
作者:Jacob Lee
在过去的几个月里,我有机会为一个客户做一些很酷的探索性工作,他们将像 GPT-4 和 Claude 这样的大语言模型集成到他们的内部工作流程中,而不是通过聊天界面公开它们。总体思路是获取一些输入数据,使用大语言模型对其进行分析,使用现有数据源丰富大语言模型的输出,然后使用传统工具和大语言模型对其进行健全性检查。这个过程可以重复多次,直到最终将最终结果存储在数据库中。我一直将其视为一个管道,将大语言模型与更普通的 API 混合在一起,其中一个步骤的输出直接馈送到下一步。
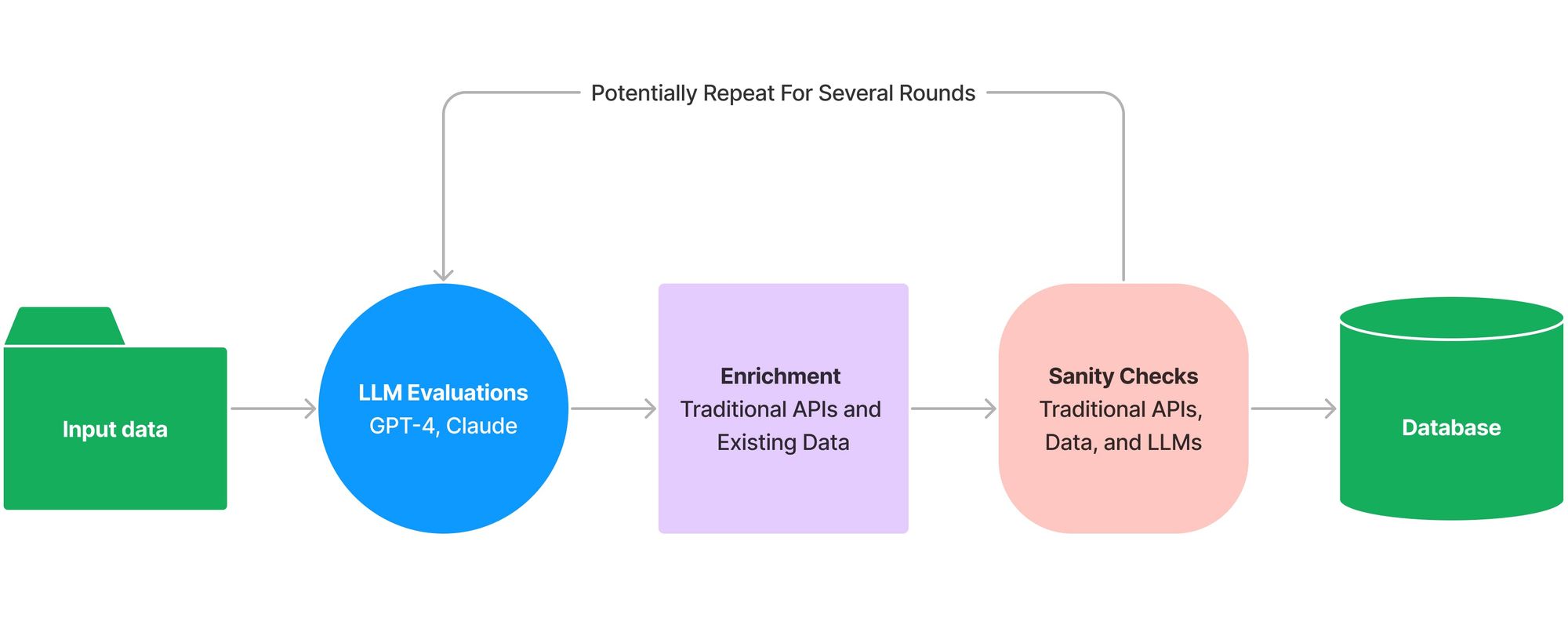
问题
在构建这样的管道时,我很快意识到,虽然自然语言是聊天机器人的绝佳界面,但对于现有 API 来说,它却很难使用。
为了说明这一点,假设您想在 Airtable 中生成并存储一个国家列表。天真地要求大语言模型给我一个包含 5 个国家的列表,结果会得到一个编号的国家列表
'1. United States\n' +
'2. Canada\n' +
'3. United Kingdom\n' +
'4. Australia\n' +
'5. Japan'
这里有一些问题 - 虽然上面的输出恰好是一个编号列表,但这并不能保证。此外,您还需要编写一些笨拙的自定义字符串解析逻辑来提取数据,以便在管道的下一步中使用。
解决方案是提示大语言模型以某种结构化格式输出数据,但这并没有那么简单。例如,询问给我一个包含 5 个国家的列表,格式为 Airtable 记录可能会得到类似这样的结果
'Airtable records require a unique ID and field values in a JSON format. Here is a list of 5 countries formatted as Airtable records:\n' +
'\n' +
'1. {\n' +
' "id": "rec1",\n' +
' "fields": {\n' +
' "Country": "United States",\n' +
' "Continent": "North America"\n' +
' }\n' +
'}\n' +
'2. {\n' +
' "id": "rec2",\n' +
' "fields": {\n' +
' "Country": "Canada",\n' +
' "Continent": "North America"\n' +
' }\n' +
'}\n' +
...
虽然大语言模型(在本例中为 GPT-4)令人印象深刻地知道 Airtable 记录的通用模式,但这甚至比最初的尝试还要糟糕。顶部有会话文本必须解析出来,并且输出格式仍然是一个编号列表。此外,大语言模型已经假定了您的 Airtable 模式的字段名称,这很可能与您的内部定义不匹配。
我尝试了一些自定义提示策略,例如仅输出包含 X、Y 和 Z 的 JSON 对象数组,但是将这样的语言添加到我的所有提示中很快变得乏味。此外,由于大语言模型的非确定性性质,特别是对于冗长、复杂的提示和较高的温度,这在某种程度上是不可靠的。
解决方案
我已经在使用 LangChainJS,这是一个开源框架,可以帮助围绕大语言模型构建复杂的应用程序,用于项目的各个部分。在询问了他们的 Discord 社区后,我发现了一个优雅的内置解决方案:输出修复解析器!
输出修复解析器包含两个组件
- 一种简单、一致的方式来生成输出格式化指令(使用流行的 TypeScript 验证框架 Zod)。
- 一种由大语言模型驱动的恢复机制,用于使用更集中的提示处理格式错误的输出。
您可以使用它来解决之前的问题,如下所示(请注意,如果您的依赖项中还没有 yarn add langchain 和 yarn add zod,则需要运行它们)
import { z } from "zod";
import { ChatOpenAI } from "langchain/chat_models/openai";
import { PromptTemplate } from "langchain/prompts";
import { LLMChain } from "langchain/chains";
import {
StructuredOutputParser,
OutputFixingParser
} from "langchain/output_parsers";
const outputParser = StructuredOutputParser.fromZodSchema(
z.array(
z.object({
fields: z.object({
Name: z.string().describe("The name of the country"),
Capital: z.string().describe("The country's capital")
})
})
).describe("An array of Airtable records, each representing a country")
);
const chatModel = new ChatOpenAI({
modelName: "gpt-4", // Or gpt-3.5-turbo
temperature: 0 // For best results with the output fixing parser
});
const outputFixingParser = OutputFixingParser.fromLLM(
chatModel,
outputParser
);
const prompt = new PromptTemplate({
template: `Answer the user's question as best you can:\n{format_instructions}\n{query}`,
inputVariables: ['query'],
partialVariables: {
format_instructions: outputFixingParser.getFormatInstructions()
}
});
// For those unfamiliar with LangChain, a class used to call LLMs
const answerFormattingChain = new LLMChain({
llm: chatModel,
prompt: prompt,
outputKey: "records", // For readability - otherwise the chain output will default to a property named "text"
outputParser: outputFixingParser
});
const result = await answerFormattingChain.call({
query: "List 5 countries."
});
console.log(JSON.stringify(result.records, null, 2));
干净且可读!这是一个结果示例
[
{
"fields": {
"Name": "United States",
"Capital": "Washington, D.C."
}
},
{
"fields": {
"Name": "Canada",
"Capital": "Ottawa"
}
},
{
"fields": {
"Name": "Germany",
"Capital": "Berlin"
}
},
{
"fields": {
"Name": "Japan",
"Capital": "Tokyo"
}
},
{
"fields": {
"Name": "Australia",
"Capital": "Canberra"
}
}
]
成功!结果已经类型化为对象数组,因此无需 JSON.parse() 调用或任何进一步的解析。
请注意,如果出于任何原因,输出修复解析器无法生成与提供的 Zod 模式匹配的输出,它将抛出错误。您甚至可以将其直接管道传输到 Airtable API 调用中!
其他提示
使用 .describe() 提供的描述是可选的,但在填充各个字段时为大语言模型提供了有用的上下文。大语言模型还将使用字段名称和提供的模式的整体结构等线索。
- 如果您在生成正确格式的输出时遇到困难,添加描述或调整这些描述中的语言可能会有所帮助。
- 您可以在输出修复解析器和您正在使用的任何链中使用不同的模型实例,从而允许您混合和匹配温度,甚至提供商,以获得最佳结果。
感谢阅读!
我希望这篇文章能帮助您更好地在您的项目中使用大语言模型的力量!
实际上,我非常喜欢使用大语言模型,特别是 LangChain 进行构建,以至于我最近加入了他们的团队,所以期待在未来几个月看到更多相关内容!如果您有任何问题或对您希望我接下来写什么有任何想法,请在 Twitter 上联系我 @Hacubu。我也将在 LangChain 社区 Discord 服务器 的 JS 频道中保持活跃。
祝您提示愉快!