
注意:这篇文章假设您已熟悉 LangChain,并且具有一定的技术性。
💡 概括:我们引入了一个新的抽象概念和一个新的文档检索器,以方便检索文档的后处理。具体来说,新的抽象概念使得从一组检索到的文档中仅提取与给定查询相关的信息变得容易。
简介
许多由 LLM 驱动的应用程序需要一些可查询的文档存储,以便检索应用程序特定的、尚未内置到 LLM 中的信息。
假设您想创建一个可以回答关于您的个人笔记的问题的聊天机器人。一种简单的方法是将您的笔记嵌入到大小相等的块中,并将嵌入存储在向量存储中。当您向系统提出问题时,它会嵌入您的问题,在向量存储上执行相似性搜索,检索最相关的文档(文本块),并将它们附加到 LLM 提示中。
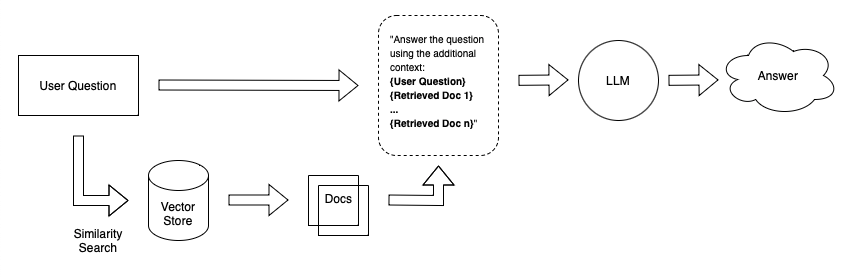
问题
这种方法的一个问题是,当您将数据摄取到文档存储系统时,您通常不知道将使用哪些特定查询来检索这些文档。在我们的笔记问答示例中,我们只是将文本划分为大小相等的块。这意味着,当我们收到特定的用户问题并检索文档时,即使文档中有一些相关的文本,也可能有一些不相关的文本。
在 LLM 提示中插入不相关的信息是不好的,因为
- 它可能会分散 LLM 对相关信息的注意力
- 它占用了宝贵的空间,而这些空间本可以用来插入其他相关信息。
解决方案
为了帮助解决这个问题,我们引入了一个 DocumentCompressor 抽象概念,它允许您在检索到的文档上运行 compress_documents(documents: List[Document], query: str)。其思想很简单:我们可以使用给定查询的上下文来压缩检索到的文档,而不是立即按原样返回检索到的文档,从而只返回相关信息。“压缩”在这里指的是压缩单个文档的内容和完全过滤掉文档。
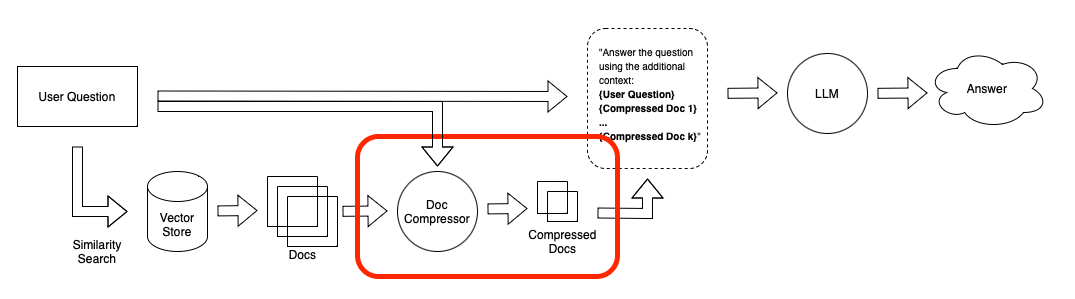
压缩器的目标是使将 仅 相关的信息传递给 LLM 变得容易。通过这样做,它还使您能够将 更多 信息传递给 LLM,因为在初始检索步骤中,您可以专注于召回率(例如,通过增加返回的文档数量),并让压缩器处理精确率。
特性
我们在 LangChain Python 包中实现了一些新特性
- 一组您可以直接使用的 DocumentCompressor。
- 一个
ContextualCompressionRetriever,它将另一个检索器与 DocumentCompressor 一起包装,并自动压缩基础检索器检索到的文档。
一些 DocumentCompressor 示例
LLMChainExtractor使用 LLMChain 从每个文档中仅提取与查询相关的语句。EmbeddingsFilter嵌入检索到的文档和查询,并过滤掉任何嵌入与嵌入查询不够相似的文档。就其本身而言,这个压缩器所做的事情与大多数 VectorStore 检索器非常相似,但作为以下组件,它变得更加有用……- ……
DocumentCompressorPipeline,它可以轻松创建转换和压缩器的管道,并按顺序运行它们。一个简单的例子是,您可能想要组合TextSplitter和EmbeddingsFilter,首先将您的文档分解成更小的片段,然后过滤掉不再相关的拆分文档。
您可以尝试将这些与任何现有的检索器(无论是基于 VectorStore 的还是其他的)一起使用,例如
from langchain.llms import OpenAI
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
# base_retriever defined somewhere above...
compressor = LLMChainExtractor.from_llm(OpenAI(temperature=0))
compression_retriever = ContextualCompressionRetriever(base_compressor=compressor, base_retriever=retriever)
contextual_retriever.get_relevant_documents("insert query here")
前往 此处 的演练开始使用!