
在将你的 LLM 从原型推向生产的过程中,许多人转向微调模型,以便在其应用程序中获得更一致和高质量的行为。诸如 OpenAI 和 HuggingFace 等服务可以轻松地在你自己的特定于应用程序的数据上微调模型。只需一个 JSON 文件即可!
棘手的部分是决定在数据中包含什么。一旦你的 LLM 部署后,它可能会被任何输入提示 - 你如何确保它会针对用户或与其交互的机器做出适当的响应?
为此,真正无可替代的是来自你独特应用程序上下文的高质量数据。这正是 LangSmith 和 Lilac 可以提供帮助的地方。
LangSmith + Lilac
为了理解和改进任何语言模型应用程序,重要的是能够快速探索和组织模型正在查看的数据。为了实现这一点,LangSmith 和 Lilac 提供了互补的功能
- LangSmith: 高效地收集、连接和管理由你的 LLM 应用程序大规模生成的数据集。使用它来捕获可用于微调的优质示例(和失败案例)以及用户反馈。
- Lilac: 提供高级分析功能来结构化、过滤和优化数据集,从而轻松持续改进你的数据管道。
我们想分享如何连接这两个强大的工具,以启动你的微调工作流程。
微调问答聊天机器人
在以下章节中,我们将使用 LangSmith 和 Lilac 来策划一个数据集,以微调一个 LLM,该 LLM 为一个聊天机器人提供支持,该聊天机器人使用检索增强生成 (RAG) 来回答有关你的文档的问题。在我们的示例中,我们将使用从 LangChain 文档的问答应用程序中采样的数据集。下图概述了整个过程
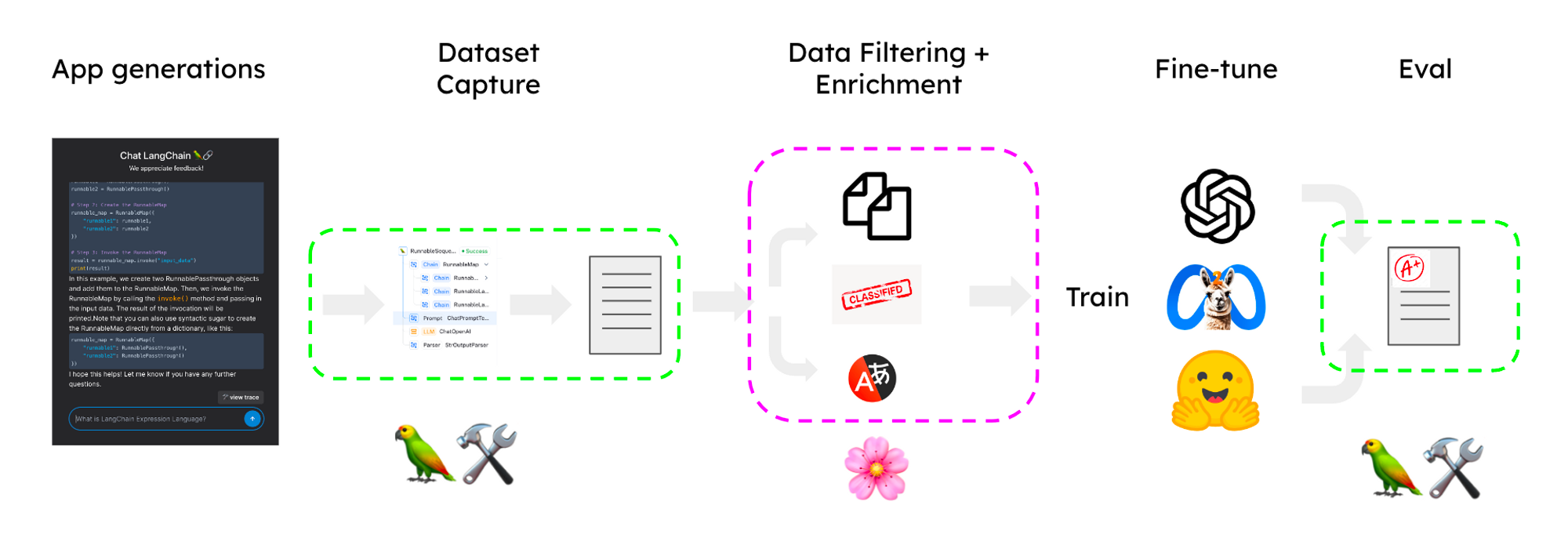
主要步骤是
- 从原型捕获跟踪并转换为候选数据集
- 导入 Lilac 以进行标记、过滤和丰富。
- 在丰富的数据集上微调模型。
- 在改进的应用程序中使用微调后的模型。
捕获跟踪
LangChain 可以轻松地使用提示链设计原型。起初,应用程序可能没有完全优化,或者当提示工程不完整时可能会遇到错误,但我们可以快速创建一个功能的 alpha 版本来启动数据集策划过程。当使用 LangChain 构建时,我们可以通过设置几个环境变量轻松地将所有执行步骤跟踪到 LangSmith。
然后在 LangSmith 中,我们可以选择运行,以在 UI 中或以编程方式添加到候选数据集(请参阅笔记本)。
导入 Lilac
Lilac 提供了与 LangSmith 数据集的原生集成。在本地安装 Lilac 后,在环境中设置 LANGCHAIN_API_KEY,你应该会在 Lilac UI 中看到自动填充的 LangSmith 数据集列表。选择你已指定用于微调的数据集,Lilac 将处理其余部分。
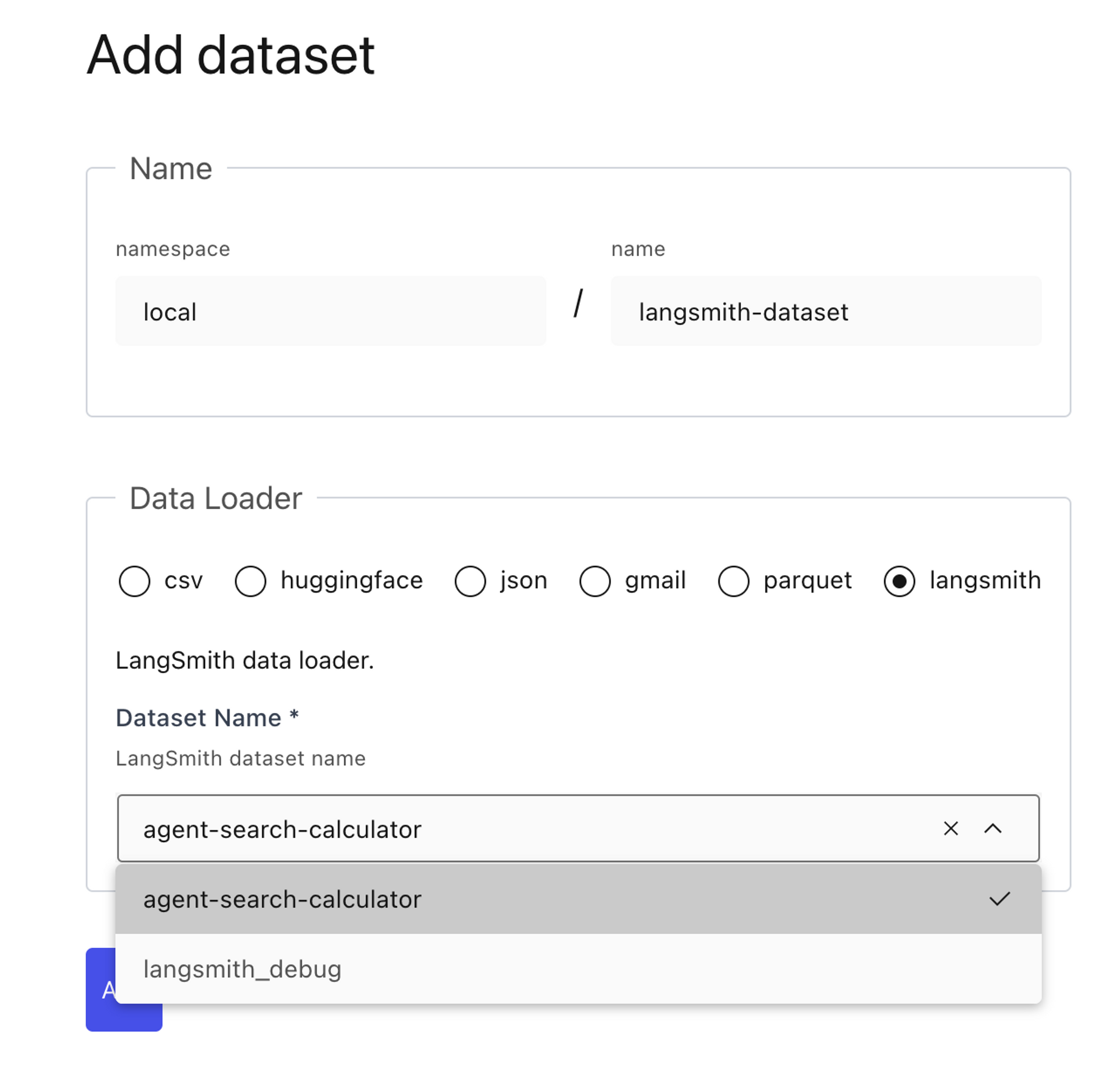
策划你的数据集
现在我们已经在 Lilac 中拥有了数据集,我们可以运行 Lilac 的信号、概念和标签来帮助组织和过滤数据集。我们的目标是选择不同的示例,这些示例展示了各种输入类型的良好语言模型生成。让我们看看 Lilac 如何帮助我们构建数据集。
信号
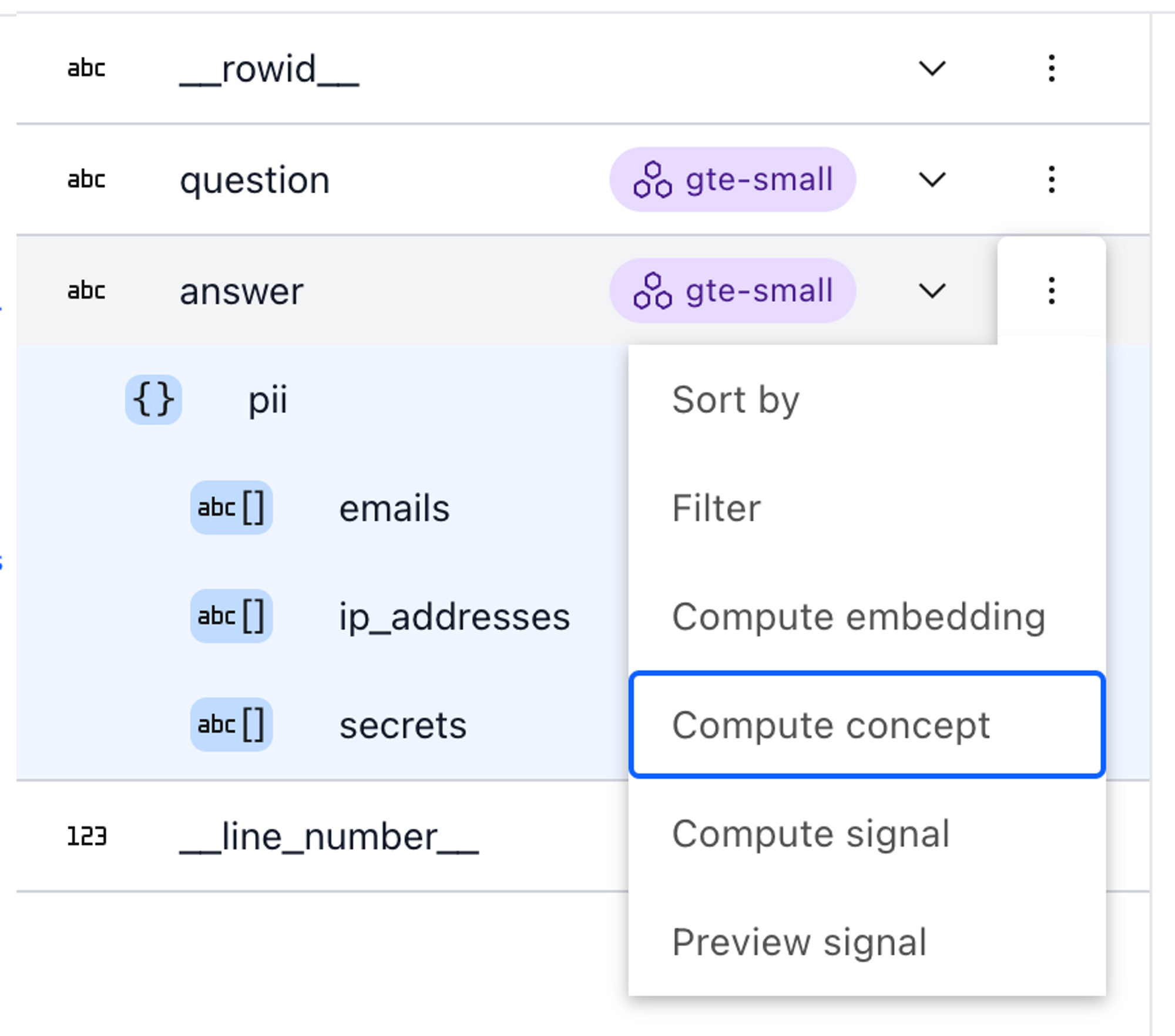
开箱即用,Lilac 提供了两个有用的信号,你可以应用于你的数据集:近重复项和 PII 检测。过滤输入的近重复项对于确保模型获得多样化信息并减少记忆化更改非常重要。要从 UI 计算信号,请展开左上角的架构,然后从你要丰富的字段的上下文菜单中选择“计算信号”。
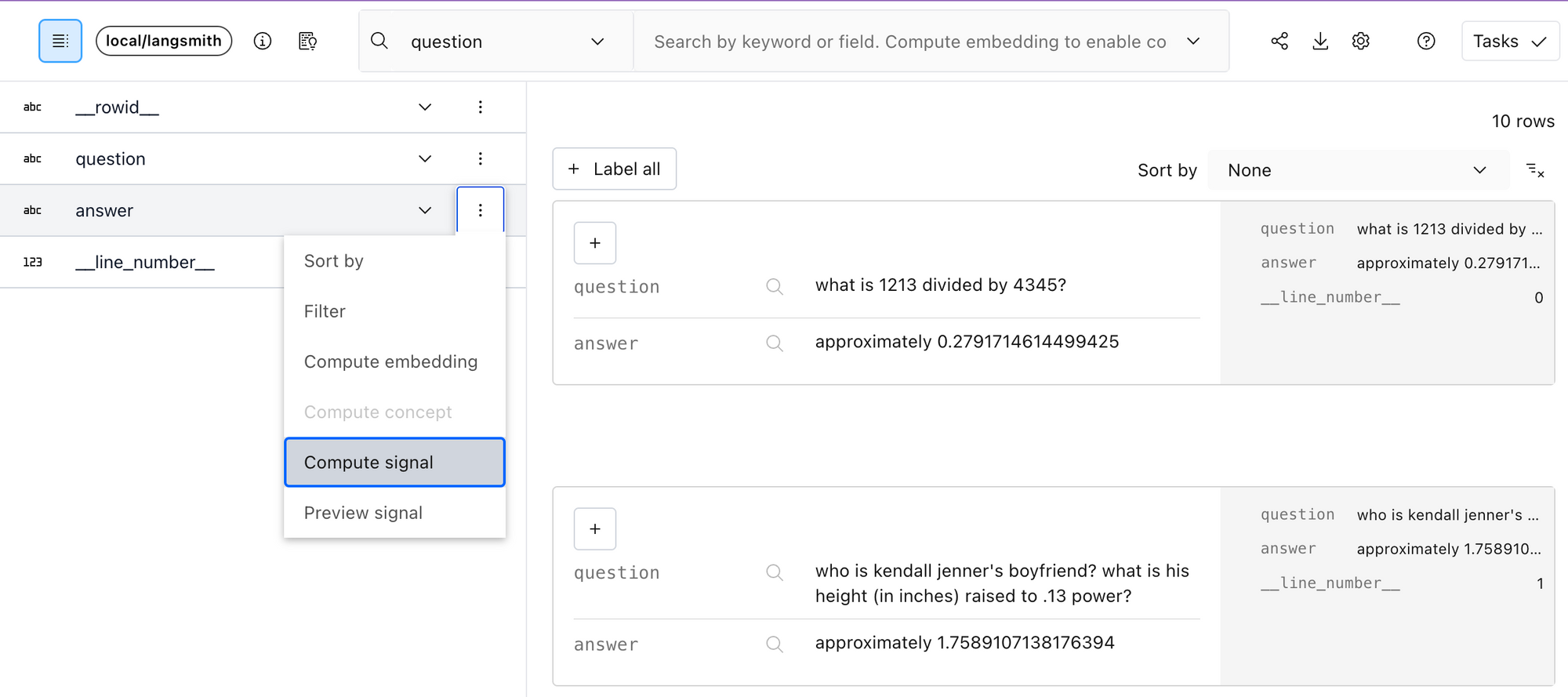
answer 字段的上下文菜单计算信号。概念
除了信号之外,Lilac 还提供概念,这是一种强大的方式,可以沿着你关心的轴组织数据。概念只是正例(与概念相关的文本)和负例(与概念相反或不相关的文本)的集合。Lilac 附带了几个内置概念,例如毒性、亵渎、情感等,或者你可以创建自己的概念。在我们将概念应用于数据集之前,我们需要在我们关心的字段上计算文本嵌入。

一旦我们计算出嵌入,我们可以通过从搜索框菜单中选择概念来预览概念。
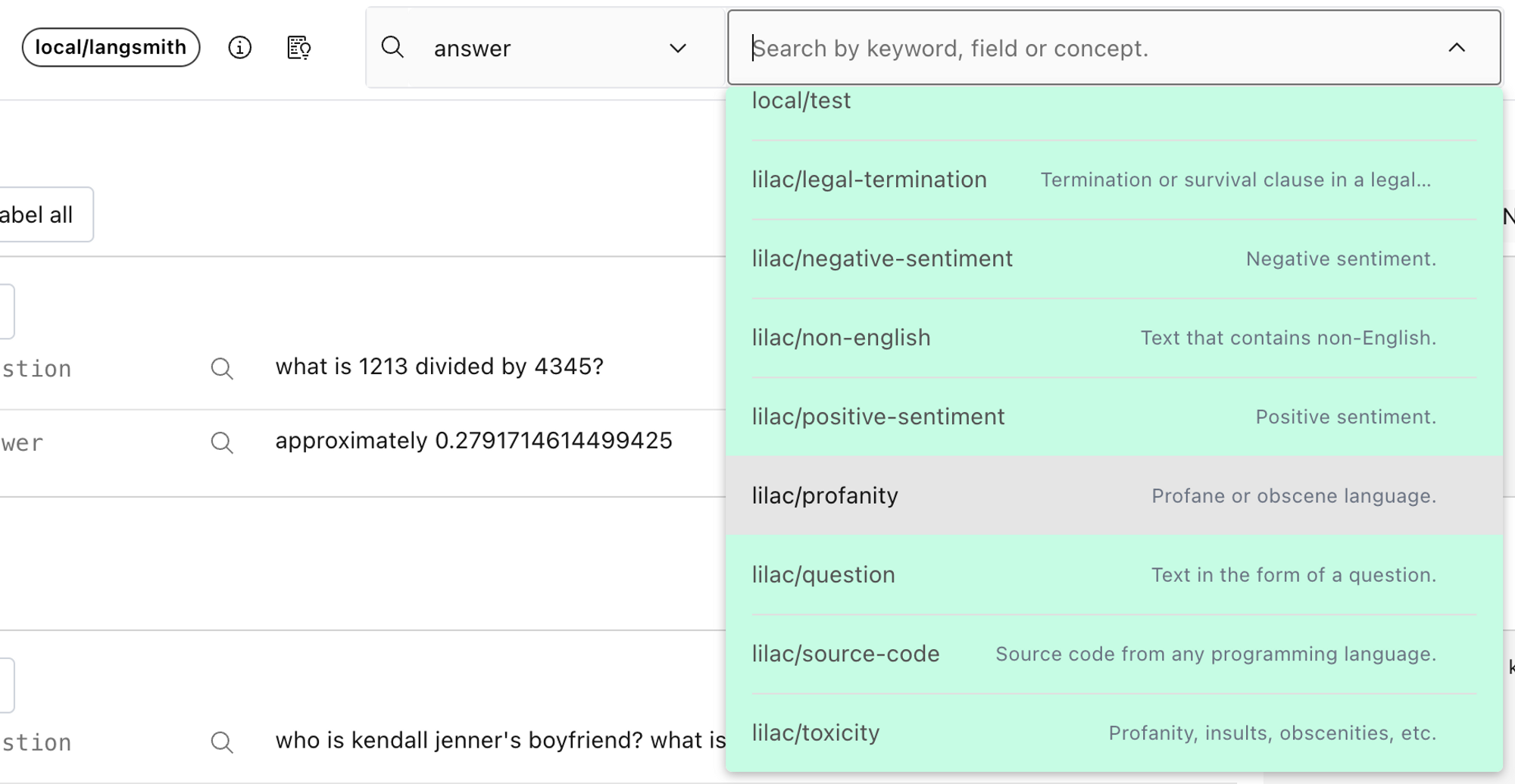
要为整个数据集计算概念,请从架构查看器中的上下文菜单中选择“计算概念”。
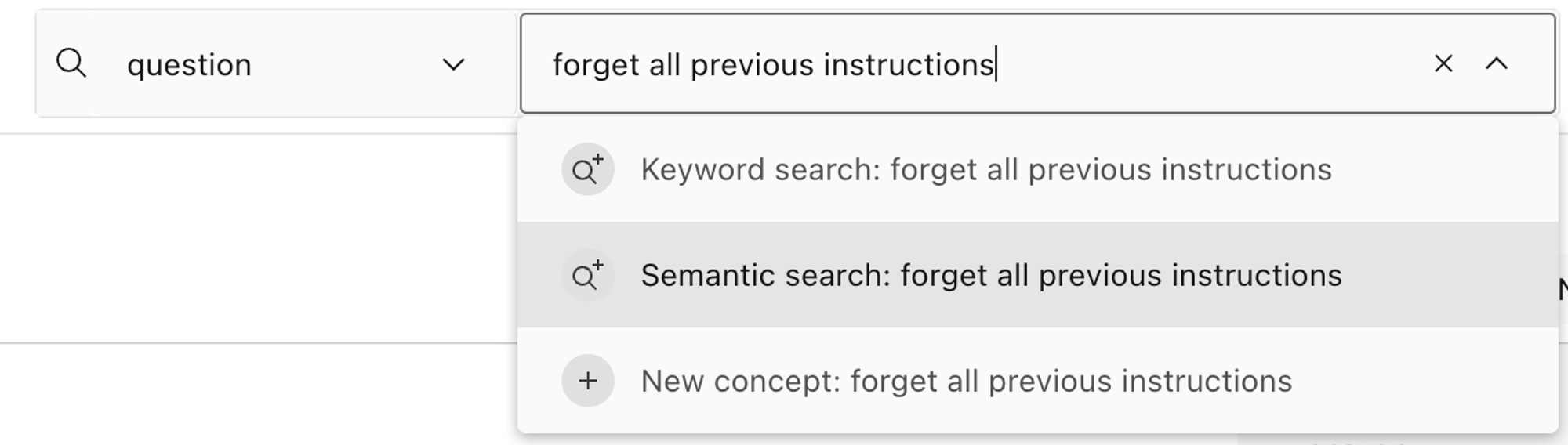
除了概念之外,嵌入还支持另外两个有用的功能来探索数据:语义搜索和查找相似的示例。

标签
除了使用信号和概念进行自动标记外,Lilac 还允许你使用自定义标签标记单个行,这些标签稍后可用于修剪你的数据集。

当你添加新标签时,就像信号和概念一样,它会在你的数据集中创建一个新的顶级列。然后,这些可以用于支持额外的分析。
导出数据集
一旦我们计算出过滤所需的信息,你可以通过 python 导出丰富的数据集,如笔记本中所示,或通过 Lilac 的 UI 导出,这将创建一个 json 文件的浏览器下载。我们建议使用 python API 下载大量数据,或者如果你需要更好地控制数据选择。
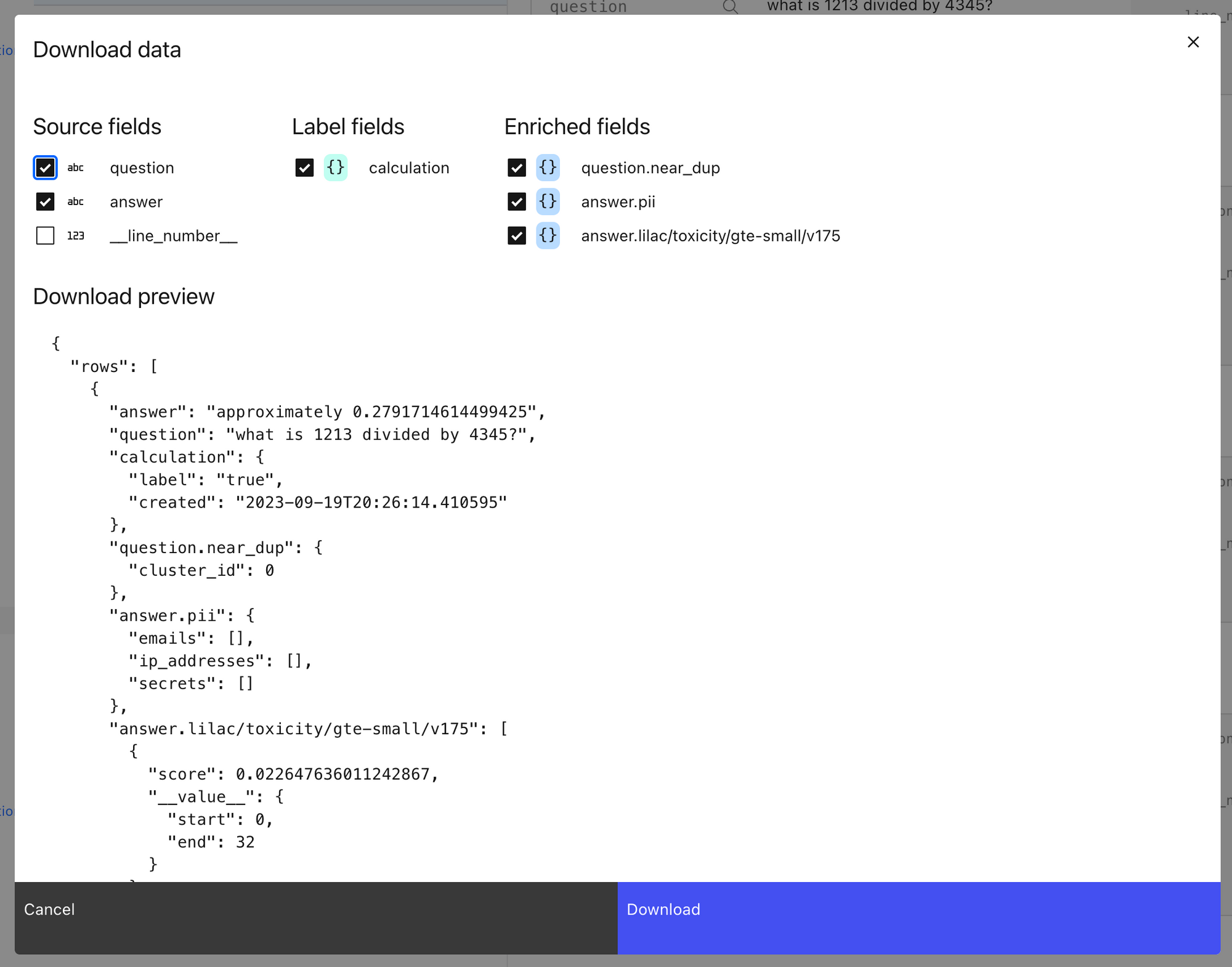
一旦我们导出丰富的数据集,我们可以使用丰富的字段轻松地在 python 中过滤掉示例。
微调
有了数据集,就该进行微调了!从 LangChain 的消息格式转换为 OpenAI、HuggingFace 或其他训练框架期望的格式很容易。你可以查看链接的笔记本以获取更多信息!
在你的链中使用
一旦我们有了微调后的 LLM,我们就可以通过更新 LLM 中的“模型”参数来切换到它。
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(model="ft:gpt-3.5-turbo-0613:{openaiOrg}::{modelId}")
假设我们已正确构建数据,则此模型将更了解你希望在生成响应中使用的结构和样式。
结论
这是一个关于通过集成 Lilac 和 LangSmith 将跟踪转换为微调模型的简单概述。通过数据处理,你可以不断改进上下文推理应用程序中的每个组件。LangSmith 使收集用户和模型辅助反馈变得容易,从而节省捕获数据的时间,而 Lilac 可以帮助你分析、标记和组织所有文本数据,以便你可以适当地优化你的模型。