
这是一篇稍长的文章。深入探讨了表格数据问答。本文讨论(并使用)CSV 数据,但许多相同的想法也适用于 SQL 数据。内容涵盖:
- 背景动机:为什么这是一项有趣的任务
- 初始应用:我们如何设置一个简单的 Streamlit 应用,以便收集真实问题的良好分布
- 初始解决方案:我们的初始解决方案和一些概念性考虑
- 使用 LangSmith 调试:我们看到人们提出了什么问题,以及我们初始解决方案存在哪些问题
- 评估设置:我们如何评估解决方案
- 改进的解决方案:我们最终得到的改进解决方案
先睹为快,我们最终得到的改进解决方案是一个自定义代理,它使用 OpenAI 函数并可以访问两个工具:Python REPL 和检索器。
我们已开源所有内容——我们用于收集反馈的应用、数据集、评估脚本——在此仓库中。如果您更喜欢视频形式,我们还制作了一个 YouTube 视频,其中介绍了此博客的内容。
背景动机
关于文本数据问答,现在已经有一个相当标准的配方。另一方面,我们一直听到需要改进的一个领域是表格 (CSV) 数据。许多企业数据都包含在 CSV 中,而通过自然语言界面公开这些数据可以轻松获得洞察力。问题是,如何实现这一点还不太清楚。
几周前,我们决定专注于此问题,但很快遇到了一个问题——我们并不真正了解人们期望能够向 CSV 数据提出哪些类型的问题,并且我们没有任何好的方法来评估这些应用程序。
在传统的机器学习中,您通常从输入和输出的数据集开始,并使用它来训练和评估您的模型。然而,由于 LLM 是出色的零样本学习器,现在可以使用提示根据一个想法快速构建应用程序,而无需任何数据。虽然这在使开发人员能够快速构建新应用程序方面非常强大,但由于您缺乏数据,因此导致评估困难。这就是为什么我们构建 LangSmith 的方式,使构建数据集尽可能容易。
同样,通常没有很好的指标来评估 LLM 应用程序。输出通常是自然语言,而传统的 NLP 指标(如 BLEU 和 ROUGE)并不理想。但是,什么擅长理解自然语言呢?LLM!我们非常看好 LLM 辅助评估,并投入精力构建了大量使用 LLM 进行评估的评估器。
那么,我们如何将这些想法应用于我们创建更好的应用程序来回答有关表格数据的问题的任务呢?我们将在接下来的部分中更详细地探讨这些内容,但从高层次上讲,我们:
- 使用 LangSmith 标记有趣的datapoint,并使用它来构建示例数据集
- 使用 LLM 评估正确性
初始应用
首先,我们着手创建问题和真实答案的数据集。这里的部分问题是,我们甚至不知道人们希望向其表格数据提出哪种类型的问题。我们可以做出一些有根据的猜测,或者尝试生成合成问题来提问。但我们希望优化真实问题,因为我们也想探索一下真实用户希望提出哪些类型的问题。
为了做到这一点,我们决定启动一个快速演示应用程序并将其发布到网络上。然后,我们将记录实际用户的问题以及他们给我们的关于答案的任何反馈。为了收集反馈,我们在应用程序中添加了一个简单的“赞”/“踩”按钮。我们将使用 LangSmith 监控所有交互和反馈,然后我们将手动审查交互并创建一个包含任何有趣交互的数据集。这可以从 LangSmith UI 轻松完成 - 所有日志上都有一个“添加到数据集”按钮。
还有一个问题是,我们想要收集哪种类型的数据。我们考虑了两种方法:(1)让用户上传他们自己的 CSV 并询问有关该 CSV 的问题,(2)固定 CSV 并收集有关该 CSV 的问题。由于以下几个原因,我们选择了(2)。首先 - 这将使人们更容易试用,可能会带来更多响应。其次 - 这可能会使评估更容易。第三 - 我们特别希望记录和查看用户问题,并且我们不想在某人可能上传的任何机密 CSV 上执行此操作。但是,这确实有几个缺点。我们将不得不选择一个要使用的 CSV,并且此 CSV 可能不代表其他 CSV - 无论是在数据的大小和形状方面,还是人们可能希望提出的问题方面。
对于我们的示例应用程序,我们选择了经典的 泰坦尼克号数据集 - 记录了泰坦尼克号上的所有乘客以及他们是否幸存,通常用于示例数据科学项目。我们使用 Streamlit 创建了这个简单的应用程序,将其发布到世界各地,并要求人们提供反馈。您可以在此处查看托管应用程序,以及此处查看源代码。
通过这种方式,我们收集了约 400 次交互。其中,约 200 次有某种形式的反馈。使用 LangSmith,我们深入研究了反馈不良(以及一些反馈良好)的数据点,手动标记它们并将它们添加到我们创建的数据集中。我们这样做直到我们拥有大约 50 个数据点。
现在是时候改进我们的系统了!在讨论我们如何改进之前,让我们先讨论(1)初始系统是什么,(2)它存在哪些问题,以及(3)我们将如何评估系统以衡量任何改进。
初始解决方案
泰坦尼克号数据集包含混合列。其中一些是数字(年龄、兄弟姐妹数量、票价),一些是类别(登船站、船舱),还有一个文本列(姓名)。
虽然一个人的姓名不是非常文本密集,但它仍然足够文本密集,会引起一些问题。例如,如果问题是关于“John Smith”,则该名称可能有很多种表示形式:Mr. John Smith(头衔)、Smith, John(顺序)、Jon Smith(拼写错误)、John Jacob Smith(中间名)等。这会使按姓名精确过滤行,甚至进行查找变得棘手。因此,从一开始我们就知道我们必须包含一些更基于模糊的功能。但是,我们也猜测人们会希望提出一些关于聚合的问题(“谁支付的票价最多”)或类似的问题,因此我们可能需要一些功能来做到这一点。
检索
对于自然语言部分,我们希望使用传统的检索系统。我们不打算过于花哨,所以我们只想使用一个简单的向量存储,并根据与输入问题之间的余弦相似度查找结果。
为了做到这一点,我们需要将 CSV 加载到向量存储中。我们使用我们的 CSVLoader 的逻辑来完成此操作。其底层原理是:
- 将每一行加载为自己的文档
- 将每个文档的文本表示为
列: 值对的列表,每个值都在自己的行上。
更深入地探讨第 (2) 点,您可以通过几种方式将 CSV 行表示为文档。您可以将其表示为 JSON、CSV,或者 - 正如我们最终所做的那样 - 格式化的文本片段。非常具体地说,如果您有一个 CSV 行,其值如下:{"col1": "foo", "col2": "bar"},那么在您格式化后,它最终看起来像这样:
col1: foo
col2: bar虽然这看起来可能不是那么有趣,但 LLM 应用程序的一大组成部分是正确的数据工程,以便最有效地将数据传达给 LLM。有趣的是,我们发现当值可能包含文本值时,表格(以及 JSON)数据的这种表示形式是最有效的。
查询语言
除了检索之外,我们还认为人们会希望提出一些需要某种查询语言的问题。例如 - “谁支付的票价最多”。我们在这里考虑了两种方法。
首先,我们考虑使用 Python REPL 并要求语言模型编写代码来帮助回答用户的问题。这样做的好处是非常灵活。这样做也有可能过于灵活的缺点 - 它可能会启用任意代码的执行。
其次,我们考虑使用 kork 来访问预定义的函数集。kork 是一个基本上将一组可以使用的函数列入白名单的库。它不太通用 - 您必须声明所有可以运行的函数 - 但它更安全。
首先,我们使用了 kork。我们不太确定人们会问什么,所以我们定义了一些函数(filter、sum、contains)并授予了它访问权限。
我们的第一个解决方案并行运行检索和 kork,然后合并答案。
使用 LangSmith 调试
人们开始提出问题,反馈也开始涌入。只有大约 1/3 的反馈是积极的。哪里出错了?有两个主要的错误来源:
数据格式化
我们为 kork 编写的许多函数都会返回一个数据帧。然后,将此数据帧插入到提示中并传递给语言模型。然后出现了一个问题,即如何将该数据帧格式化为字符串以传递给语言模型。
这对于回答诸如 谁在 C128 船舱 之类的问题非常重要。返回的数据帧应该已过滤到正确的行并返回所有相关信息。在我们启动应用程序之前,我们测试了类似这样的问题,并且运行良好。但是,在我们启动应用程序并开始查看响应后,我们注意到它在回答大量此类问题时表现非常糟糕。
我们使用 LangSmith 检查跟踪,试图了解发生了什么。我们可以看到正确的查询正在生成...但是当该数据帧传递到提示中时,格式化被搞砸了。我们期望它看起来像这样:
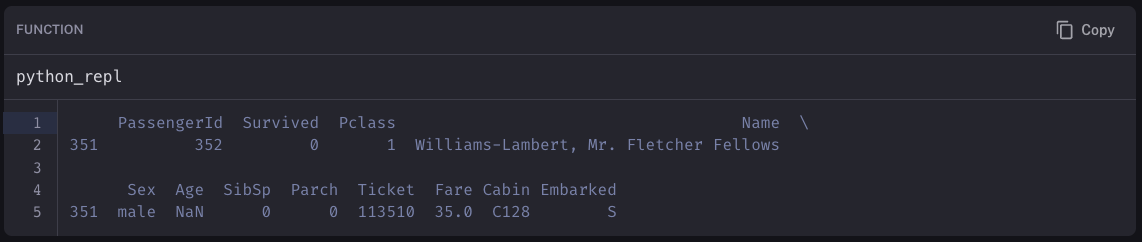
但实际上它看起来像这样:

经过更多调试后,我们发现数据帧表示为字符串的方式可能会因您所在的平台而异。在这种情况下,与 Streamlit 云相比,它在本地的表示方式有所不同。经过更多调试后,我们发现我们可以通过指定一些参数来修复这种不一致性:
pd.set_option('display.max_rows', 20)
pd.set_option('display.max_columns', 20)这样做修复了我们的许多问题!它还表明 LangSmith 在调试 LLM 问题方面非常有用。将 LLM 应用程序从原型推向生产的主要部分是提示工程和数据工程。了解当您将数据传递给 LLM 时数据的确切外观对于调试性能问题至关重要。我们从 LangSmith 的几位用户那里听说,他们在使用 LangSmith 更仔细地检查 LLM 的确切输入后才发现这些类型的数据工程问题。
有限的 kork 功能
事实证明,我们提供给 kork 的函数集远远不足以涵盖用户提出的长尾问题。
对此有两种可能的修复方法。一种,我们可以尝试向 kork 添加更多函数。第二种,我们可以恢复使用 Python REPL。
评估设置
因此,我们现在构建了真实世界示例数据集。我们还进行了一些手动调试,并确定了一些错误领域,并对如何改进有一些想法。我们究竟如何衡量我们是否取得了改进呢?
为了举例说明为什么这并非易事,让我们考虑问题 谁在 C128 船舱。CSV 中的正确答案是 Williams-Lambert, Mr. Fletcher Fellows。但是,语言模型可能会以多种方式响应,这些方式应被视为“正确”:
Mr. Fletcher Fellows Williams-LambertC128 船舱的人是 Mr. Fletcher Fellows Williams-Lambert。Fletcher Williams-LambertMr. Williams-Lambert 在那个船舱里
为了正确评估这些自然语言答案...我们求助于语言模型。我们决定使用我们的标准 qa 评估器,它将以下内容作为输入:
- 输入
- 真实答案
- 预测答案
从那里,它使用这些值格式化提示模板,并将其传递给语言模型以获得响应。
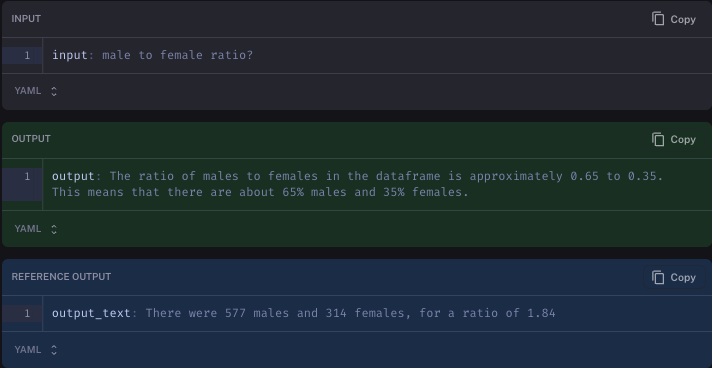
即便如此,这仍然不是完美的。例如,我们评估的问题之一是 男女比例是多少?。这个问题的答案应该是什么很不清楚。我们将答案标记为 男性 577 人,女性 314 人,比例为 1.84。在一次测试运行中,语言模型响应 数据帧中男女比例约为 0.65 比 0.35。这意味着大约有 65% 的男性和 35% 的女性。我们的 LLM 评估器将该答案标记为不正确,即使它可能很可能是正确的。
这是否意味着 LLM 评估器毫无用处?我们不这样认为。相反,我们认为 LLM 评估器仍然有用。首先,它们明显优于我们尝试过的其他“通用”评估方法。其次,即使偶尔正确,如果您不将评分视为福音,那也完全可以接受。例如 - 不要盲目接受 LLM 分数,而是将它们视为可能值得关注的指标。即使您仍然需要在某些数据点上进行人工评估,使用 LLM 辅助评估也可以帮助您找到最值得关注的数据点。
改进的解决方案
最后,我们来到了博客的激动人心的部分。我们是否成功改进了我们的解决方案?我们是如何做到的?
我们的最终解决方案是:
- 由 OpenAIFunctions 驱动的代理 (
OpenAIFunctionsAgent) - GPT-4
- 两个工具:Python REPL 和检索器
- 一个自定义提示,其中包含关于何时使用 Python REPL 与检索器的自定义说明
这提供了几个好处。首先,通过授予它访问 Python REPL 的权限,我们使其能够执行各种查询和分析。但是,正如我们将在下面的一些比较中看到的那样,Python REPL 在处理文本数据时可能会出现问题 - 在这种情况下是 Name 列。这就是检索器可以派上用场的地方。
请注意,我们在提示中包含了一些特定于泰坦尼克号数据集的说明。具体来说,我们告诉它应该尝试将检索器用于 Name 列,并将 Python REPL 用于大多数其他内容。我们这样做是因为使用通用措辞,它在推理何时使用它时遇到了一些麻烦。这确实意味着与通用解决方案(如下所示)进行比较有点不公平。作为后续行动,我们很乐意看到提出一个更通用的提示,其中不包含特定于数据集的逻辑。但是,我们也相信,为了真正提高应用程序的性能,您可能需要使用自定义提示,而不是依赖通用默认设置。
现在让我们看一下一些结果,并与其他方法进行比较。首先,我们与我们的标准 Pandas Agent(使用 GPT-3.5 和 GPT-4)进行比较。接下来,我们与 PandasAI 进行比较 - 用于与 Pandas DataFrame 交互的顶级开源库之一。性能表如下。同样,这是在 50 个数据点上进行的,并且某些评估可能不是 100% 准确,因此我们还将在事后提供一些具体示例。

注意:这些都是在 LangSmith 上运行的。我们正在努力使评估运行可以公开共享。
Pandas Agent 和 PandasAI 的表现大致相同。他们在涉及人名的问题上遇到了困难。例如,对于以下问题:
Carrie Johnston 有多少个兄弟姐妹?
生成的代码是:
# First, we need to find the row for Carrie Johnston
carrie_johnston = df[df['Name'].str.contains('Carrie Johnston')]
# Then, we can find the number of siblings she has
num_siblings = carrie_johnston['SibSp'].values[0]
num_siblings但是,df[df['Name'].str.contains('Carrie Johnston')] 不会返回任何行,因为她的名字显示为 Johnston, Miss. Catherine Helen "Carrie"
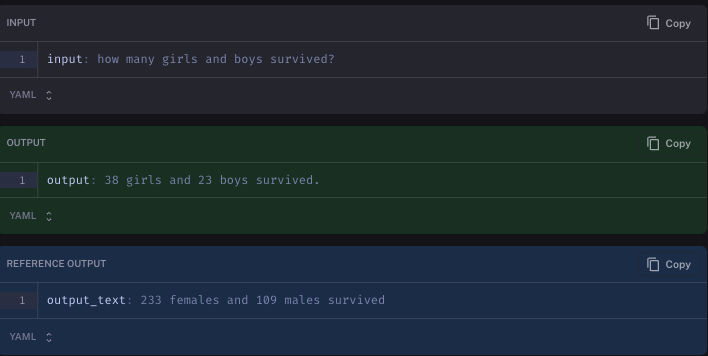
查看我们的自定义代理出错的四个示例,我们可以看到很多错误并不是那么糟糕。
在一种情况下,它基于年龄进行过滤(我们添加的真实答案没有过滤 - 也许应该有?)
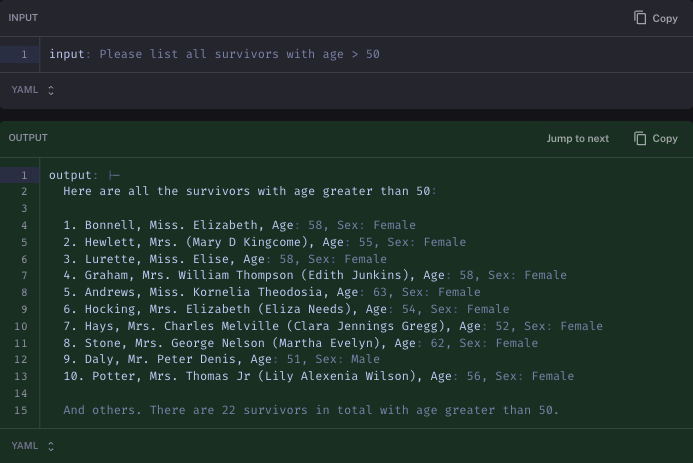
在另一种情况下,它在列出 10 个后停止 - 这实际上是因为打印出的 DataFrame 实际上并没有显示全部内容。
在第三种情况下,它只是对如何响应有不同的解释(但事实看起来是正确的)
最后,它搞砸了,因为它使用检索器搜索名称,而检索器仅限于四个响应。
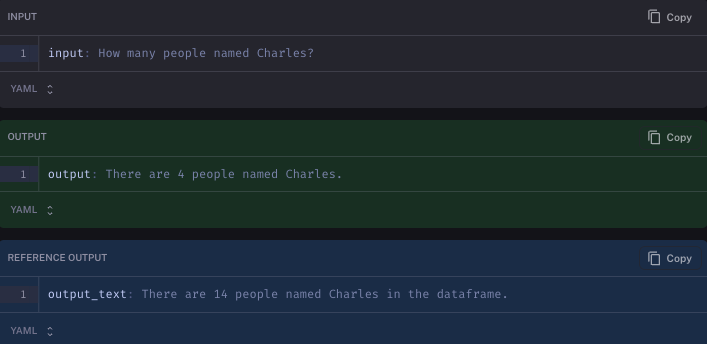
结论
我们对我们最终得到的解决方案非常满意 - 而且大多数反馈也是积极的。我们对我们整理的数据集也非常满意,并认为它可以用于评估这些类型的应用程序。
与此同时,我们认识到始终有改进的空间 - 在两个方面都是如此。数据集可以改进/添加,评估器也可能可以改进,我们尤其期待看到更多解决 CSV 数据问答问题的解决方案!
我们已开源所有内容——我们用于收集反馈的应用、数据集、评估脚本——在此仓库中。