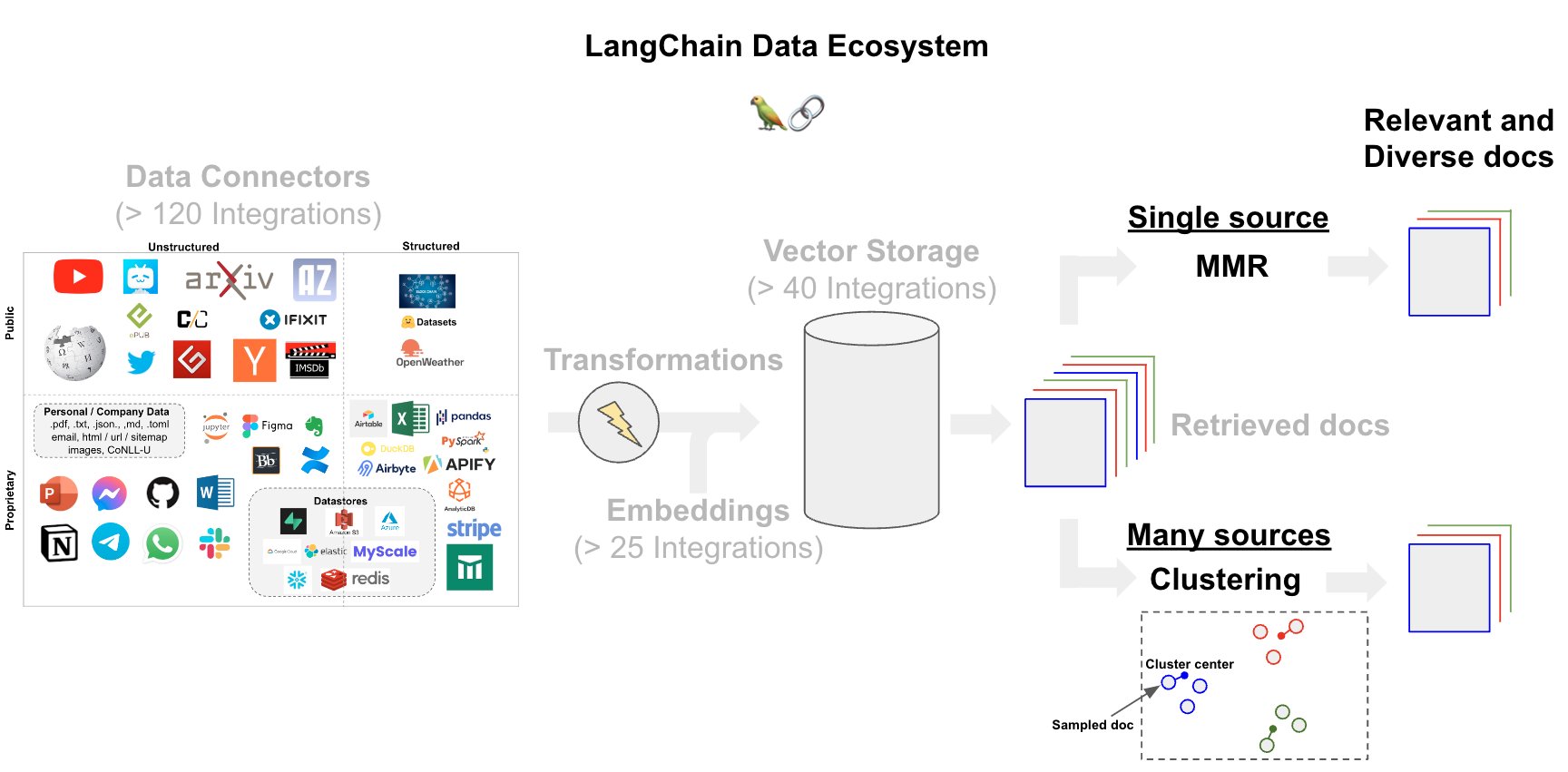
- MMR:为了在相关性和多样性之间取得平衡,许多向量存储提供 最大边际相关性 搜索(参见博客文章 此处)。
- 聚类:一些方法使用了嵌入文档的 聚类 和抽样,这可能有助于我们在整合来自广泛来源的文档的情况下。
结论
了解 OpenAI 在 RAG 主题上尝试过的方法是很有启发意义的。这些方法可以在您自己手中重现,如上所示:尝试不同的方法至关重要,因为应用程序性能在 RAG 设置上可能会有很大差异。
然而,OpenAI 的结果也表明,评估对于避免在几乎没有或没有益处的方法上浪费时间和精力至关重要。对于 RAG 评估,LangSmith 提供了大量支持:例如,此处 是一个使用 LangSmith 评估多个高级 RAG 链的 cookbook。