
此博文的初始版本是为 Google 内部 WebML Summit 2023 准备的演讲,您可以在此处查看。
长期以来,机器学习主要以 Python 为主导,这已不是什么秘密,但 ChatGPT 近期流行的激增已将许多新的开发者带入该领域。由于 JavaScript 是使用最广泛的编程语言,因此毫不奇怪,这其中包含了许多 Web 开发者,他们自然而然地尝试构建 Web 应用。
关于通过 API 调用 OpenAI、Anthropic、Google 等服务来构建 LLM 的文章已经汗牛充栋,所以我认为不妨尝试一种不同的方法,尝试完全使用本地模型和技术(最好是在浏览器中运行的技术)来构建 Web 应用!
为什么?
以这种方式构建的主要优势包括:
- 成本。由于所有计算和推理都在客户端完成,因此除了(非常便宜的)托管之外,开发者构建应用不会产生额外成本。
- 隐私。任何内容都不需要离开用户的本地机器!
- 由于没有 HTTP 调用开销,因此可能提高速度。
- 但这可能会被用户硬件限制导致的较慢推理速度所抵消。
项目
我决定尝试使用开源的本地运行软件重新创建一个最流行的 LangChain 用例:一个执行检索增强生成(Retrieval-Augmented Generation,简称 RAG)的链,让您可以“与您的文档聊天”。这使您可以从各种非结构化格式的数据中收集信息。
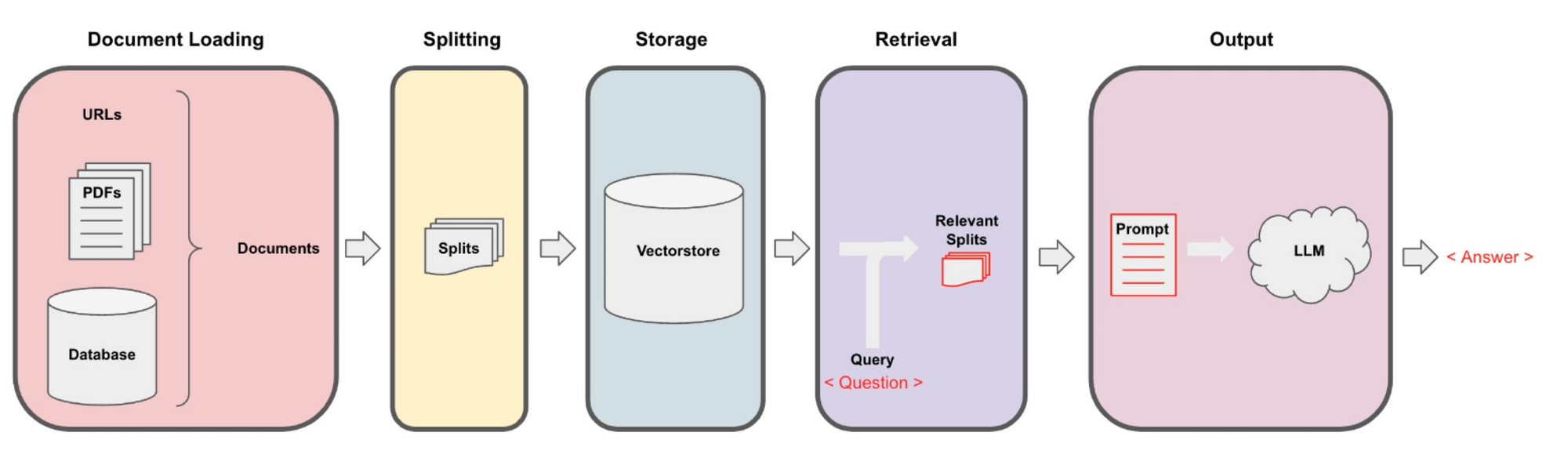
数据摄取
第一步是加载我们的数据,并以一种可以使用自然语言进行查询的方式对其进行格式化。这包括以下步骤:
- 将文档(PDF、网页或其他一些数据)拆分为语义块
- 使用嵌入模型创建每个块的向量表示
- 将块和向量加载到称为向量数据库的专用数据库中
这些初始步骤需要几个组件:文本拆分器、嵌入模型和向量数据库。幸运的是,所有这些都已存在于浏览器友好的 JS 中!
LangChain 负责文档加载和拆分。对于嵌入,我使用了小型 HuggingFace 嵌入模型,该模型经过量化,可以使用 Xenova 的 Transformers.js 包在浏览器中运行;对于向量数据库,我使用了名为 Voy 的非常简洁的 Web Assembly 向量数据库。
检索和生成
现在我已经设置好加载数据的管道,下一步就是查询数据
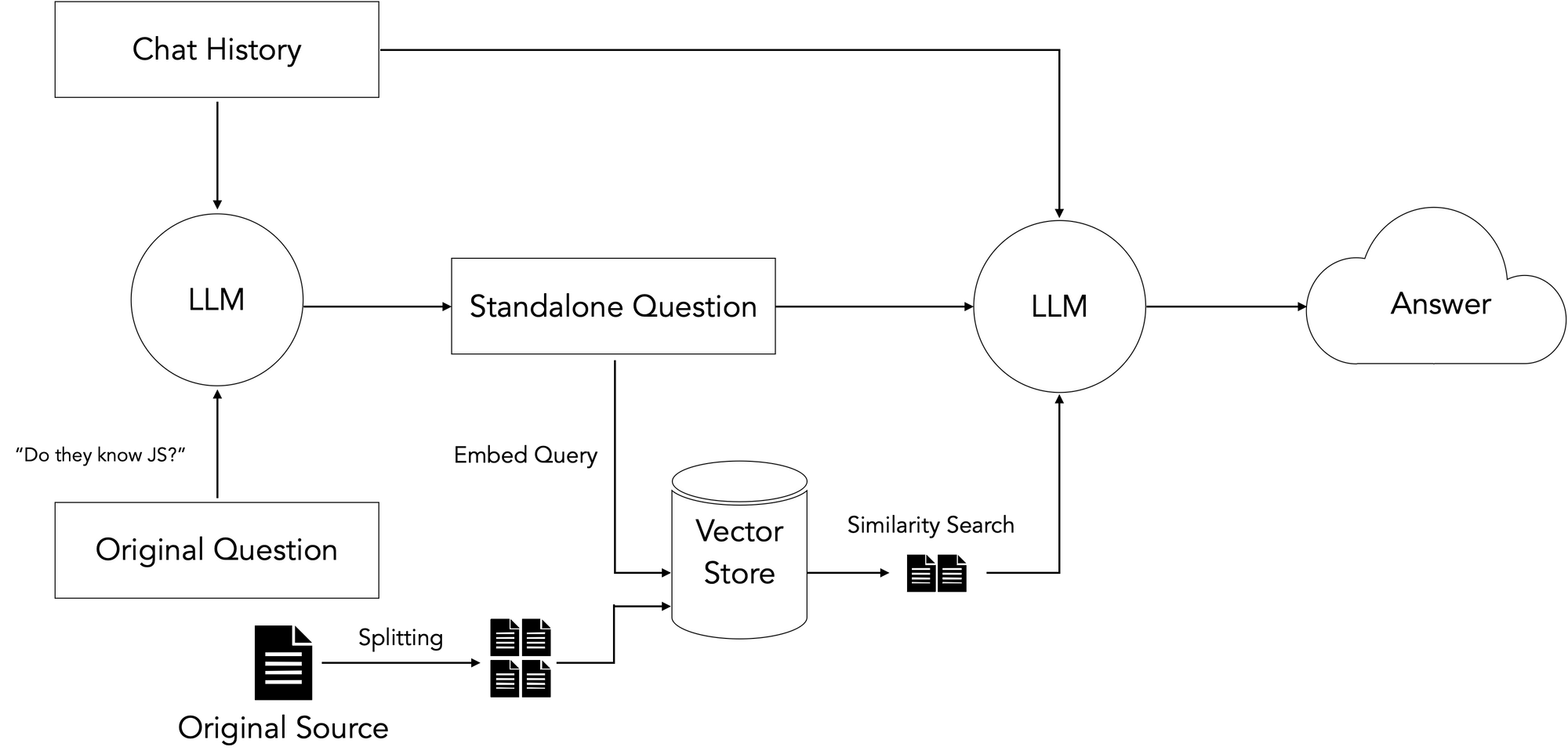
这里的一般思路是获取用户输入的问题,在我们准备好的向量数据库中搜索与查询在语义上最相似的文档块,并使用检索到的块加上原始问题来指导 LLM 基于我们的输入数据生成最终答案。
对于后续问题,还需要一个额外的步骤,这些问题可能包含代词或其他对先前聊天记录的引用。由于向量数据库通过语义相似性执行检索,因此这些引用可能会干扰检索。因此,我们添加了一个额外的解引用步骤,将初始步骤重新措辞为“独立”问题,然后再使用该问题搜索我们的向量数据库。
事实证明,找到可以在浏览器中运行的 LLM 非常困难 - 强大的 LLM 非常庞大,而通过 HuggingFace 提供的 LLM 无法生成良好的响应。还有 Machine Learning Compilation 的 WebLLM 项目,该项目看起来很有希望,但需要在页面加载时进行大规模的数 GB 下载,这增加了大量的延迟。

我过去曾尝试使用 Ollama 作为一种简单、开箱即用的方式来运行本地模型,当我听说它支持通过 shell 命令将本地运行的模型暴露给 Web 应用时,我感到惊喜。我将其插入后,发现它正是缺失的一环!我启动了更新、更先进的 Mistral 7B 模型,该模型在我的 16GB M2 Macbook Pro 上运行流畅,最终得到了以下本地堆栈:
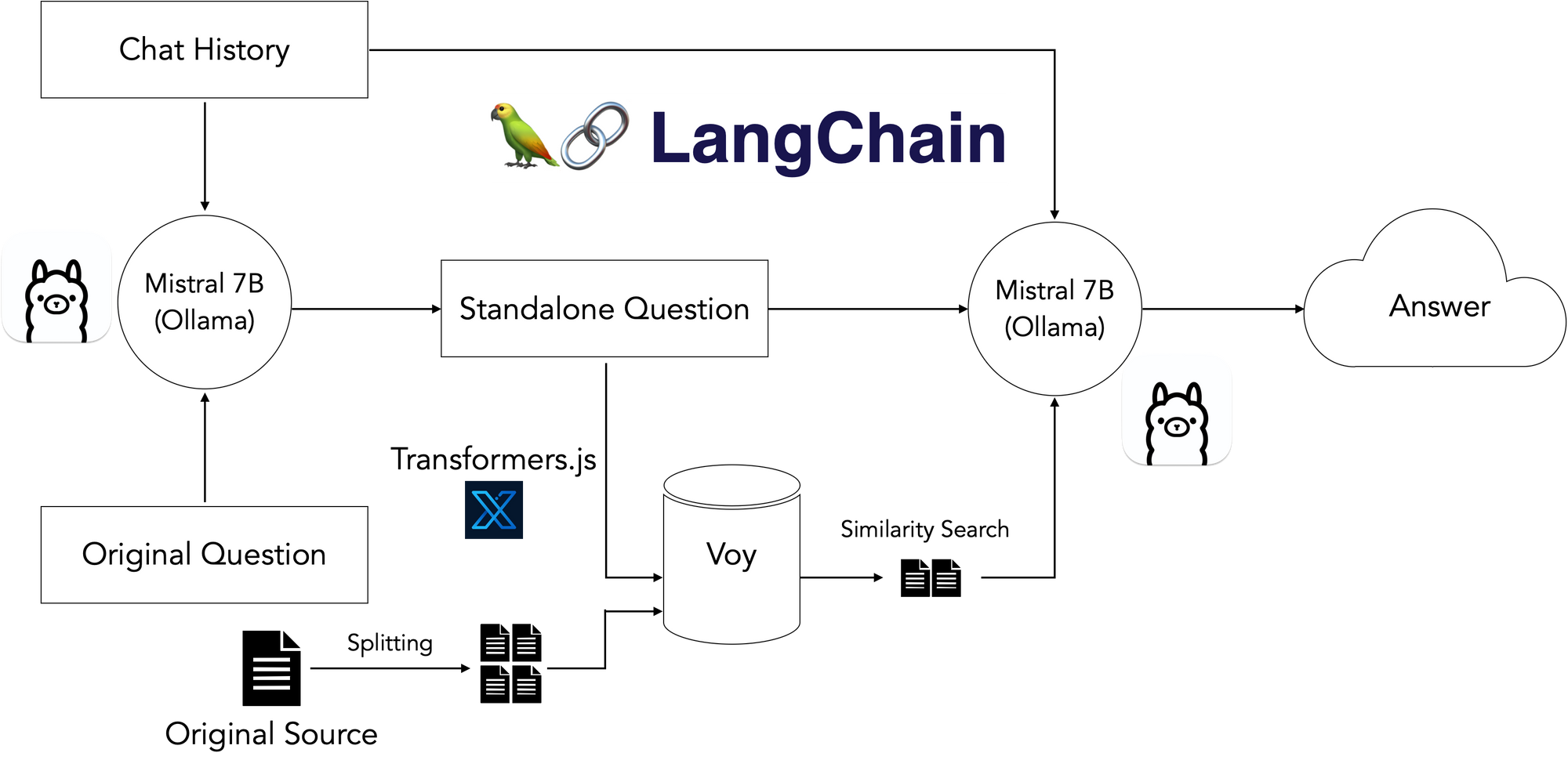
结果
您可以在 Vercel 上试用 Next.js 应用的实时版本:此处。
您需要在本地机器上通过 Ollama 运行 Mistral 实例,并通过运行以下命令使其可供相关域访问,以避免 CORS 问题:
$ ollama run mistral
$ OLLAMA_ORIGINS=https://webml-demo.vercel.app OLLAMA_HOST=127.0.0.1:11435 ollama serve它的另一个不同之处在于它使用了机密计算,这意味着即使是他们的匿名化服务也无法访问原始数据;对于寻求隐私的用户来说,这是一个很棒的功能。最后,它将在从 LLM 获得响应后对数据进行去匿名化处理,以便用户获得包含他们提及/请求的原始实体的答案。
以下是在 LangSmith(我们的可观测性和跟踪平台)中针对几个问题的一些示例跟踪。我使用了我的个人简历作为输入文档:
- “这是关于谁的?”
- “他们懂 JavaScript 吗?”
结论
总的来说,效果很好。以下是一些观察结果:
- 开源模型正在快速发展 - 我使用 Llama 2 构建了此应用的初始版本,而 Mistral 仅在几周后发布。
- 越来越多的消费硬件制造商在其产品中包含 GPU。
- 随着 OSS 模型变得更小更快,在本地硬件上使用 Ollama 等工具运行这些模型将变得越来越普遍。
- 虽然用于向量数据库、嵌入和其他特定任务模型的浏览器友好技术在过去几个月中取得了一些令人难以置信的进步,但 LLM 仍然太大,无法实际捆绑在 Web 应用中。
对于 Web 应用利用本地模型来说,唯一可行的解决方案似乎是我上面使用的流程,即强大的预安装 LLM 向应用公开。
新的浏览器 API?
由于非技术 Web 终端用户不会习惯于运行 shell 命令,因此这里最好的答案似乎是新的浏览器 API,Web 应用可以通过该 API 请求访问本地运行的 LLM,例如通过弹出窗口,然后将该功能与其他浏览器内特定任务模型和技术结合使用。

感谢您的阅读!
我对 LLM 驱动的 Web 应用的未来以及 Ollama 和 LangChain 等技术如何促进令人难以置信的全新用户互动感到非常兴奋。
以下是应用中使用的各种组件的链接:
- 演示应用:https://webml-demo.vercel.app/
- 演示应用 GitHub 仓库:https://github.com/jacoblee93/fully-local-pdf-chatbot
- Voy: https://github.com/tantaraio/voy
- Ollama: https://github.com/jmorganca/ollama/
- LangChain.js: https://js.langchain.ac.cn/
- Transformers.js: https://hugging-face.cn/docs/transformers.js/index
如果您想保持联系,可以在 X(前身为 Twitter)上关注我 @Hacubu 和 LangChain @LangChainAI。