
简介
我们坚定地致力于不断改进我们的文档及其导航性。通过使用 Mendable,一个支持人工智能的聊天应用程序,用户可以使用关键词或问题搜索我们的文档。随着时间的推移,Mendable 收集了大量的问题数据集,突出了文档需要改进的领域。
挑战
从每月数以万计的问题中提炼出共同主题是一项重大挑战。手动标记可能有效,但速度慢且费力。统计方法可以分析词语分布以推断常见主题,但可能无法捕捉问题的语义丰富性和上下文。
提议
LLM 可以帮助我们总结 并识别由 Mendable 收集的问题中的文档缺口。我们实验了两种方法将大型问题数据集传递给 LLM:1) 通过聚类对相似问题进行分组,然后总结每个组;2) 应用 map-reduce 方法,将问题分成小段,总结每个段,然后将它们组合成最终的综合。
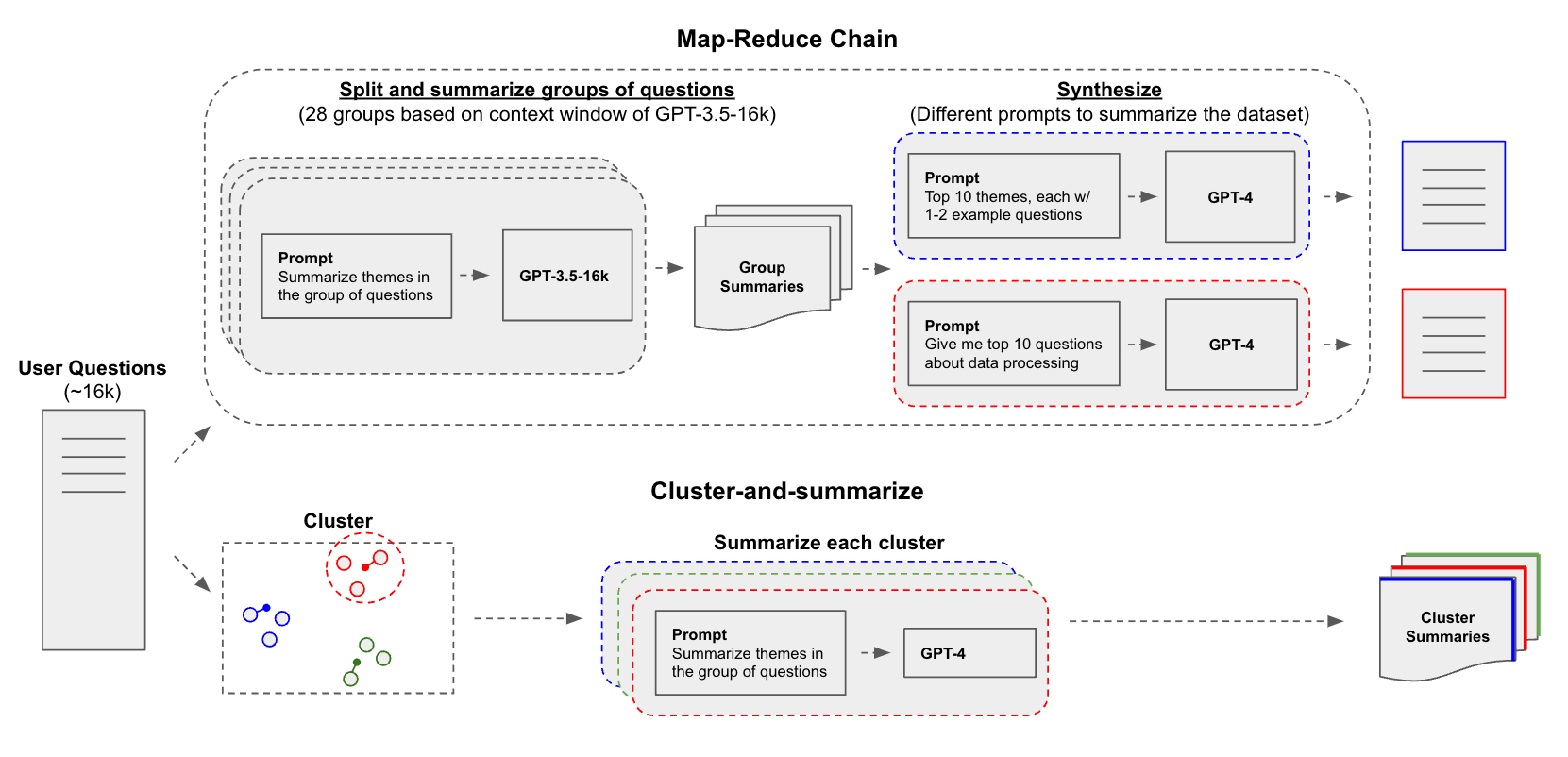
这些方法之间存在权衡,我们希望对此进行考察

结果
我们测试了一个端到端的 LLM 摘要管道,该管道使用 LangChain 的 map-reduce 链,根据 GPT-3.5-16k (16k tokens) 或 Claude-2 (100k tokens) 的上下文窗口将问题分成组,总结每个组(map),然后将组摘要提炼成最终的综合(reduce)。
我们还测试了嵌入问题的 k-Means 聚类,然后使用 GPT-4 总结每个聚类,这种方法 类似于 OpenAI 在其一个 cookbook 中报告的方法。为了保持一致性,我们使用与 map-reduce 相同的输入数据集。
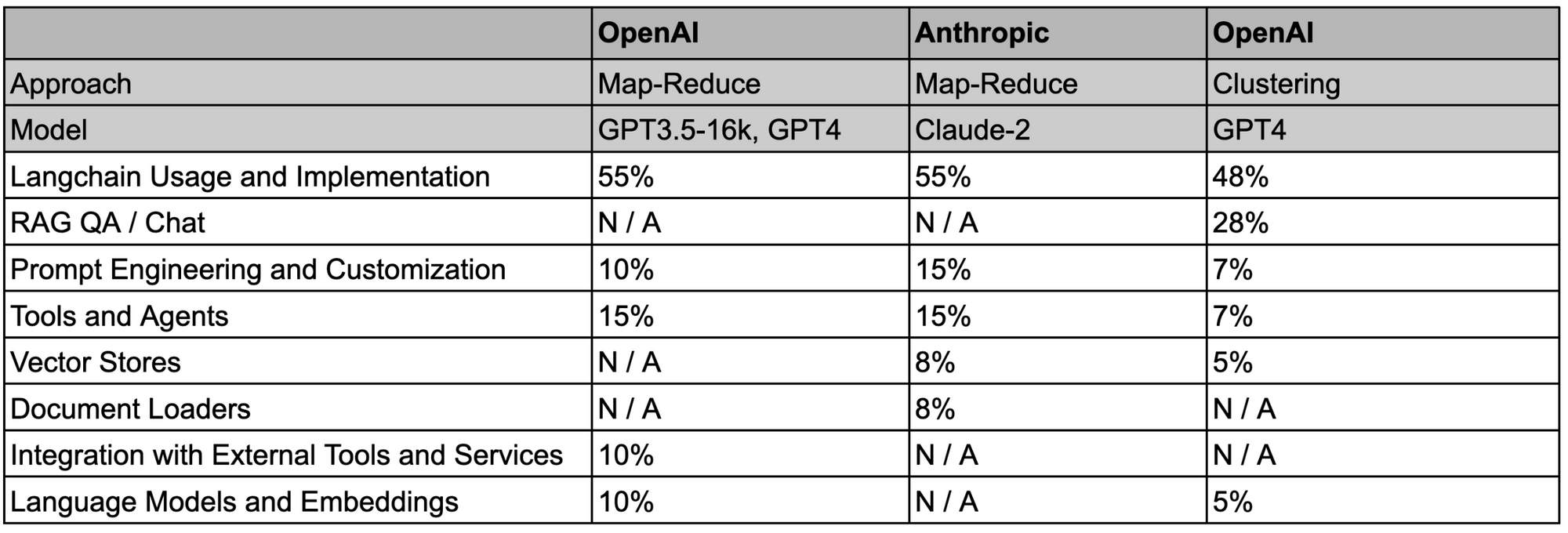
我们开源了 notebooks 和数据(参见 repo 此处),以便可以重现此分析。此处是一个包含详细结果的表格,我们在下表中对其进行了总结;我们要求这两种方法都总结用户提出的主要问题主题以及属于每个类别的问题的比例
可以使用替代的摘要提示来询问特定主题;例如,使用 map-reduce 可以要求 reduce 阶段返回关于特定主题(例如,数据处理)的热门问题。例如,使用此 reduce 提示
The following is a list of summaries for questions entered into a Q+A system:
{question_summaries}
Take these and distill it into a final, consolidated list with:
(1) the top 10 question related to loading, processing, and manipulating different types of data and documents.
(2) estimate the proportion of each question
我们获得了与加载、处理和操作不同类型的数据和文档相关的 Top 10 问题的细粒度主题分解
1. "How can I load a PDF file and split it into chunks using langchain?" - 15%`
2. "How do I load and process a CSV file using Langchain?" - 12%
3. "How do I use the 'readfiletool' to load a text file?" - 11%
4. "How do I use Langchain to summarize a PDF document using the LLM model?" - 10%
5. "What are the different data loaders available in Langchain, and how do I choose the right one for my use case?" - 9%
6. "How do I load and process multiple PDFs?" - 9%
7. "How do I load all documents in a folder?" - 8%
8. "How do I split a string into a list of words in Python?" - 8%
9. "How do I load and process HTML content using BeautifulSoup?" - 8%
10. "How can I add metadata to the Pinecone upsert?" - 10%
为了更好地诊断成本分析,我们使用即将推出的 LangChain 工具来比较方法的诊断(token 使用量等)。例如,我们量化了 token 使用量,这表明 map-reduce 的成本确实更高
- ~50 万 tokens
- ~8 万 tokens(~8 千 / 聚类,共 10 个聚类)
总结
正如预期的那样,这些方法之间存在权衡。Map-Reduce 提供了高度的自定义性,因为可以将问题分成任意细粒度的组,并使用可调整的 map-reduce 提示进行总结。但是,正如 token 使用量所示,成本可能会高得多。聚类由于预处理阶段的手动调整(例如,聚类数量)而存在信息丢失的风险,但它提供了较低的成本,并且可能是快速压缩非常大的数据集以进行更细粒度(和高成本)的 LLM 摘要的明智方法。这两种方法的周全结合为应对这一挑战提供了相当大的希望。