
继我们发布长期内存支持之后,我们正在为 LangGraph 的 BaseStore 添加语义搜索功能。今天已在开源的 PostgresStore 和 InMemoryStore 中、LangGraph Studio 中以及所有 LangGraph 平台部署的生产环境中提供。
快速链接
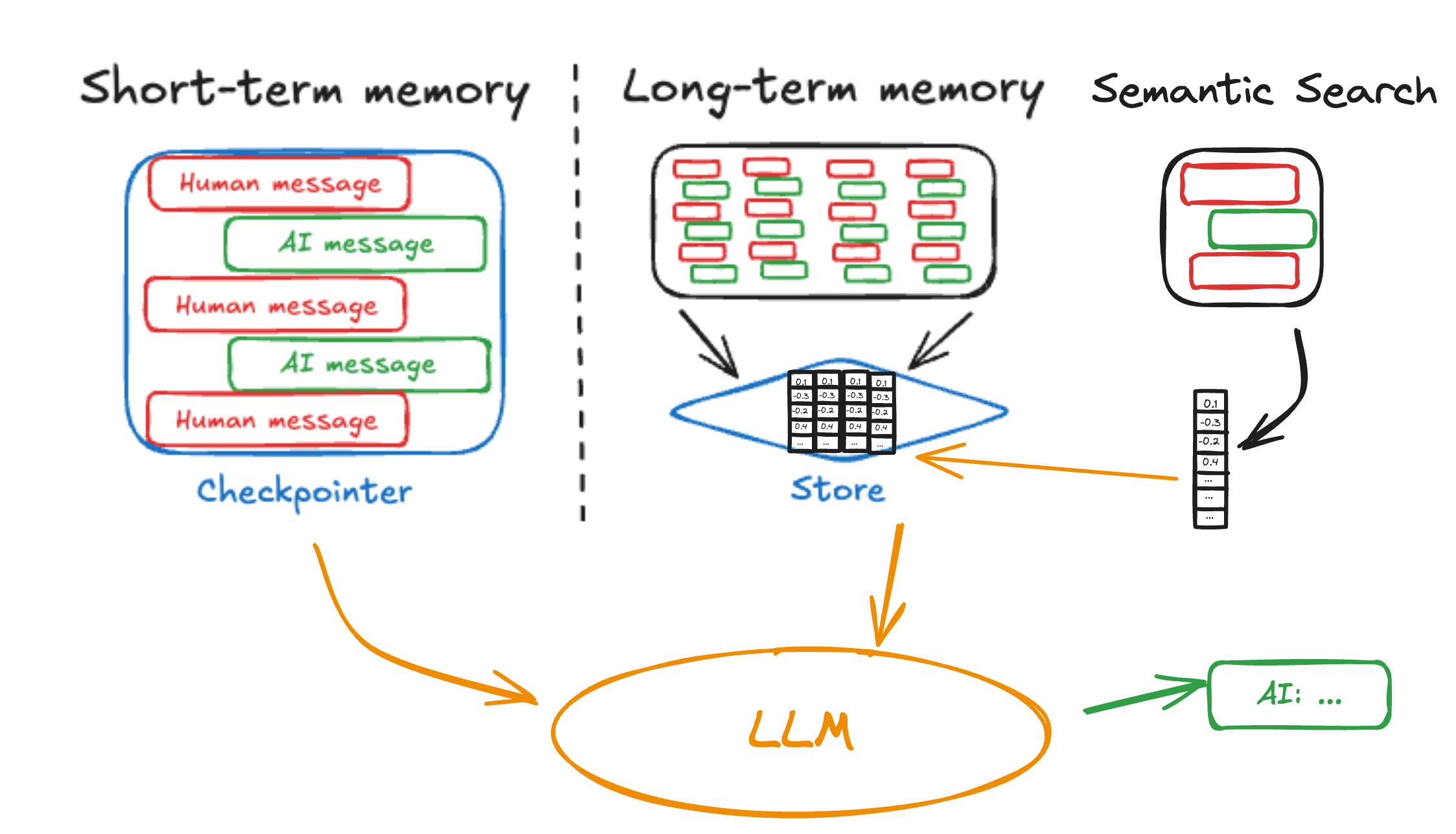
为什么选择语义搜索?
虽然我们的基本内存实现提供了文档存储和筛选,但许多用户要求提供更复杂的非结构化信息检索的原语。当您保持事物井井有条时,简单的筛选可以工作,但代理通常需要根据含义而不是精确匹配来查找相关信息。
例如,代理可能需要:
- 回忆用户偏好和过去的互动,以便进行个性化回复
- 通过检索类似的失败方法,从过去的错误中学习
- 通过回忆先前互动中学习的重要事实,保持一致的知识
语义搜索通过匹配含义而不是精确内容来应对这些挑战,使代理能够更有效地利用其存储的知识。
实施
BaseStore 的 search(和异步 asearch)方法现在支持自然语言 query 术语。如果您使用的存储已添加支持,则将根据语义相似性对文档进行评分和返回。InMemoryStore(用于开发)和 PostgresStore(用于生产)都已添加支持。以下是一个使用示例:
def search_memory(state: State, *, store: BaseStore):
results = store.search(
("user_123", "interactions"),
query=state["messages"][-1].content,
filter={"type": "conversation"},
limit=3
)
return {
"context": [
f"Previous interaction ({r.score:.2f} relevance):\n{r.value}"
for r in results
]
}
Example search node to lookup relevant memories.用于查询相关内容的示例节点
要在 LangGraph 平台中使用,您可以在 langgraph.json 文件中通过 store 配置将服务器配置为嵌入新项目
{
"store": {
"index": {
"embed": "openai:text-embeddings-3-small",
"dims": 1536,
"fields": ["text", "summary"]
}
}
}
主要配置选项
embed:嵌入提供程序(例如,“openai:text-embedding-3-small”)或自定义函数的路径(文档)。provider:model支持取决于 LangChain 的使用。dims:所选嵌入模型的维度大小(OpenAI 的 text-embedding-3-small 为 1536)fields:要索引的字段列表。使用["$"]索引整个文档,或指定 json 路径,如["text", "summary", "messages[-1]"]
如果您不是 LangChain 用户,或者您想定义自定义嵌入逻辑,请定义您自己的函数
async def aembed_texts(texts: list[str]) -> list[list[float]]:
response = await client.embeddings.create(
model="text-embedding-3-small",
input=texts
)
return [e.embedding for e in response.data]
然后在配置中引用您的函数
{
"store": {
"index": {
"embed": "path/to/embedding_function.py:embed_texts",
"dims": 1536
}
}
}
如果您想自定义要为给定项目嵌入的字段,或者您想省略索引某个项目,请将 index 参数传递给 store.put
# embed the configured default "text" field "Python tutorial"
store.put(("docs",), "doc1", {"text": "Python tutorial"})
# Override default field to embed "other_field" instead
store.put(
("docs",),
"doc2",
{"text": "TypeScript guide", "other_field": "value"},
index=["other_field"],
)
# Do not embed this item
store.put(("docs",), "doc2", {"text": "Other guide"}, index=False)有关更多信息,请参阅文档。
迁移
如果您已经在使用 LangGraph 的内存存储,则添加语义搜索是非破坏性的。所有操作都与以前相同。LangGraph OSS 用户可以通过使用索引配置构建他们的 PostGresStore 来开始使用(同步 & 异步 文档)
from langchain.embeddings import init_embeddings
from langgraph.store.postgres import PostgresStore
store = PostgresStore(
connection_string="postgresql://user:pass@localhost:5432/dbname",
index={
"dims": 1536,
"embed": init_embeddings("openai:text-embedding-3-small"),
# specify which fields to embed. Default is the whole serialized value
"fields": ["text"],
},
)
store.setup() # Do this once to run migrations
对于 LangGraph 平台用户,一旦您向部署添加 index 配置,put 到存储中的新文档就可以被索引以进行搜索,并且您可以添加自然语言 query 字符串以返回按语义相似性排序的文档。
下一步
我们已更新文档和模板,以演示语义搜索的实际应用。请查看以下链接:
- 内存模板使用对“后台”保存的记忆进行搜索
- 内存代理搜索作为工具保存的记忆
- 视频教程,关于向内存代理模板添加语义搜索
- 操作指南,关于在 LangGraph 中添加语义搜索
- 操作指南,关于在您的 LangGraph 平台部署中添加语义搜索
- 参考文档,关于 BaseStore
试用一下,并在 GitHub 上分享您的反馈。
最后,有关 AI 内存的更多概念信息,请查看我们的内存概念文档。