重要链接
动机
网络研究是 LLM 的杀手级应用之一:Greg Kamradt 强调它是他最想要的 AI 工具之一,而像 gpt-researcher 这样的 OSS 仓库正变得越来越受欢迎。我们决定尝试一下,最初像许多其他人一样着手构建一个网络研究代理。但是,我们最终得到了不同的结果:一个相当简单的检索器被证明是有效且易于配置的(例如,以项目如 PrivateGPT 所推广的私有模式运行)。在这篇博文中,我们讨论了我们的探索和思考过程,我们是如何构建它的,以及接下来的步骤。
探索
像 gpt-researcher 和 AI 搜索引擎 (perplexity.ai) 这样的上述项目,初步展示了网络研究可能如何被重新构想。像许多人一样,我们首先设计了一个代理,它可以被赋予一个提示、一组工具,然后开始在网络上 自主 搜索!为此,它显然需要工具来
- 搜索并返回页面
- 抓取返回页面的完整内容
- 从页面中提取相关信息
有了这些工具,代理可以近似于人类所做的事情:搜索一个主题,选择选定的链接,浏览链接以查找有用的信息片段,并在迭代探索中返回搜索。我们制作了一个代理,并赋予了它这些工具……但发现它像人类一样,在迭代搜索过程中缓慢摸索!
改进
我们注意到人工智能可以独特利用的一个核心优势:并行启动多个搜索,并反过来并行“阅读”多个页面。当然,如果顺序搜索中的第一篇文章包含所有必要的信息,这可能会导致效率低下。但对于需要 AI 研究员的复杂问题,这种风险在某种程度上得到了缓解。我们添加了一些 基本 工具 来支持这个过程。
通过从一组页面并行收集大量信息,从每个页面获取最相关的块并将它们加载到 LLM 的上下文窗口中进行综合似乎是合理的。当然,在这一点上,我们意识到我们的代理正在演变成一个检索器!(注意:我们仍然认为,正如结尾所讨论的,代理属性可以进一步使这个检索器受益。)
检索
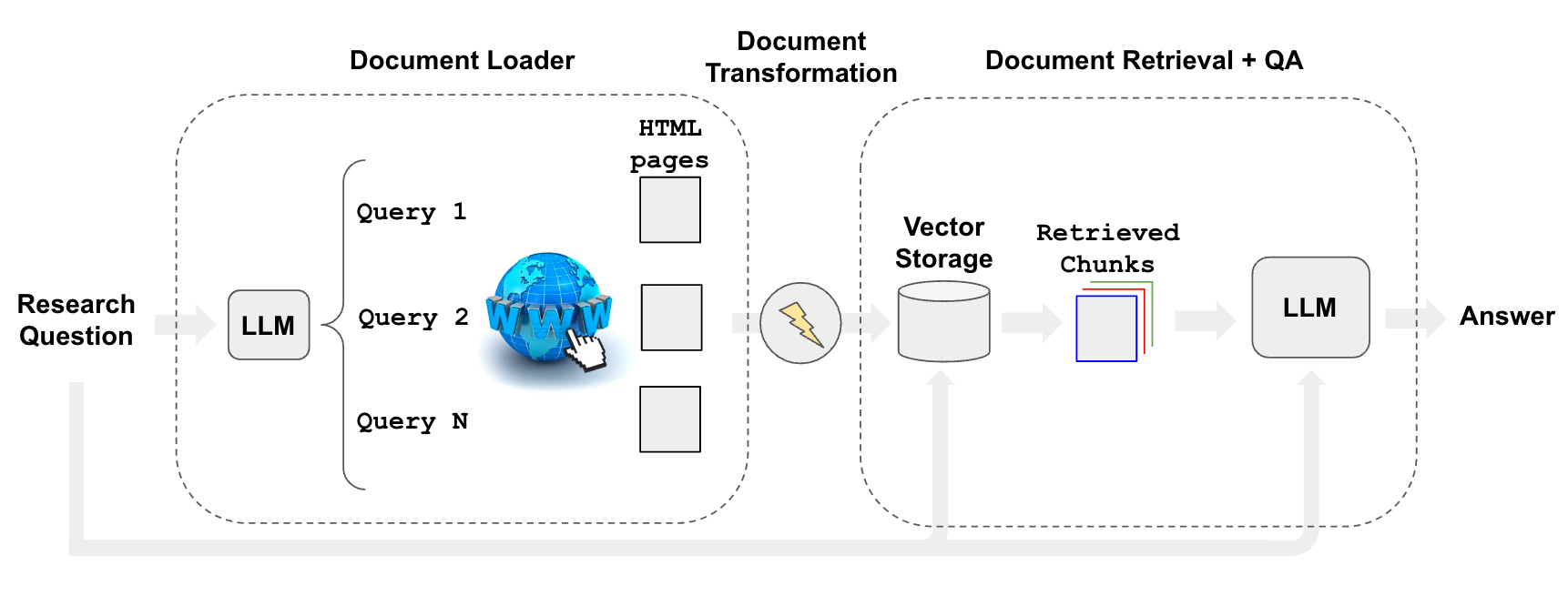
这个检索器在底层究竟会做什么?我们的想法是
- 使用 LLM 生成多个相关的搜索查询(一次 LLM 调用)
- 为每个查询执行搜索
- 为每个查询选择前 K 个链接 (多次并行搜索调用)
- 从所有选定的链接加载信息(并行抓取页面)
- 将这些文档索引到向量存储中
- 为每个原始生成的搜索查询查找最相关的文档
总的来说,这些步骤属于用于检索增强生成的 流程
然而,其逻辑与 gpt-researcher 的代理架构相似
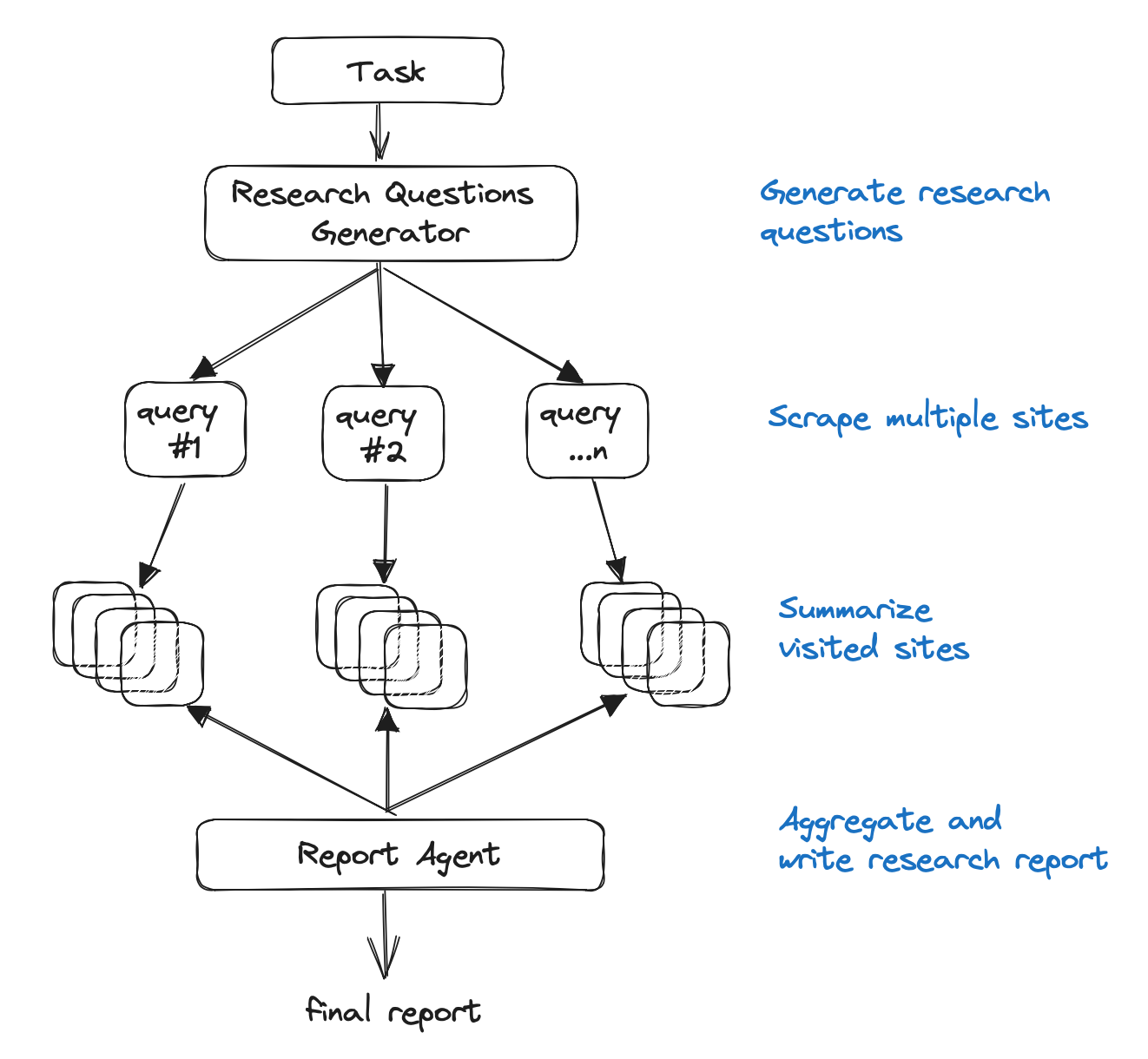
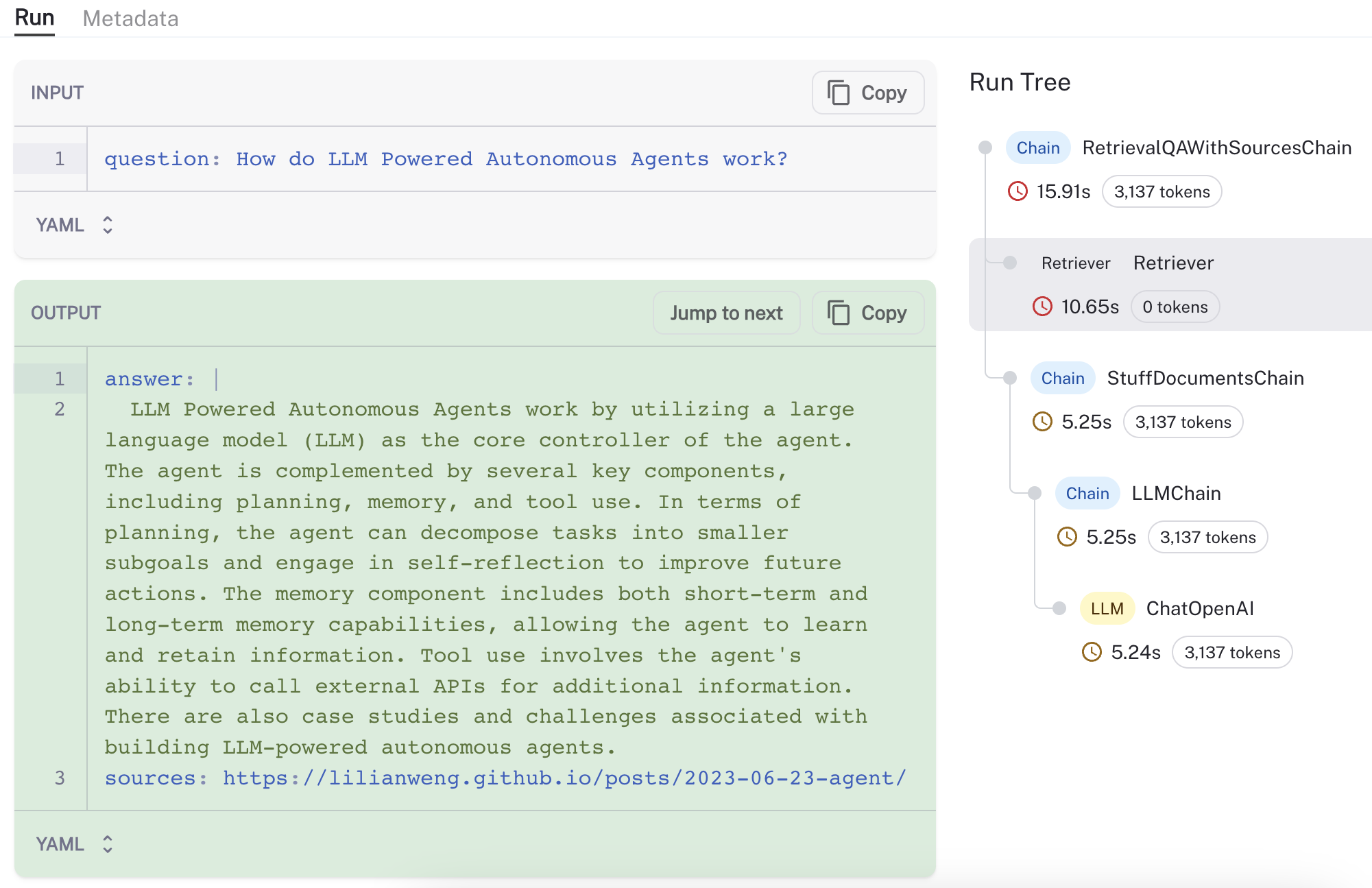
即使这不是一个代理,逻辑上的相似性也是对该方法的一个有用的健全性检查。我们创建了一个新的 LangChain 检索器,并提供了关于 使用 和配置的文档。对于一个示例问题(LLM 驱动的自主代理如何工作?),我们可以使用 LangSmith 来可视化和验证该过程(参见 此处 的跟踪),观察到检索器从一个合理的来源(Lilian Weng 关于代理的 博文)加载和检索块
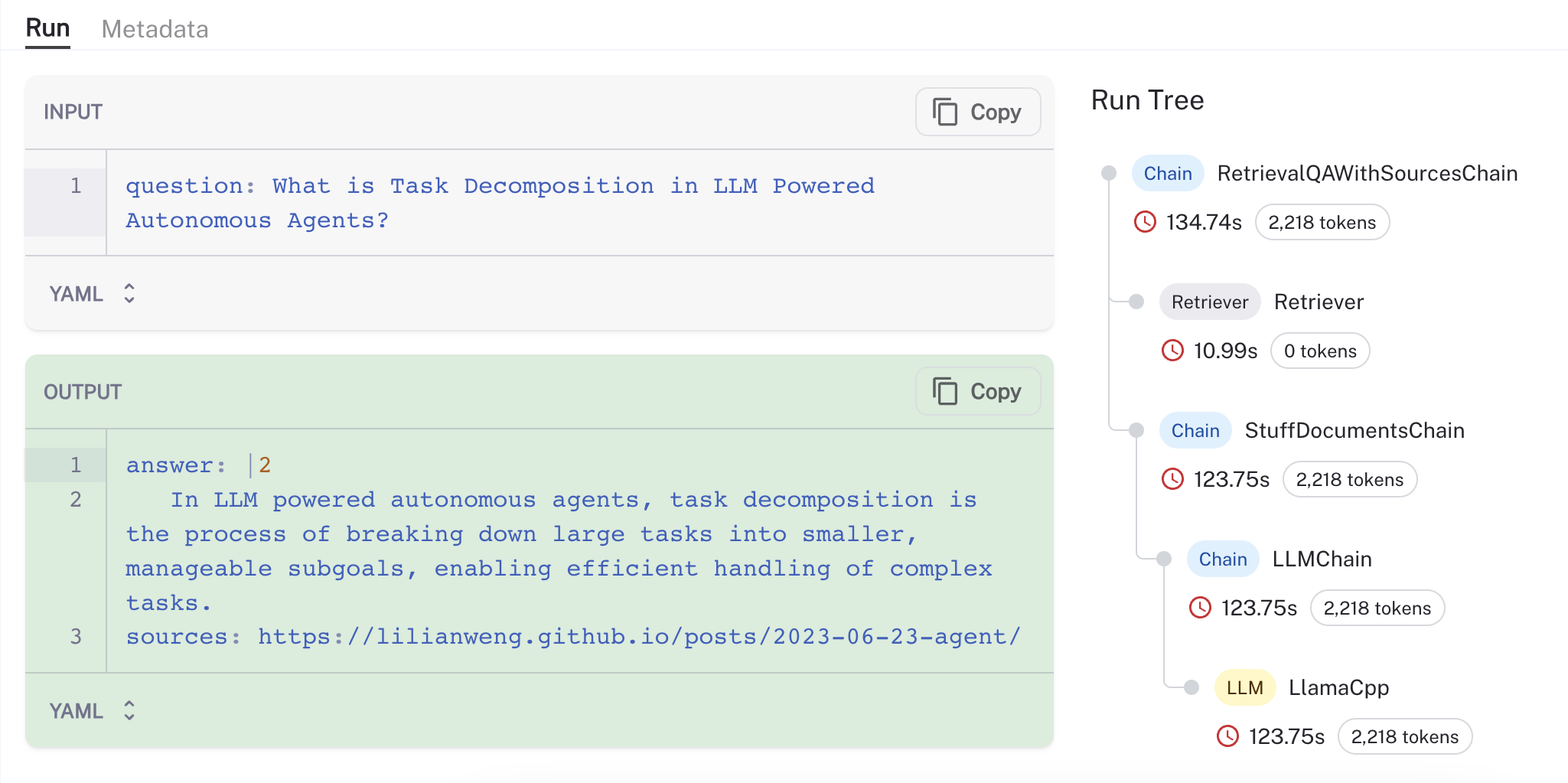
正如文档中指出的那样,可以使用例如 LlamaV2 和 GPT4all 嵌入,以“私有”模式轻松配置相同的过程(下面是我的 Mac M2 Max GPU 上执行的运行的 跟踪,速度约为 50 tok/秒)
应用
我们用一个简单的 Streamlit IU(只有大约 50 行代码 此处)包装了检索器,该 IU 可以配置任何 LLM、向量存储和选择的搜索工具。
结论
最初试图构建一个自主网络研究代理,最终演变成一个相当简单/高效且可定制的检索器。尽管如此,这只是第一步。这个项目可以从添加许多代理属性中受益,例如
- 在初始搜索后询问 LLM 是否需要更多信息
- 使用多个“写入”和“修订”代理来构建最终答案
如果这些添加中的任何一个听起来有趣,请针对 基础仓库 打开一个 PR,我们将与您合作将其纳入!
虽然像 Bard 或 Perplexity.ai 这样的大型模型提供的托管 AI 搜索非常强大,但用于网络研究的较小、轻量级工具也具有重要的优点,例如隐私(例如,在本地笔记本电脑上运行而无需外部共享任何数据的能力)、可配置性(例如,选择要使用的特定开源组件的能力)和可观察性(例如,使用 LangSmith 等工具深入了解“幕后”发生的事情)。