关键链接
动机
代码生成和分析是 LLM 最重要的两个应用,例如 GitHub co-pilot 等产品的普及就证明了这一点,以及 GPT-engineer 等项目的流行。最近的 AlphaCodium 工作表明,使用 flow 范式而不是简单的 prompt:answer 范式可以改进代码生成:答案可以通过以下方式迭代构建:(1) 测试答案,以及 (2) 反思这些测试的结果,以改进解决方案。
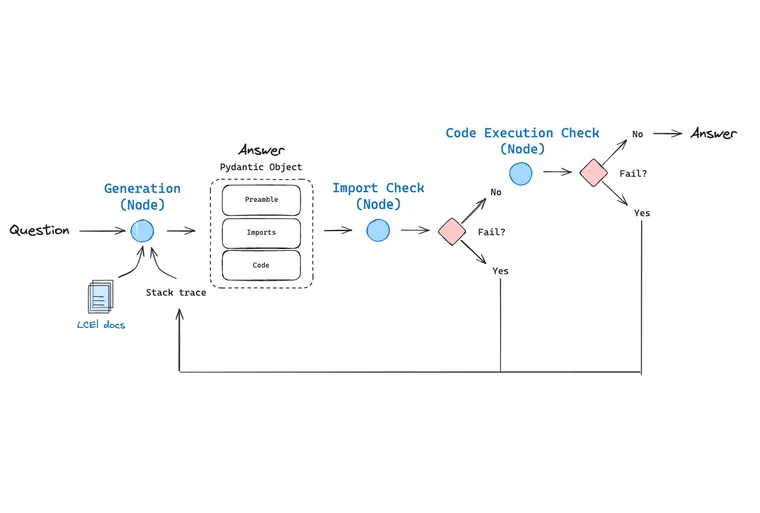
我们最近推出了 LangGraph 以支持流程工程,使用户能够将流程表示为图形。受 AlphaCodium 和 Reflexion 工作的启发,我们希望证明 LangGraph 可以用于实现代码生成,并具有与上面所示相同类型的循环和决策点。
具体来说,我们想构建和比较两种不同的架构
- 通过提示和上下文填充的代码生成
- 代码生成流程,包括检查和运行代码,然后在出现错误时将其返回以进行自我纠正
这将尝试回答:这些代码检查能在多大程度上提高代码生成系统的性能?
答案是?
问题
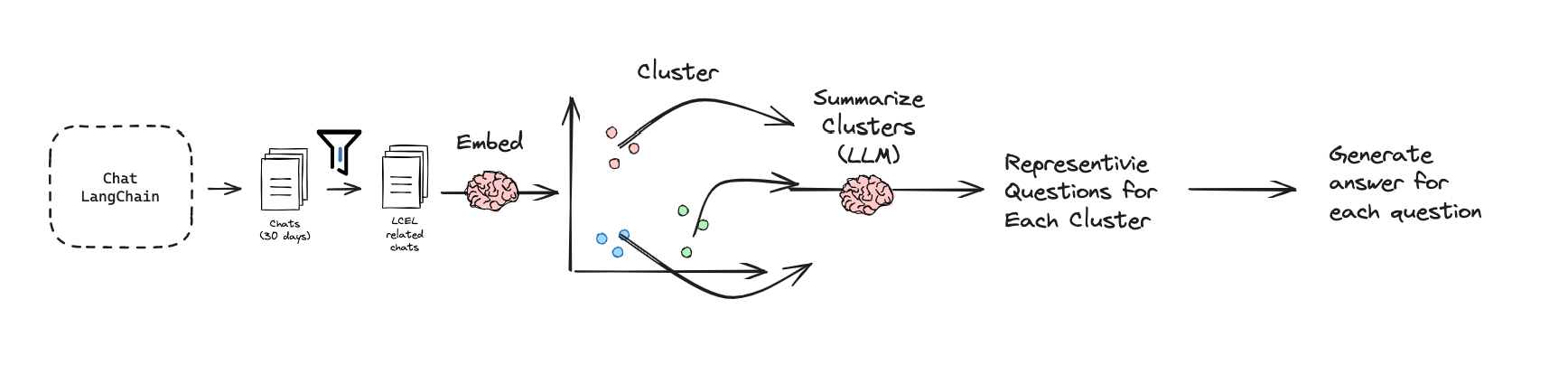
为了在一个狭窄的文档语料库上演示代码生成,我们选择了 LangChain 文档的一个子集,重点关注 LangChain 表达式语言 (LCEL),它既是有限的(约 6 万个 token),又是高度关注的主题。我们挖掘了 30 天的 chat-langchain 中与 LCEL 相关的问题(代码 在此处)。我们筛选了提到 LCEL 的问题,从 >6 万个聊天记录到 ~500 个。我们对这约 500 个问题进行了聚类,并使用 LLM (GPT-4, 128k) 总结聚类,以便为我们提供每个聚类的代表性问题。我们手动审查并为每个问题生成了标准答案(包含 20 个问题的评估集 在此处)。我们将 此数据集 添加到了 LangSmith。
使用 LangGraph 进行带反思的代码生成
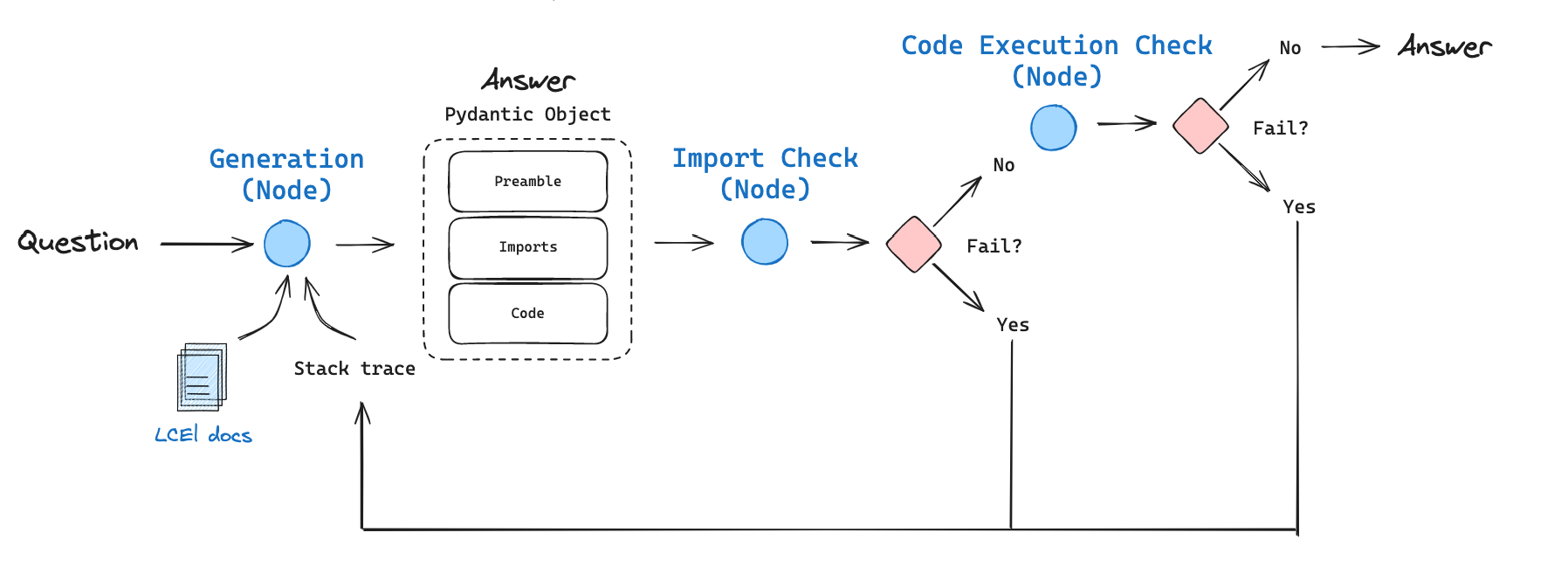
我们实现了一个包含以下组件的代码生成流程
- 受近期 趋势 长上下文 LLM 的启发,我们使用 GPT-4 和 128k token 的上下文窗口对 6 万个 token 的 LCEL 文档进行了上下文填充。我们将一个关于 LCEL 的问题传递给我们的上下文填充 LCEL 链,以进行初始答案生成。
- 我们使用 OpenAI 工具将 输出解析 为包含三个部分的 Pydantic 对象:(1) 描述问题的序言,(2) 导入块,(3) 代码。
- 我们首先检查 import 执行,因为我们 发现 幻觉可能会在代码生成期间悄悄进入导入语句。
- 如果 import 检查通过,我们然后检查代码本身是否可以执行。在生成提示中,我们指示 LLM 不要在代码解决方案中使用伪代码或未定义的变量,这应该会产生可执行代码。
- 重要的是,如果任何一项检查失败,我们会将堆栈跟踪以及之前的答案传递回生成节点以 反思。我们允许重试 3 次(仅作为默认值),但当然可以根据需要扩展。
使用 LangSmith 进行评估
作为基线,我们实现了不带 LangGraph 的 上下文填充,这是我们图中没有检查或反馈的第一个节点:我们使用 GPT-4 和 128k token 的上下文窗口对 6 万个 token 的 LCEL 文档进行了上下文填充。我们将一个关于 LCEL 的问题传递给我们的上下文填充 LCEL 链,以进行答案生成。
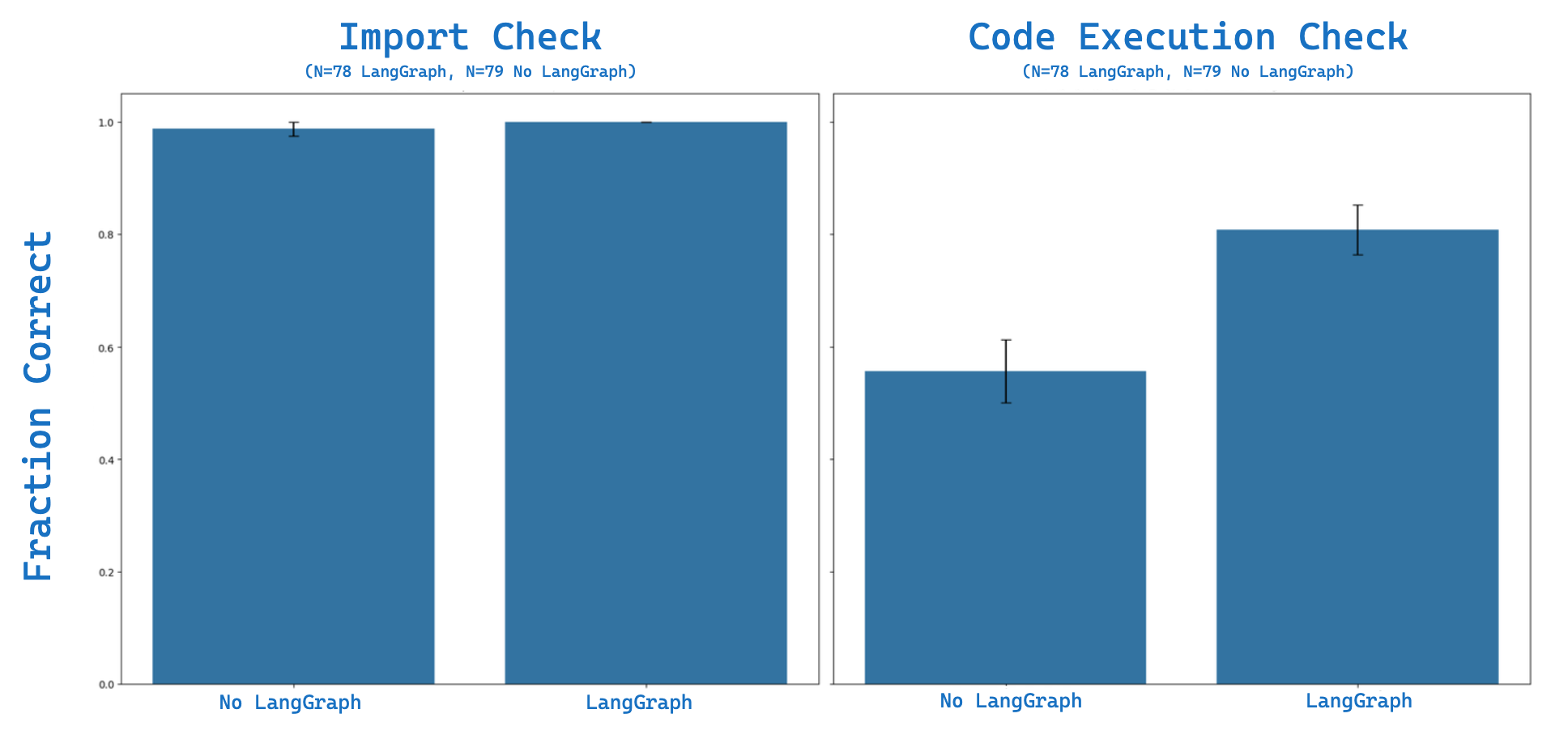
我们为 (1) 导入评估和 (2) 代码执行实现了 LangSmith 自定义评估器。我们使用包含 20 个问题的评估集对 上下文填充 进行了四次评估。 这是 我们的评估结果。使用 上下文填充,我们看到约 ~98% 的导入测试是正确的,约 ~55% 的代码执行测试是正确的(N=79 次成功试验)。我们使用 LangSmith 查看我们的失败案例:这是一个 示例,它未能识别出 RunnableLambda 函数的输入将是一个 dict,并认为它是一个 string:AttributeError: 'dict' object has no attribute 'upper'
然后,我们测试了 上下文填充 + LangGraph,以 (1) 对导入和代码执行中的此类错误执行检查,以及 (2) 反思 在执行更新的答案生成时反思任何错误。在相同的评估集上,我们看到 100% 的导入测试是正确的,约 ~81% 的代码执行测试是正确的(N=78 次试验)。
我们可以重新审视上面的失败案例以说明原因:完整的 跟踪记录 显示,在第二次尝试回答问题时,我们
You previously tried to solve this problem.
...
--- Most recent run error ---
Execution error: 'dict' object has no attribute 'upper'
...
Please re-try to answer this.
...最终生成 然后正确处理了 RunnableLambda 函数中的输入 dict,绕过了在 上下文填充 基线案例中观察到的错误。总的来说,添加这个简单的反思步骤并使用 LangGraph 进行重试,在代码执行方面取得了显著的改进,~47% 的改进
结论
LangGraph 使构建具有各种循环和决策点的流程变得容易。 最近的工作 表明,这对于代码生成非常强大,在代码生成中,可以通过迭代方式构建编码问题的答案,使用测试来检查答案,反思 失败,并迭代改进答案。我们展示了这可以在 LangGraph 中实现,并在 20 个与 LCEL 相关的问题上针对代码导入和执行进行了测试。我们发现,带有反思的 上下文填充 + LangGraph 相对于 上下文填充 在代码执行方面取得了 ~47% 的改进。笔记本 在此处,并且可以轻松扩展到其他代码库。