
重要链接
反思是一种提示策略,用于提高代理和类似 AI 系统的质量和成功率。它包括提示 LLM 反思和批判其过去的行动,有时还会结合额外的外部信息,例如工具观察结果。
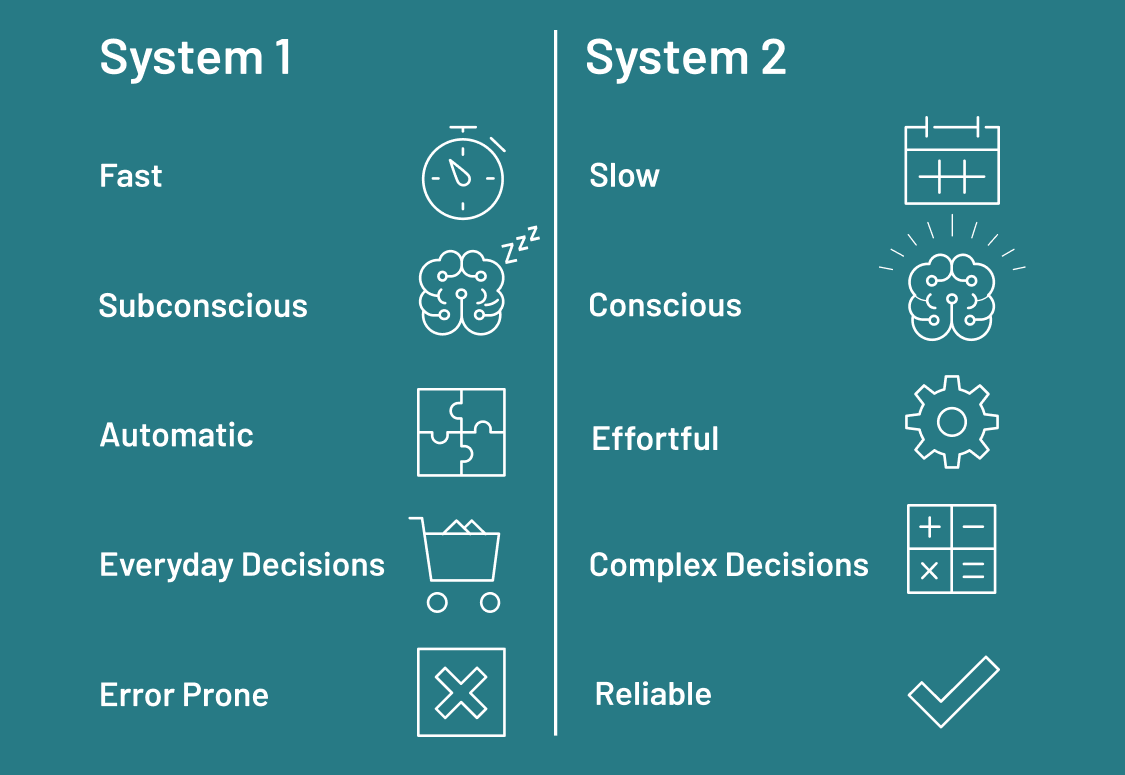
人们喜欢谈论“系统 1”和“系统 2”思维,其中系统 1 是反应性或本能的,而系统 2 更具条理性和反思性。当正确应用时,反思可以帮助 LLM 系统摆脱纯粹的系统 1“思维”模式,更接近表现出类似系统 2 的行为。
反思需要时间!这篇文章中的所有方法都牺牲了一些额外的计算量,以换取更好的输出质量的机会。虽然这可能不适用于低延迟应用程序,但对于知识密集型任务来说,如果响应质量比速度更重要,那么这是值得的。
以下概述了三个示例
基本反思
这个简单的例子组合了两个 LLM 调用:一个生成器和一个反思器。生成器尝试直接响应用户的请求。反思器被提示扮演教师的角色,并为初始响应提供建设性的批评。
循环进行固定次数,并返回最终生成的输出。

我们可以在下面的 LangGraph 中定义循环
from langgraph.graph import MessageGraph
builder = MessageGraph()
builder.add_node("generate", generation_node)
builder.add_node("reflect", reflection_node)
builder.set_entry_point("generate")
def should_continue(state: List[BaseMessage]):
if len(state) > 6:
return END
return "reflect"
builder.add_conditional_edges("generate", should_continue)
builder.add_edge("reflect", "generate")
graph = builder.compile()MessageGraph 表示一个有状态的图,其中“状态”只是消息列表。每次调用生成器或反思器节点时,它都会在状态末尾附加一条消息。最终结果从生成器节点返回。
这种简单的反思类型有时可以通过让 LLM 多次尝试改进其输出,以及让反思节点在批评输出时采用不同的角色来提高性能。
但是,由于反思步骤没有基于任何外部过程,因此最终结果可能不会比最初的结果好很多。让我们探索一些其他可以改善这种情况的技术。
Reflexion
Reflexion 由 Shinn 等人提出,是一种旨在通过口头反馈和自我反思进行学习的架构。在 Reflexion 中,actor 代理明确地批评每个响应,并将其批评建立在外部数据之上。它被强制生成引文,并明确列举生成的响应中多余和缺失的方面。这使得反思的内容更具建设性,并更好地引导生成器响应反馈。
在链接的示例中,我们在固定步数后停止,但您也可以将此决定卸载到反思 LLM 调用。
代理循环的概述如下所示

对于每个步骤,responder 的任务是生成响应,以及搜索查询形式的附加操作。然后提示 revisor 反思当前状态。逻辑可以在 LangGraph 中定义如下
from langgraph.graph import END, MessageGraph
MAX_ITERATIONS = 5
builder = MessageGraph()
builder.add_node("draft", first_responder.respond)
builder.add_node("execute_tools", execute_tools)
builder.add_node("revise", revisor.respond)
# draft -> execute_tools
builder.add_edge("draft", "execute_tools")
# execute_tools -> revise
builder.add_edge("execute_tools", "revise")
# Define looping logic:
def event_loop(state: List[BaseMessage]) -> str:
# in our case, we'll just stop after N plans
num_iterations = _get_num_iterations(state)
if num_iterations > MAX_ITERATIONS:
return END
return "execute_tools"
# revise -> execute_tools OR end
builder.add_conditional_edges("revise", event_loop)
builder.set_entry_point("draft")
graph = builder.compile()该代理可以有效地使用显式反思和基于网络的引文来提高最终响应的质量。但是,它只追求一个固定的轨迹,因此如果它犯了一个错误,该错误可能会影响后续的决策。
Language Agent Tree Search
Language Agent Tree Search (LATS),由 Zhou 等人提出,是一种通用的 LLM 代理搜索算法,它结合了反思/评估和搜索(特别是蒙特卡洛树搜索),以实现比 ReACT、Reflexion 甚至 Tree of Thoughts 等类似技术更好的整体任务性能。它采用了标准的强化学习 (RL) 任务框架,将 RL 代理、价值函数和优化器都替换为对 LLM 的调用。这旨在帮助代理适应和解决复杂任务,避免陷入重复循环。
搜索过程在下图中概述

搜索有四个主要步骤
- 选择:根据步骤 (2) 中的汇总奖励选择最佳的下一步行动。响应(如果找到解决方案或达到最大搜索深度)或继续搜索。
- 扩展和模拟:生成 N 个(在本例中为 5 个)潜在的行动并并行执行它们。
- 反思 + 评估:观察这些行动的结果,并根据反思(以及可能的外部反馈)对决策进行评分
- 反向传播:根据结果更新根轨迹的分数。
如果代理具有紧密的反馈循环(通过高质量的环境奖励或可靠的反思分数),则搜索能够准确区分不同的行动轨迹并选择最佳路径。然后可以将最终轨迹保存到外部存储器(或用于模型微调),以在未来改进模型。
“选择”步骤选择具有最高置信上限 (UCT) 的节点,它只是平衡了预期奖励(第一项)和探索新路径的激励(第二项)。
\( UCT = \frac{\text{value}}{\text{visits}} + c \sqrt{\frac{\ln(\text{parent.visits})}{\text{visits}}}\)
查看代码以了解它是如何实现的。在我们的 LangGraph 实现中,我们将生成 + 反思步骤放在每个单独的节点中,并在每个循环中检查树状态,以查看任务是否已解决。(缩写的)图定义如下所示
from langgraph.graph import END, StateGraph
class Node:
def __init__(
self,
messages: List[BaseMessage],
reflection: Reflection,
parent: Optional[Node] = None,
):
self.messages = messages
self.parent = parent
self.children = []
self.value = 0
self.visits = 0
# Additional methods are defined here. Check the code for more!
class TreeState(TypedDict):
# The full tree
root: Node
# The original input
input: str
def should_loop(state: TreeState):
"""Determine whether to continue the tree search."""
root = state["root"]
if root.is_solved:
return END
if root.height > 5:
return END
return "expand"
builder = StateGraph(TreeState)
builder.add_node("start", generate_initial_response)
builder.add_node("expand", expand)
builder.set_entry_point("start")
builder.add_conditional_edges(
"start",
# Either expand/rollout or finish
should_loop,
)
builder.add_conditional_edges(
"expand",
# Either continue to rollout or finish
should_loop,
)
graph = builder.compile()LATS 图
一旦您创建了基本轮廓,就很容易扩展到其他任务!例如,这项技术非常适合代码生成任务,在代码生成任务中,您可以让代理编写显式的单元测试,并根据测试质量对轨迹进行评分。
LATS 统一了其他代理架构(例如 Reflexion、Tree of Thoughts 和plan-and-execute 代理)的推理、规划和反思组件。LATS 还从反思和基于环境的反馈的反向传播中获益,从而改进了搜索过程。虽然它可能对奖励分数敏感,但通用算法可以灵活地应用于各种任务。

视频教程
结论
感谢阅读!所有这些示例都可以在 LangGraph 存储库中找到,我们将很快将它们移植到 LangGraphJS(可能在您阅读这篇文章时)。
上述所有技术都利用额外的 LLM 推理来增加生成更高质量输出或正确响应更复杂推理任务的可能性。虽然这需要额外的时间,但当输出质量比响应时间更重要时,并且如果您将轨迹保存到内存(或作为微调数据),您可以更新模型以避免将来重复犯错。