我注意到一个模式,伟大的 AI 研究人员愿意手动检查大量数据。更重要的是,他们构建基础设施,使他们能够快速手动检查数据。虽然不那么光鲜,但手动检查数据可以提供关于问题的宝贵直觉。
- Jason Wei, OpenAI
评估仍然是构建 LLM 应用程序最困难的部分之一。以定量的方式评估对你的提示、链或代理的更改效果真的很难。我们看好LLM辅助评估,但与此同时,我们肯定也认识到完全信任它们是很困难的。
上面 Jason 的推文总结了我们看到许多最优秀的研究人员(和工程师)正在做的事情。他们希望手动检查数据以获得对问题的直觉。在 LangChain,我们希望构建基础设施来帮助做到这一点 - 这就是为什么我们很高兴今天宣布推出测试运行对比。
在LangSmith 的初始版本中,我们支持运行测试,包括使用 LLM 辅助反馈对其进行评分。但是,每个测试都是孤立运行的。我们很快看到了两种使用模式出现
- 人们仍然犹豫是否直接信任 LLM 辅助反馈
- 用户通常不仅希望孤立地对其测试运行进行评分,还希望将其与之前的迭代进行比较
在构建测试运行对比时,我们牢记这两个见解。我们希望创建一个简单的 UX,以并排查看多个测试运行。我们还希望创建一个简单的 UX,人们可以使用 LLM 辅助评估(或正则表达式/其他评估)来获得初始分数,然后手动探索这些数据点以获得进一步的见解。
那么它是如何工作的呢?
首先,您需要设置一个数据集并运行一些测试。请参阅此处的文档以获取有关如何执行此操作的说明。这里没有什么新内容,因此如果您已经为现有项目执行过此操作,那么一切都很好。
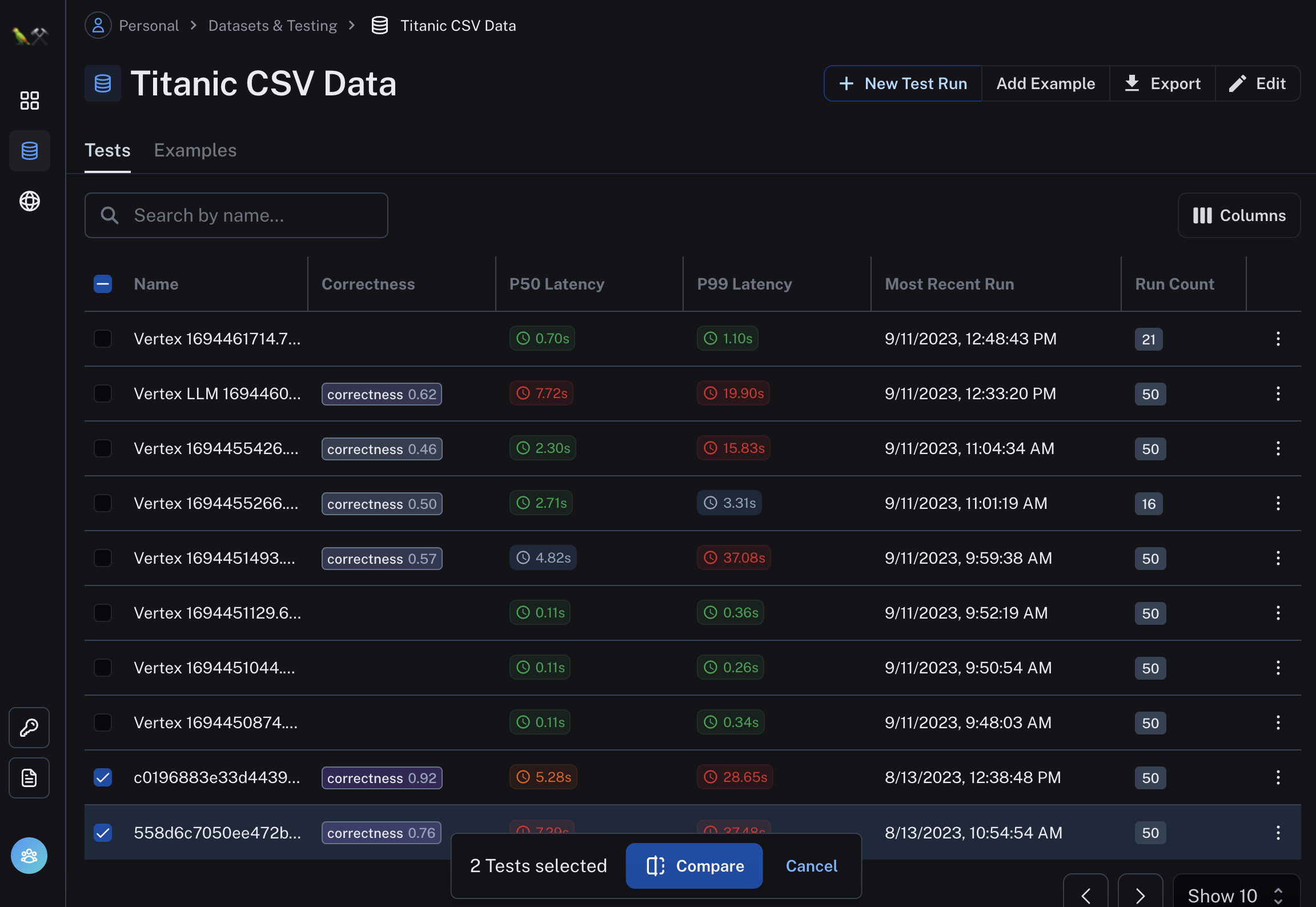
在数据集内部,您可以轻松选择两个(或更多)测试运行,然后单击比较。
从那里,您将被带入测试运行对比视图。这应该看起来像下面这样
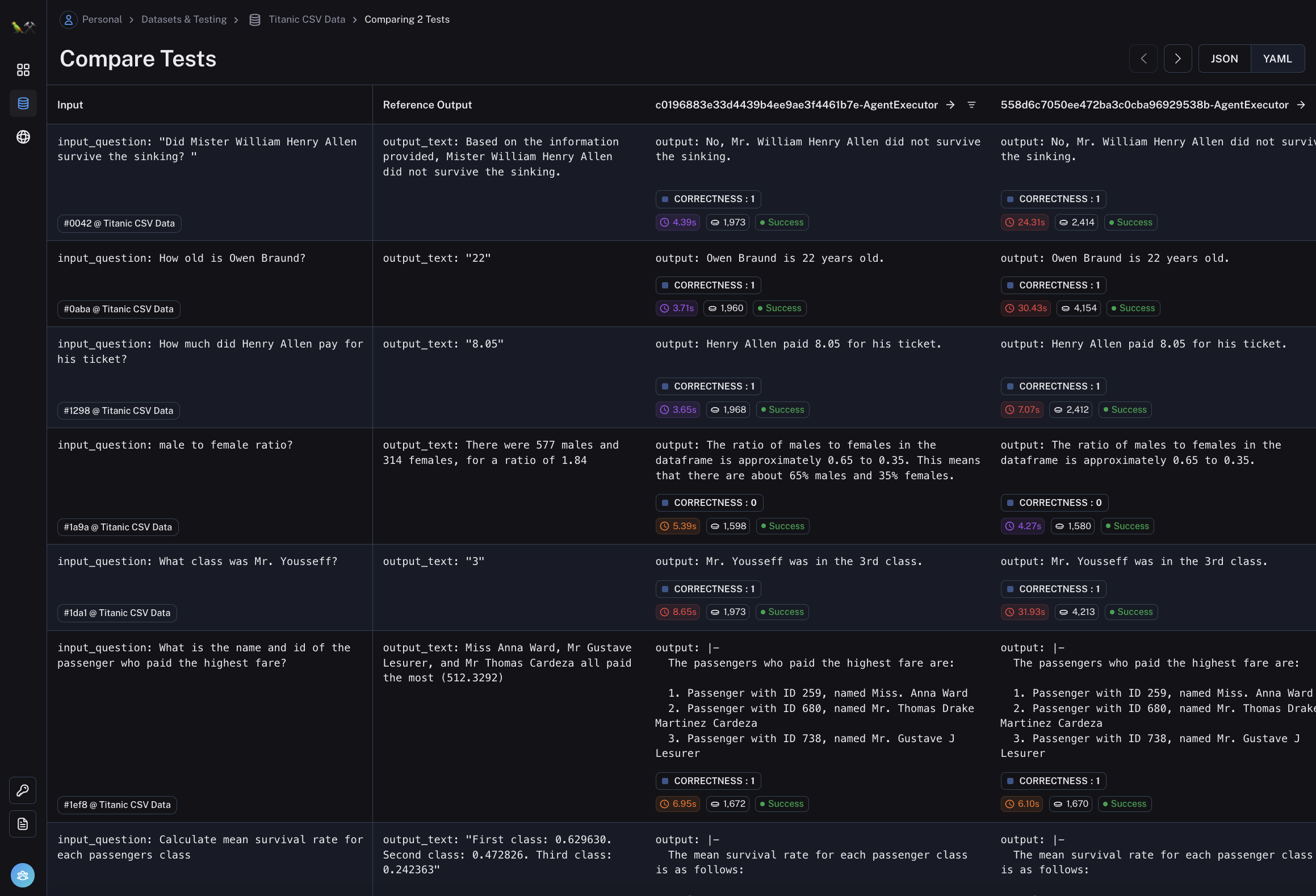
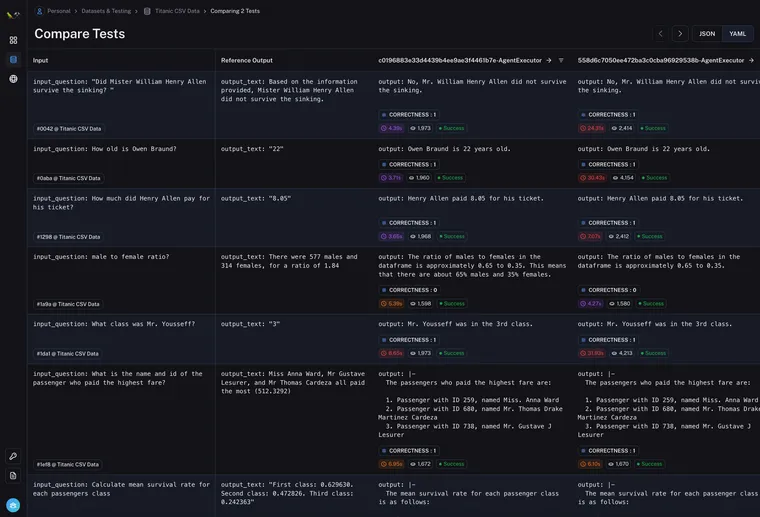
您可以轻松查看输入、参考输出,以及每个数据点的实际输出 - 以及该运行的任何评估指标、时间和延迟。
此视图旨在使您可以轻松快速地比较相同输入的不同测试运行。如果您想更深入地了解特定数据点,您可以单击该行,侧边栏将弹出,允许您深入了解这些运行的详细信息。
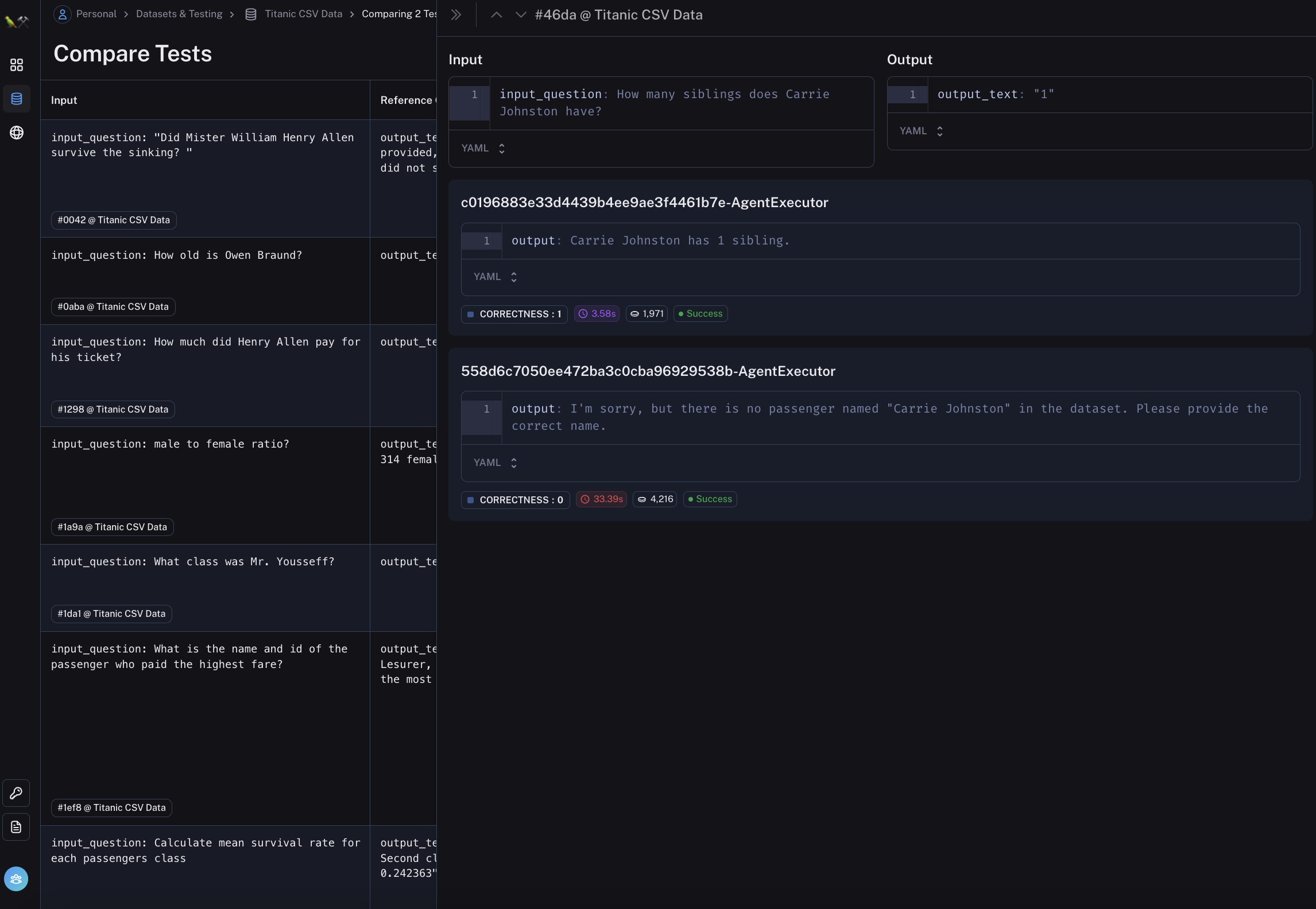
在该侧边栏上,我们还添加了向上和向下箭头(▲ 和 ▼),以便轻松地在运行之间切换。
此视图应该可以轻松比较特定数据点的运行。但是,您如何知道要查看哪些数据点呢?
我们为每一列添加了过滤器 - 类似于 Excel。使用这些过滤器,您可以根据任何条件过滤行。

构建 LLM 应用程序是困难的。其中很大一部分是了解 LLM 如何在特定任务上工作。设置评估数据集,然后能够轻松比较该数据集上的运行对于开发改进应用程序所需的理解至关重要。LangSmith 中的测试运行对比旨在解决这个问题。请告诉我们您有任何反馈!
LangSmith 目前处于私有 Beta 版 - 在此处注册。我们将在未来几周内推出更多访问权限,并继续添加此类功能。