我们认为 LangChain 表达式语言 (LCEL) 是快速构建 LLM 应用程序大脑原型的最佳方式。下一步激动人心的步骤是将它交付给您的用户并获得一些反馈!今天,我们让这一切变得更加容易,推出 LangServe。LangServe 是部署任何 LangChain 链/代理/可运行对象的**最简单**和**最佳**方式。
重要链接
- LangServe Github 仓库
- 示例仓库(在 GCP 上部署)
- Replit 模板
它为何存在
无论您是构建面向客户的聊天机器人,还是由 LLM 驱动的内部工具,您都可能会从构建原型(可能在 Jupyter notebook 中)开始,并对其进行迭代,直到它足够好以供人们使用。
LangServe 正是在此时应运而生,我们采纳了在生产环境中扩展应用程序的经验,并将其作为一个 Python 包提供给您,供您用于自己的 LLM 应用程序。
+ LCEL = 原型
+ LangServe = 生产就绪的 API
+ [托管服务提供商] = 实时部署
+ LangSmith 追踪 = 监控您的生产部署
我们一直对发布任何关于部署的内容犹豫不决,因为说实话,我们并不完全确定我们可以增加什么价值。经过过去几个月的关键改进和新增功能,我们现在相信 LangServe 可以提供真正的价值。我们今天发布版本中强调的大部分功能都大大简化了从原型到生产的流程,并获得了生产就绪的 API。在接下来的几周内,我们将添加更多功能,以增加新功能(而不仅仅是使其更容易创建 API)。
在过去一周,我们使用 LangServe 部署了 ChatLangChain 和 WebLangChain,这有助于对其进行实战测试。
LangServe 的发展历程
构建 LangServe 的旅程实际上始于几个月前,当时我们推出了 LCEL 和 Runnable 协议。从一开始,它的设计就旨在支持将原型投入生产,无需更改代码,从最简单的“提示 + LLM”链到最复杂的链(我们已经看到有人成功地在生产环境中运行具有 100 多个步骤的 LCEL 链)。以下重点介绍一些特点:
- 一流的流式传输支持:当您使用 LCEL 构建链时,您将获得最佳的首个令牌时间 (time-to-first-token)(直到第一个输出块出现所经过的时间)。对于某些链,这意味着例如,我们将令牌直接从 LLM 流式传输到流式输出解析器,并且您以与 LLM 提供程序输出原始令牌相同的速率获得解析后的增量输出块。我们正在不断改进流式传输支持,最近我们添加了一个 流式 JSON 解析器,并且正在开发更多功能。
- 一流的异步支持:使用 LCEL 构建的任何链都可以通过同步 API(例如,在 Jupyter notebook 中进行原型设计时)以及 异步 API(例如,在 LangServe 服务器中)调用。这使得可以使用相同的代码进行原型设计和生产,具有出色的性能,并能够在同一服务器中处理许多并发请求。
- 优化的并行执行:每当您的 LCEL 链中有可以并行执行的步骤时(例如,如果您从多个检索器获取文档),我们都会自动执行此操作,无论是在同步接口还是异步接口中,以实现尽可能小的延迟。
- 对重试和回退的支持:最近,我们增加了对为 LCEL 链的任何部分配置重试和回退的支持。这是使您的链在规模上更可靠的好方法。我们目前正在努力为重试/回退添加流式传输支持,以便您可以在不产生任何延迟成本的情况下获得额外的可靠性。
- 访问中间结果:对于更复杂的链,即使在生成最终输出之前,访问中间步骤的结果通常也非常有用。这可以用于让最终用户知道正在发生某些事情,甚至只是为了调试您的链。我们添加了对流式传输中间结果的支持,它在每个 LangServe 服务器上都可用。
- 输入和输出模式:本周,我们为 LCEL 推出了输入和输出模式,为每个 LCEL 链提供了从您的链结构推断出的 Pydantic 和 JSONSchema 模式。这可以用于验证输入和输出,并且是 LangServe 的组成部分。
今天,我们在 LCEL 构建的优势列表中添加了 LangServe,它利用所有这些优势为您提供从 LLM 想法到生产中可扩展的 LLM 应用程序的最快路径。
工作原理
首先,我们创建我们的链,这里使用对话检索链,但任何其他链都适用。这是 my_package/chain.py 文件。
"""A conversational retrieval chain."""
from langchain.chains import ConversationalRetrievalChain
from langchain.chat_models import ChatOpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
vectorstore = FAISS.from_texts(
["cats like fish", "dogs like sticks"],
embedding=OpenAIEmbeddings()
)
retriever = vectorstore.as_retriever()
model = ChatOpenAI()
chain = ConversationalRetrievalChain.from_llm(model, retriever)然后,我们将该链传递给 add_routes。这是 my_package/server.py 文件。
#!/usr/bin/env python
"""A server for the chain above."""
from fastapi import FastAPI
from langserve import add_routes
from my_package.chain import chain
app = FastAPI(title="Retrieval App")
add_routes(app, chain)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="localhost", port=8000)就是这样!这将为您提供一个可扩展的 Python Web 服务器,具有:
- 输入和输出模式从您的链自动推断,并在每个 API 调用上强制执行,并提供丰富的错误消息
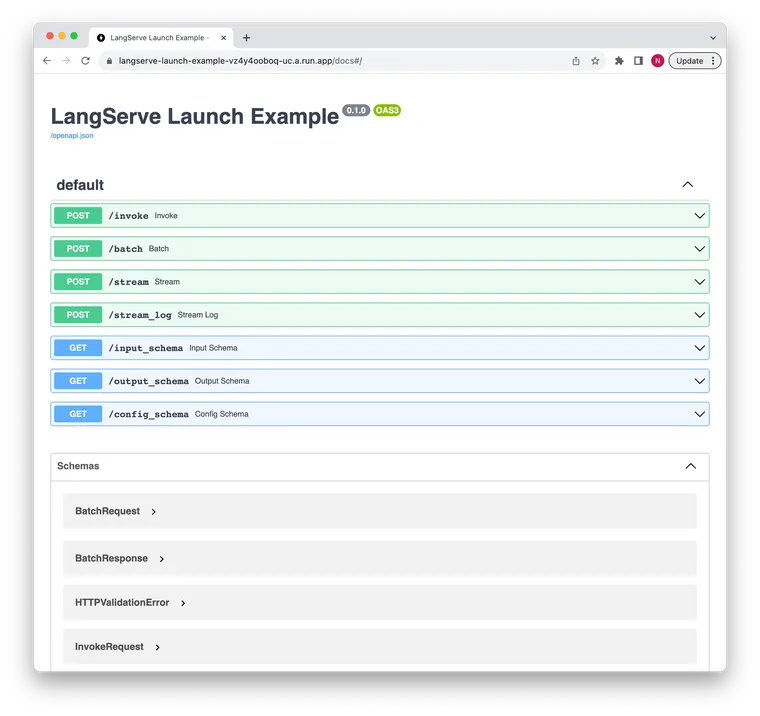
/docs端点提供带有 JSONSchema 和 Swagger 的 API 文档(插入示例链接)/invoke端点接受 JSON 输入并从您的链返回 JSON 输出,支持同一服务器中的多个并发请求/batch端点并行生成多个输入的输出,并在可能的情况下批量调用 LLM/stream端点在输出块可用时发送它们,使用 SSE(与 OpenAI Streaming API 相同)/stream_log端点用于流式传输来自您的链/代理的所有(或部分)中间步骤- 内置(可选)追踪到 LangSmith,只需将您的 API 密钥添加为环境变量
- 支持在同一服务器下以不同路径托管多个链
- 全部使用经过实战检验的开源 Python 库构建,例如 FastAPI、Pydantic、uvloop 和 asyncio。
部署
创建 API 后,下一步是在托管平台上部署它。我们发布了两个示例:
- GCP:使用一个命令部署到 GCP Cloud Run。
- Replit:在 Replit 上部署(和构建)。这可以通过克隆一个现有 Github 仓库来完成。
我们将添加其他平台的说明和模板。如果您对您希望看到的内容有建议,请告诉我们。
观看实际效果
让我们看看它的实际效果。我们已部署此仓库作为示例。
API 文档在此处可用。
我们可以流式传输响应
curl https://langserve-launch-example-vz4y4ooboq-uc.a.run.app/stream -X POST -H "Content-Type: application/json" --data '{"input": {"topic": "bears"}}'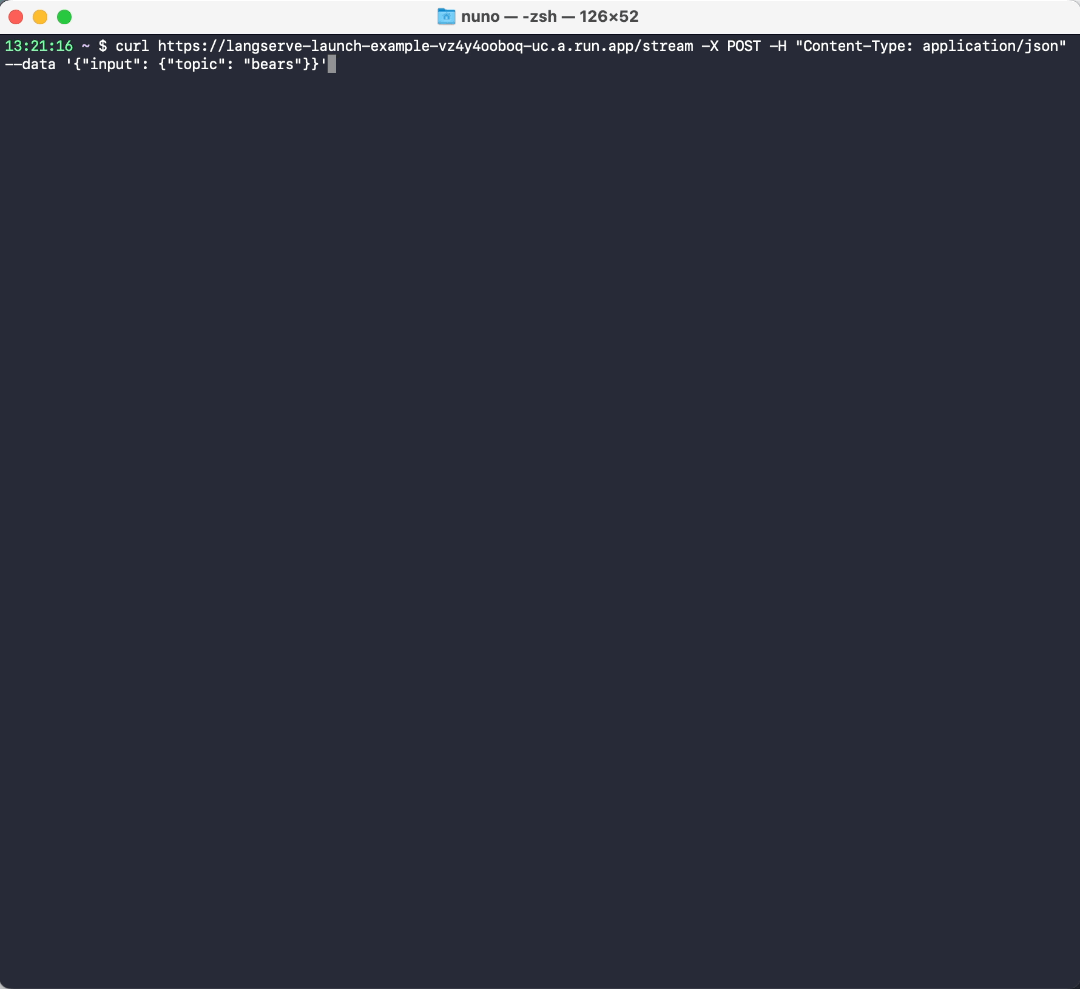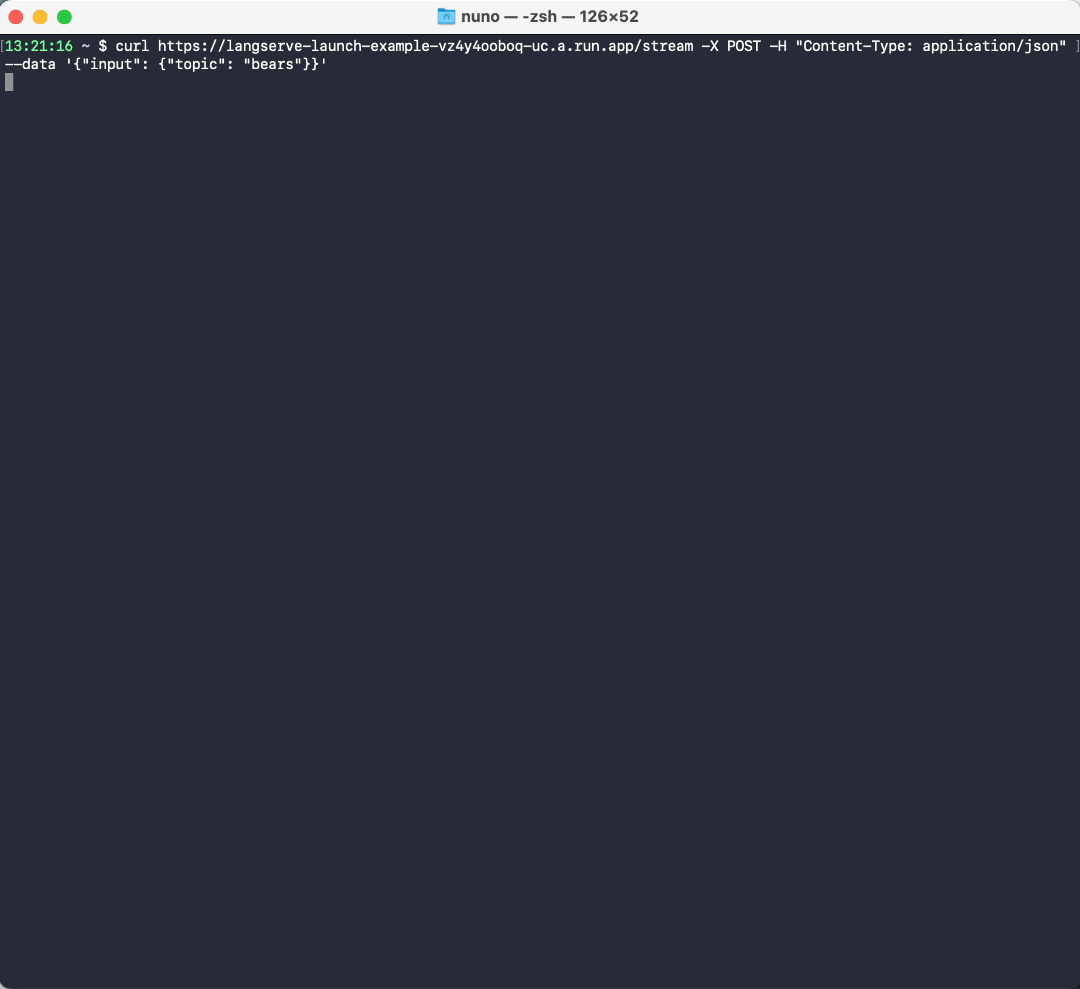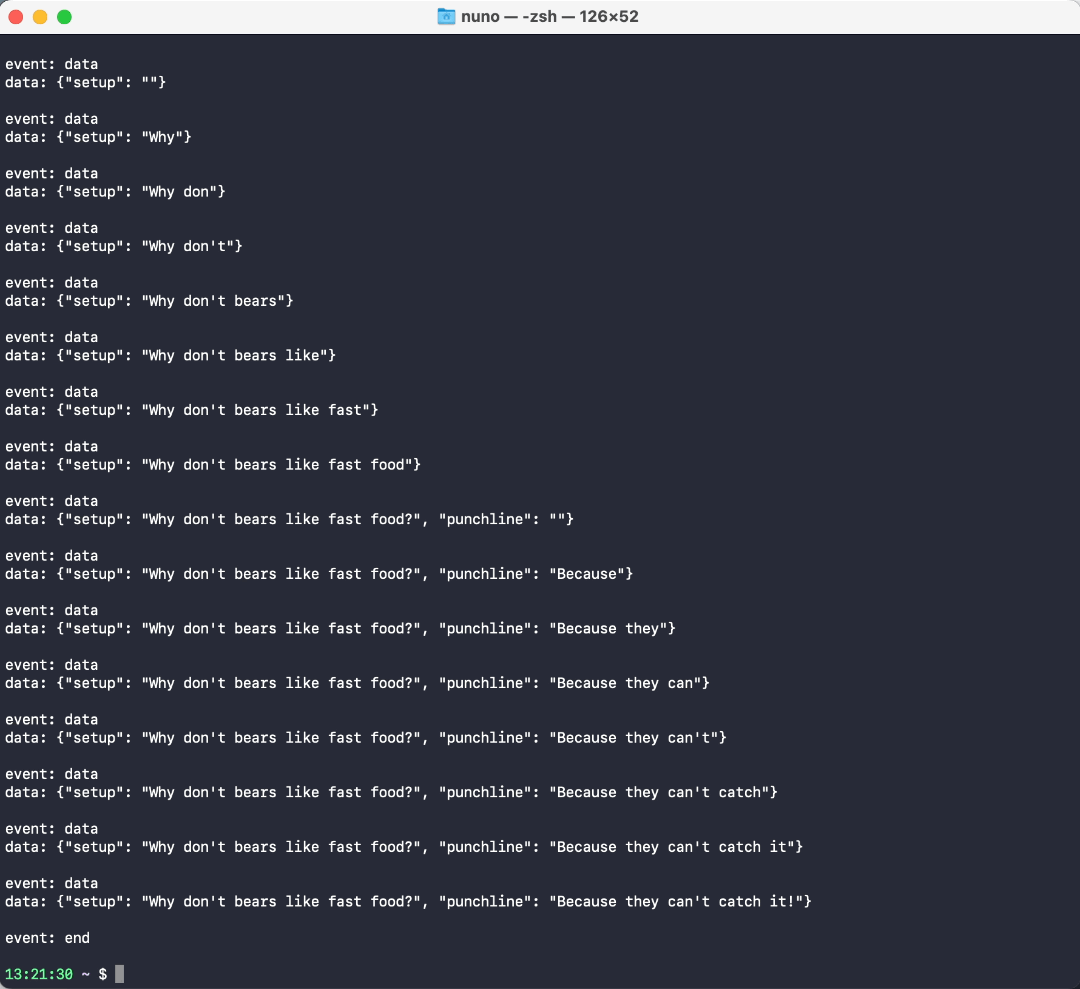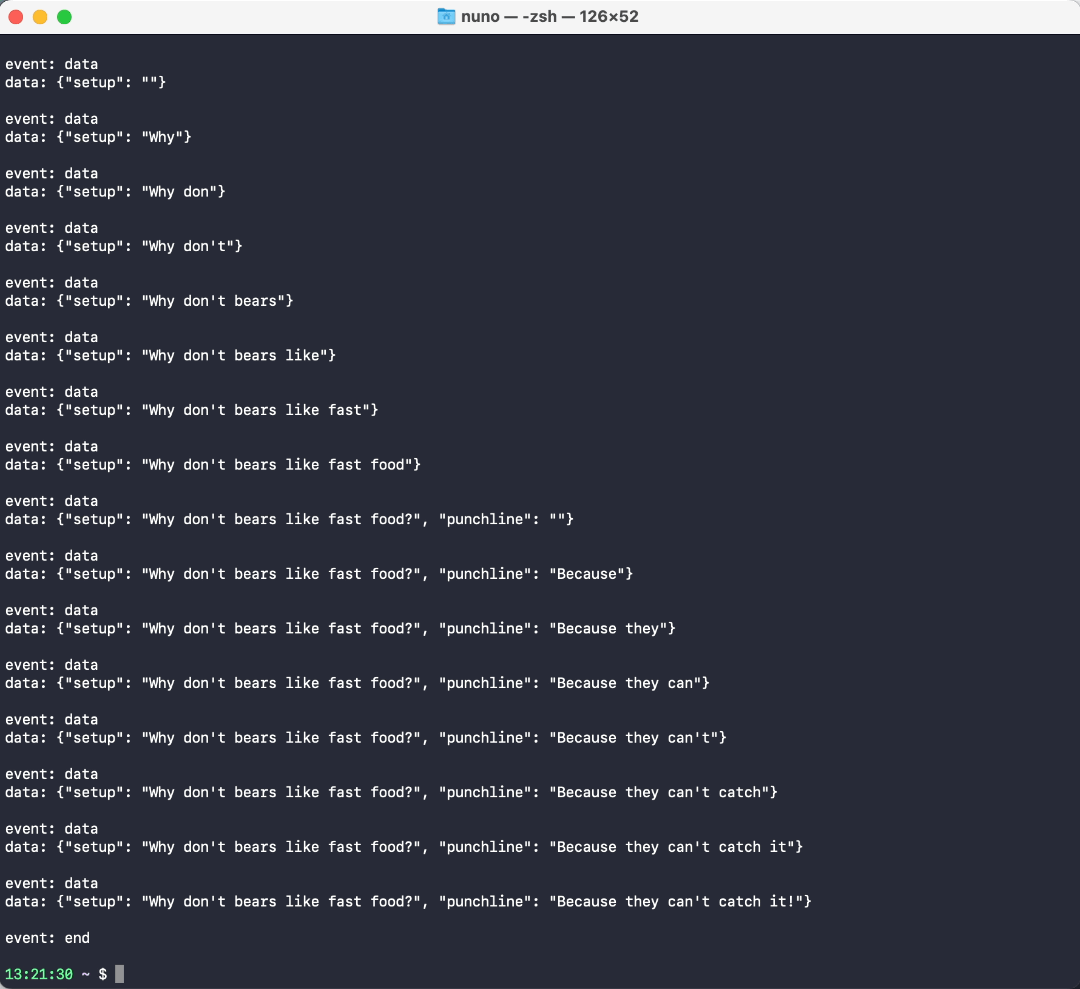
下一步是什么
我们一直在改进 LangChain/LCEL,最近我们添加了对输入和输出模式、流式传输中间结果和流式 JSON 解析器的支持。
我们还将在未来几周内努力添加功能:接下来我们要添加的两个功能是 (1) 一个用于试验已部署链的不同提示/检索器的游乐场,(2) 一种为同一链保存多个配置的方法。
请告诉我们您接下来希望看到什么!