
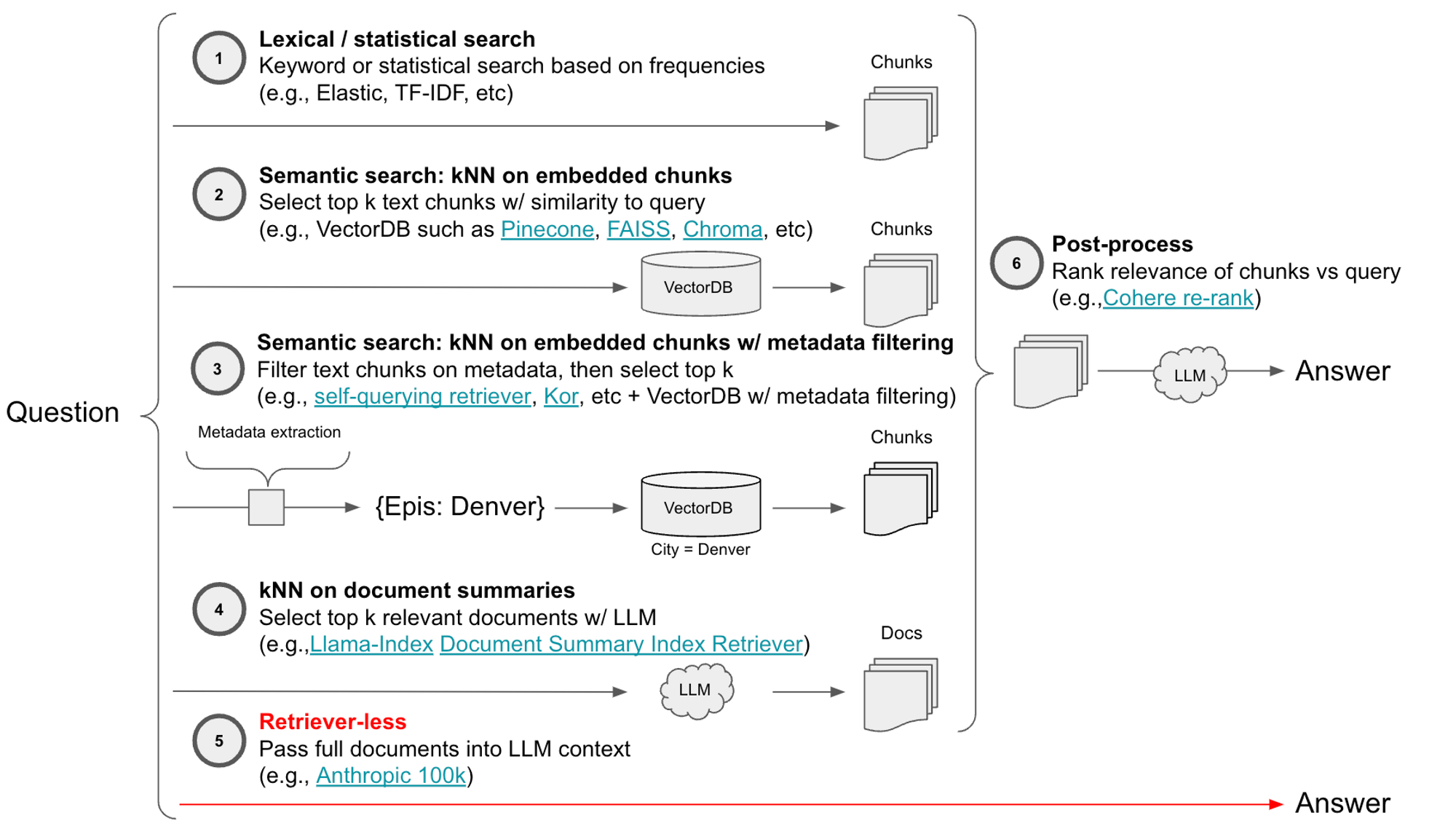
检索架构
LLM 问答 (Q+A) 通常涉及检索与问题相关的文档,然后由 LLM 合成检索到的块以形成答案。 在实践中,检索步骤是必要的,因为相对于大多数感兴趣的文本语料库的大小而言,LLM 上下文窗口是有限的(例如,对于许多模型,LLM 上下文窗口的范围为约 2k-4k tokens,对于 GPT4,高达 8k-32k)。Anthropic 最近发布了一个具有 10 万 token 上下文窗口的 Claude 模型。 随着具有更大上下文窗口的模型的出现,人们有理由怀疑,对于许多问答或聊天用例,文档检索阶段是否是必要的。
这是一个检索器架构的分类,其中突出显示了这种无检索器的选项
- 词汇/统计:TF-IDF、Elastic 等
- 语义:Pinecone、Chroma 等
- 具有元数据过滤的语义:Pinecone 等,带有过滤工具(自查询、kor 等)
- 文档摘要的 kNN:Llama-Index 等
- 后处理:Cohere re-rank 等
- 无检索器:Anthropic 10万上下文 窗口等
评估策略
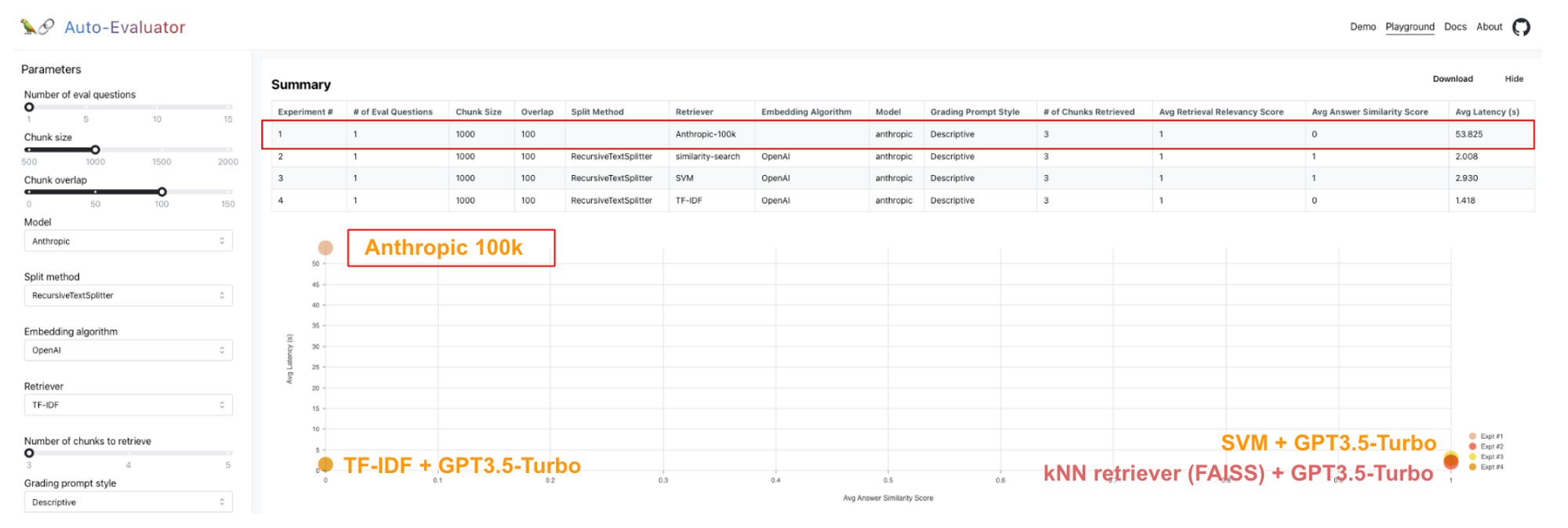
我们之前介绍了 auto-evaluator,这是一个用于 LLM 问答链评分的 托管应用 和 开源 代码库。这为比较 Anthropic 10 万上下文窗口模型在问答方面的性能与其他检索方法(例如 VectorDB 上的 kNN、SVM 等)提供了良好的测试平台。
结果
在针对 75 页 GPT3 论文(此处)的 5 个问题测试集中,我们看到 Anthropic 100k 模型的性能与 kNN (FAISS) + GPT3.5-Turbo 相当。当然,这令人印象深刻,因为完整的 pdf 文档直接在提示中传递给 Anthropic 100k。但是,我们也可以看到,这是以延迟为代价的(例如,Anthropic 100k 约为 50 秒,而其他方法则小于 10 秒)。

我们还在关于旧金山 建筑规范 的 51 页 PDF 上进行了测试,并提出了一个特定的许可问题,该问题 已在之前的评估中使用。在这里,我们看到 Anthropic 100k 不如 SVM 和 kNN 检索器;请参阅 此处 的详细结果。Anthropic 100k 产生了更冗长且接近正确的答案(声明后院棚屋 > 120 平方英尺需要许可证,而正确答案是 > 100 平方英尺)。无检索器架构的一个缺点是我们无法检查检索到的块,以调试模型产生不正确答案的原因。
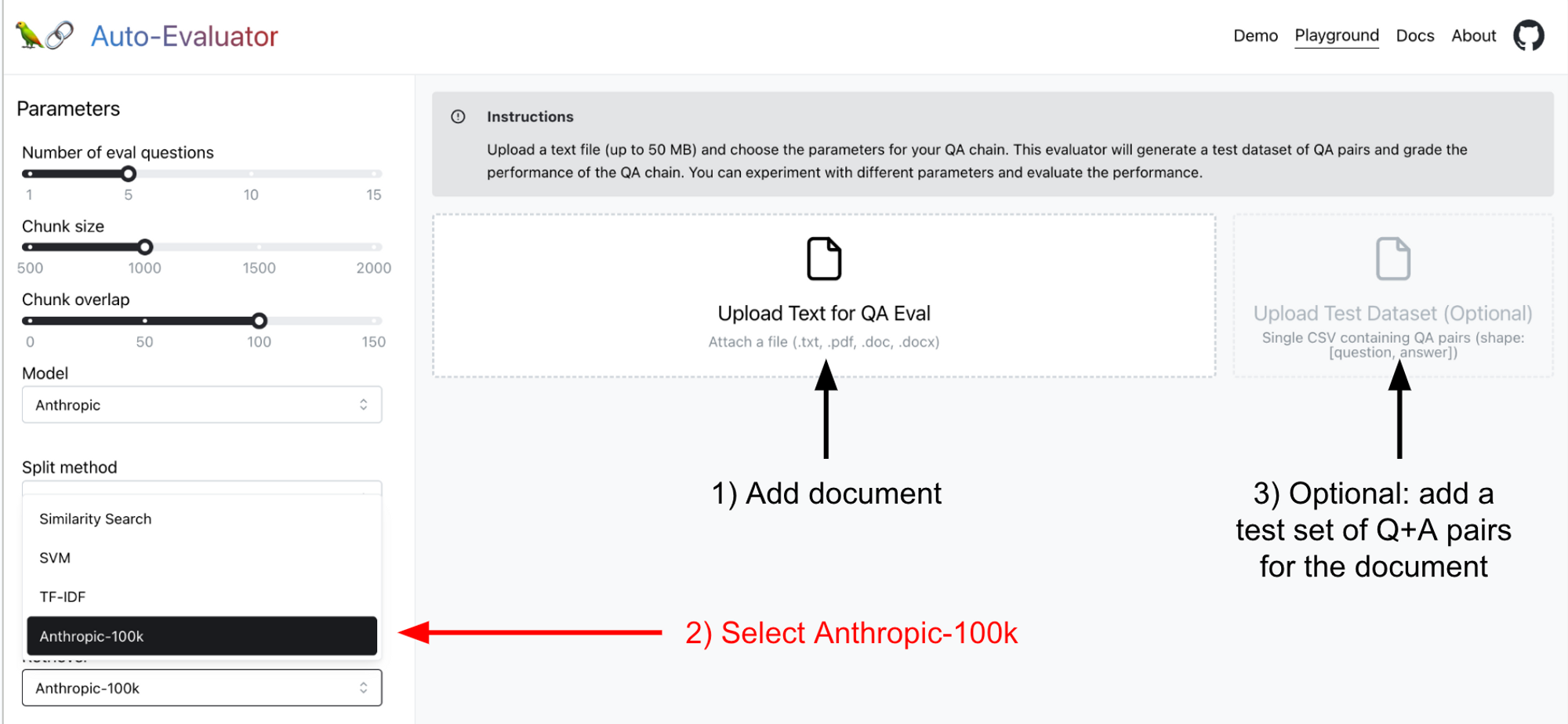
自行测试
我们已在 我们的托管应用 中部署了 Anthropic 100k,因此您可以亲自尝试并相对于其他方法进行基准测试。有关更多详细信息,请参阅我们的 README,但简而言之
- 添加感兴趣的文档
- 选择
Anthropic-100k检索器 - (可选)添加您自己的测试集(如果您不提供,该应用将 自动生成一个)
结论
无检索器架构因其简单性和在我们尝试的少数挑战中表现出的良好性能而引人注目。当然,有一些注意事项:1) 它比基于检索器的方法具有更高的延迟;2) 许多(例如,生产)应用将拥有比 10 万 token 上下文窗口大得多的语料库。对于延迟不关键且语料库相对较小的应用(对一小部分文档进行问答),无检索器方法具有吸引力,尤其是在 LLM 的上下文窗口增长且模型变得更快的情况下。