
作者:Lance Martin
背景
像 LangChain 这样的 LLM 运维平台使得组装 LLM 组件(例如,模型、文档检索器、数据加载器)成链变得容易。问答是这些链最流行的应用之一。但是,确定哪些参数(例如,块大小)或组件(例如,模型选择、VectorDB)能够产生最佳的 QA 性能通常并不明显。
在这里,我们介绍一个用于评估 QA 链的简单工具(在此处查看代码),名为 auto-evaluator
- 要求用户输入一组感兴趣的文档
- 使用 LLM (
GPT-3.5-turbo) 从这些文档中自动生成问题-答案对 - 使用一组指定的 UI 选择的配置生成问答链
- 使用该链生成对每个
问题的回复 - 使用 LLM (
GPT-3.5-turbo) 相对于答案对回复进行评分 - 探索跨各种链配置的评分
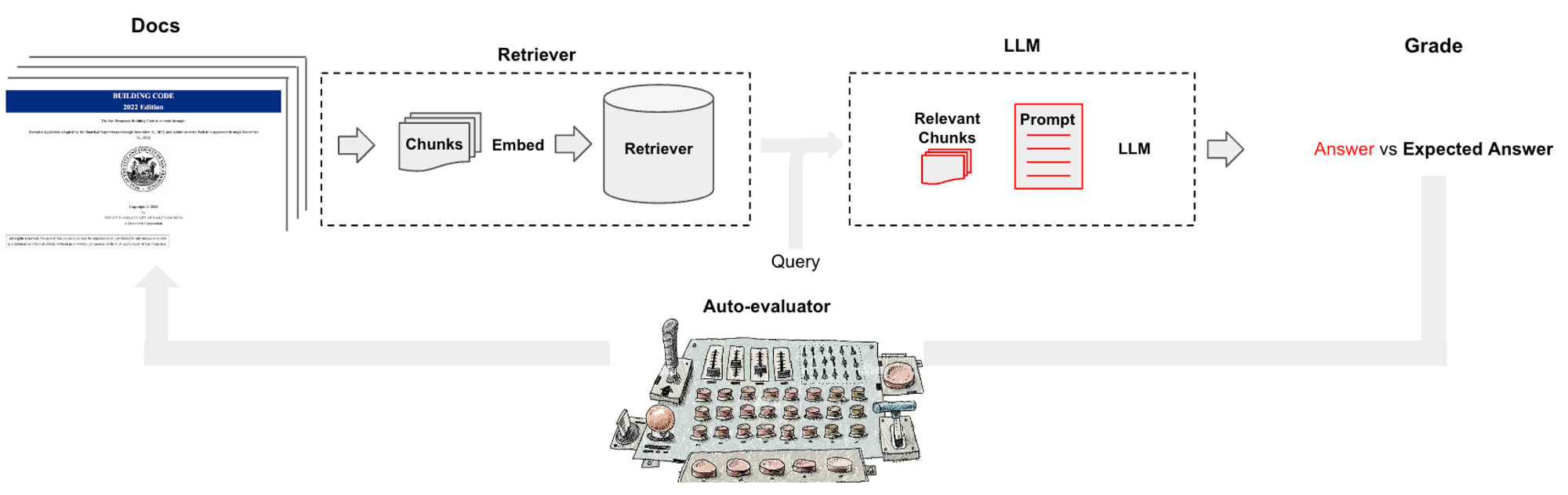
用户输入
这是作为一个 Streamlit 应用程序实现的,用户可以在其中提供一组文档。可选地,用户还可以提供一组相应的问答对(请参阅 此处 的示例)。如果用户不提供此项,应用程序将使用 QAGenerationChain 自动生成评估集。您可以在 此处 查看用于此目的的提示,该提示从输入的随机块中选择问答对。
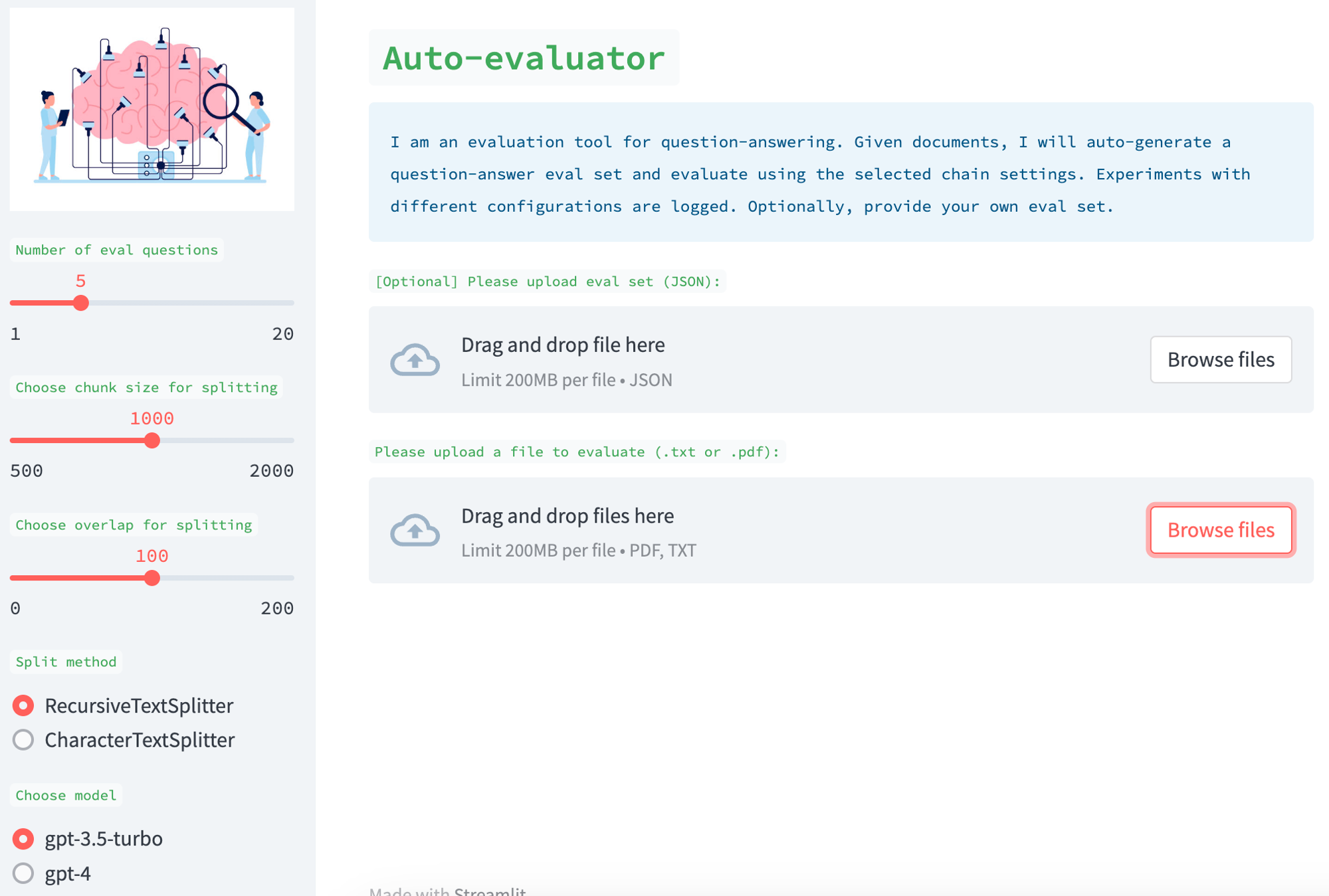
链
UI 具有各种 旋钮,可用于创建 QA 链。例如,您可以从较新的文档检索器(例如,SVM)中选择,或者您可以使用向量存储上的相似性搜索。您可以选择各种文档分割方法、分割大小和分割重叠。您还可以选择用于最终总结从检索到的文档中回答问题的答案的 LLM。可以使用 Langchain 快速轻松地将这些不同的部分组装成一个链以进行评估。
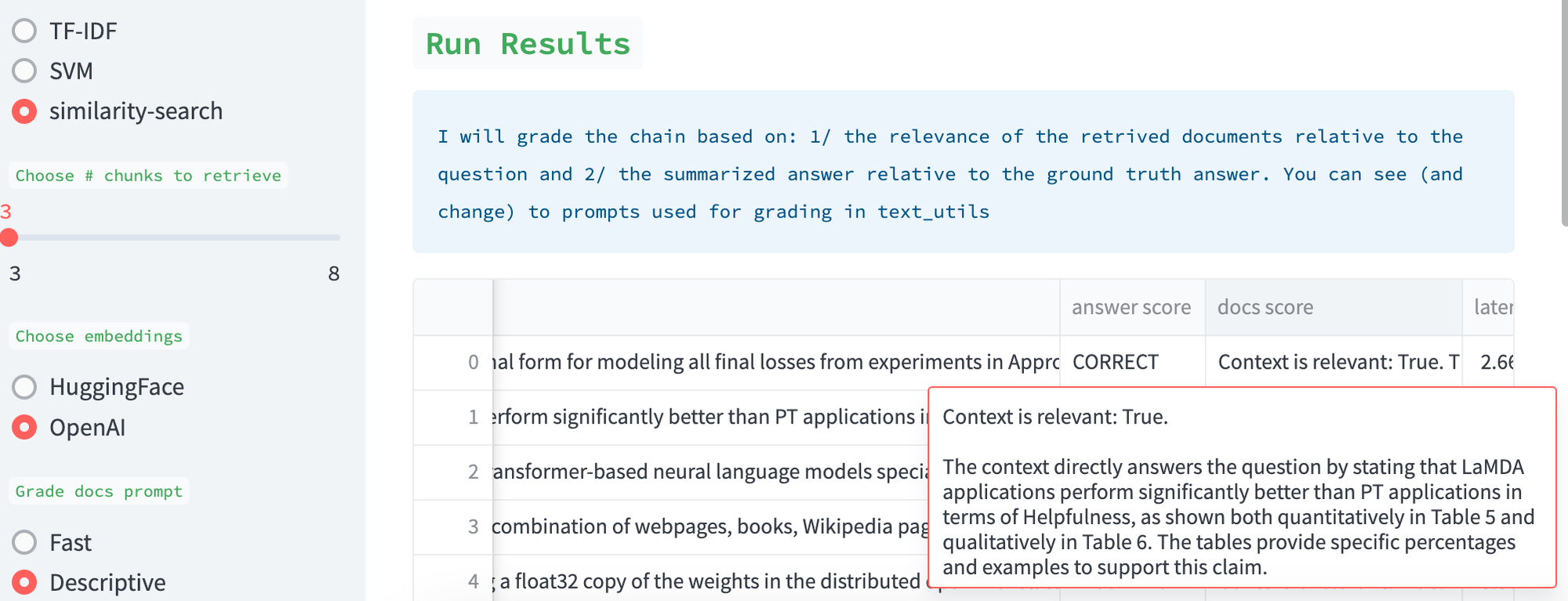
评分
我们使用 LLM (GPT-3.5-turbo) 来评分检索到的文档的质量,这个想法受到与 LLama-Index 的 Jerry Liu 讨论的启发(此处)。我们还使用 LLM 来评分相对于评估集的答案质量。在这两种情况下,我们都公开了 提示。用户可以轻松地设计它们。我们还公开了结果以供人工检查;描述性 提示可用于要求 LLM 评分器详细解释其评估。
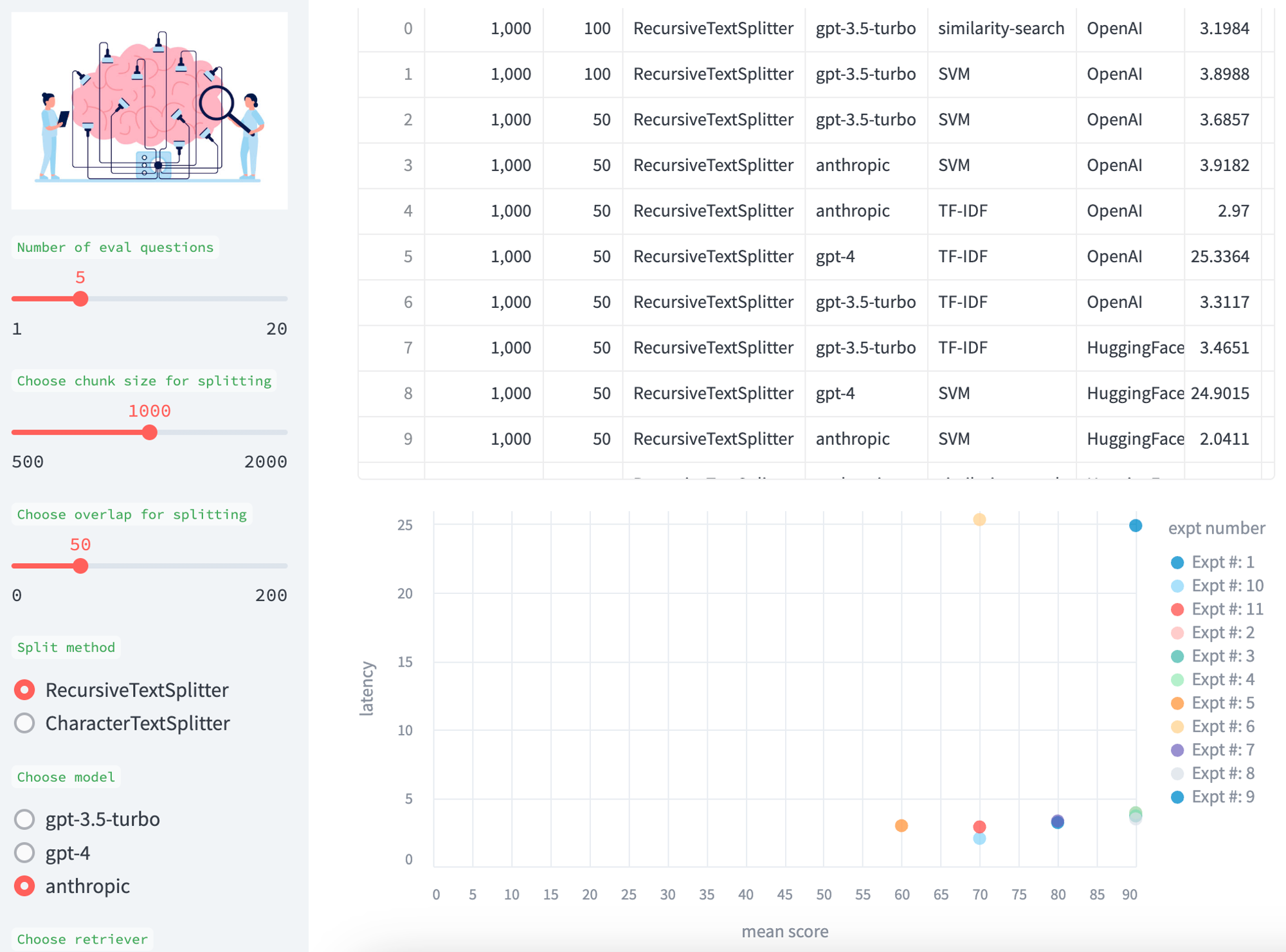
比较
我们积累了实验结果,以便于跨各种测试进行比较,并在表格和平均分数(答案和检索)与模型延迟(秒)的散点图中展示。
未来方向
欢迎反馈和贡献;例如,我们希望包含其他检索器(例如 LLama-Index)和其他模型(例如,各种 HuggingFace 模型)。我们希望提高评估过程中各个阶段的性能(例如,特别是延迟),并将其作为免费托管工具提供(因为今天有些用户将无法访问 GPT-4 或 Claude)。最后,我们希望将其扩展到其他任务(例如,聊天),并根据用户指定的目标(例如,聊天或 QA 目标)自动执行最佳链组装过程(例如,使用代理)。