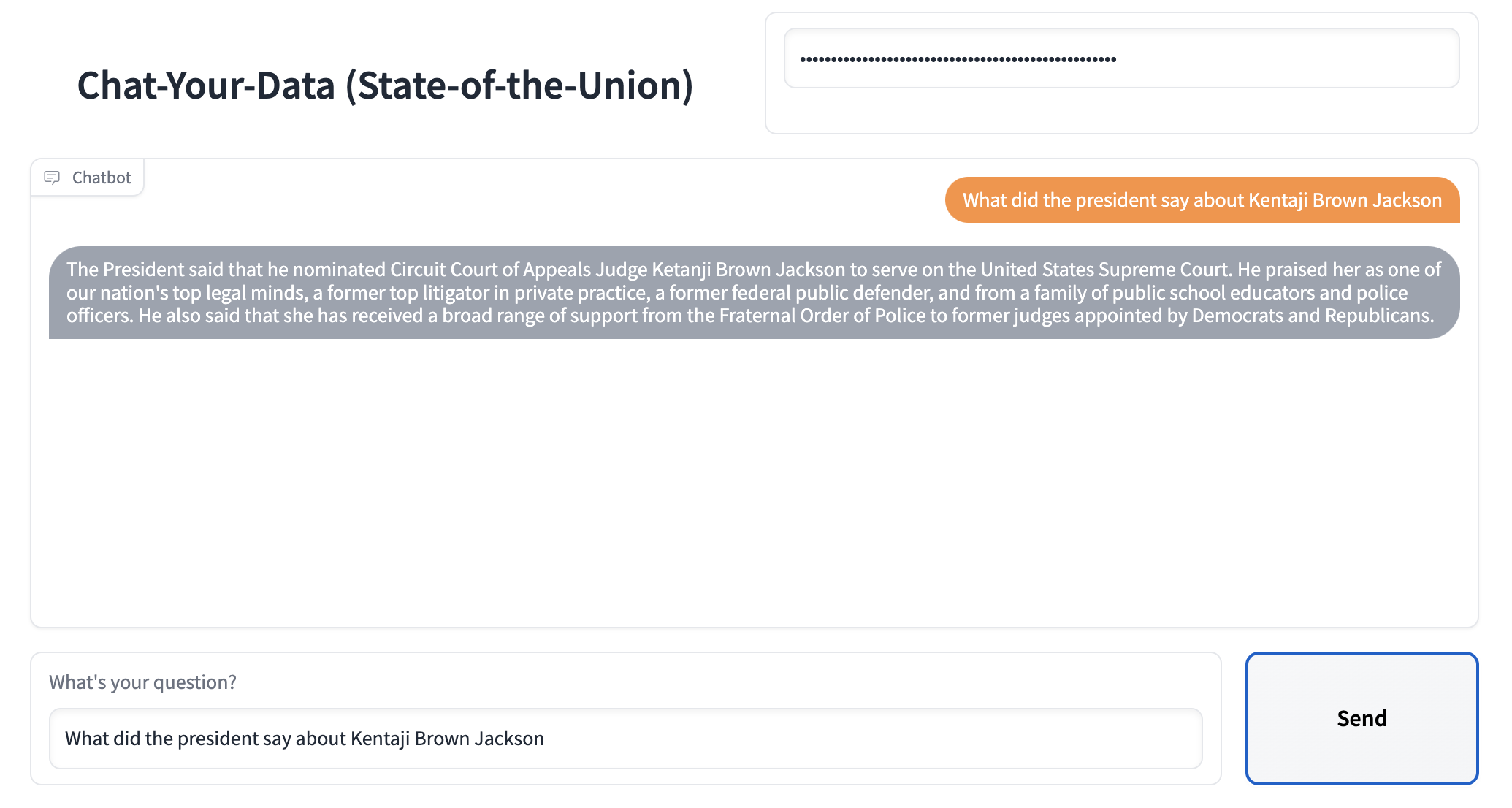
注意:请查看此博文的配套 GitHub 仓库 此处。
ChatGPT 已经风靡全球。数百万用户都在使用它。虽然它在通用知识方面表现出色,但它只了解它所训练的信息,这些信息通常是 2021 年之前公开的互联网数据。它不了解您的私人数据,也不了解最新的数据来源。
如果它能做到这些,岂不是很有用?
这篇博文是一个教程,介绍如何针对特定的数据语料库设置您自己的 ChatGPT 版本。有一个配套 GitHub 仓库,其中包含本文中引用的相关代码。具体来说,本文处理的是文本数据。有关如何使用自然语言层与其他数据源交互,请参阅以下教程
高层概览
在高层面上,设置在您自己的数据上使用 ChatGPT 有两个组成部分:(1)数据摄取,(2)基于数据的聊天机器人。下面将高层概述每个步骤
数据摄取
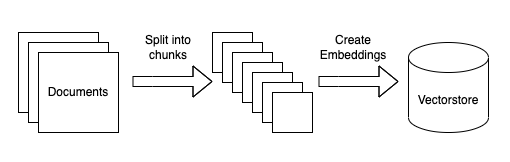
这可以分解为几个子步骤。所有这些步骤都是高度模块化的,作为本教程的一部分,我们将介绍如何替换步骤。步骤如下
- 将数据源加载到文本:这涉及将您的数据从任意来源加载到文本格式,以便下游可以使用。这是我们希望社区能够提供帮助的一个地方!
- 文本分块:这涉及将加载的文本分成更小的块。这是必要的,因为语言模型通常对其可以处理的文本量有限制,因此创建尽可能小的文本块是必要的。
- 嵌入文本:这涉及为每个文本块创建数字嵌入。这是必要的,因为我们只想为给定的问题选择最相关的文本块,我们将通过在嵌入空间中找到最相似的块来实现这一点。
- 将嵌入加载到向量数据库:这涉及将嵌入和文档放入向量数据库。向量数据库帮助我们快速有效地在嵌入空间中找到最相似的块。
数据查询
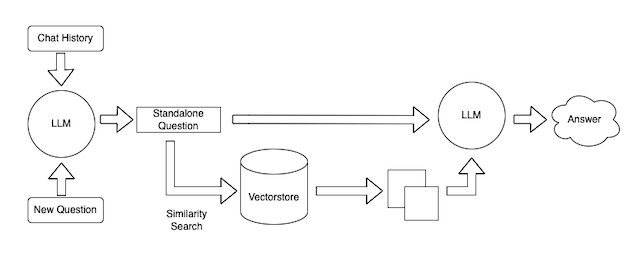
这也可以分解为几个步骤。同样,这些步骤是高度模块化的,并且主要依赖于可以替换的提示。步骤如下
- 将聊天记录和新问题合并为一个独立的完整问题。这是必要的,因为我们希望允许提出后续问题(一个重要的用户体验考虑因素)。
- 查找相关文档。使用在摄取过程中创建的嵌入和向量数据库,我们可以查找回答问题的相关文档
- 生成响应。给定独立的完整问题和相关文档,我们可以使用语言模型生成响应
我们还将简要介绍此聊天机器人的部署,尽管不会在这上面花费太多时间(未来的帖子!)。
数据摄取
本节深入探讨摄取数据所需的步骤。
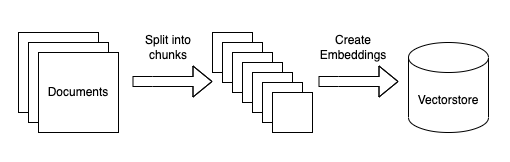
加载数据
首先,我们需要将数据加载为标准格式。同样,因为本教程侧重于文本数据,所以通用格式将是 LangChain Document 对象。此对象非常简单,由(1)文本本身,(2)与该文本关联的任何元数据(来源等)组成。
由于有太多潜在的数据加载来源,这是我们希望社区能够大力推动的一个领域。至少,我们希望获得大量关于如何从来源加载数据的示例笔记本。理想情况下,我们将把加载逻辑添加到核心库中。请参阅此处查看现有的示例笔记本,并参阅此处查看底层代码。如果您想贡献,请随时直接打开 PR 或打开一个 GitHub issue,其中包含您的工作代码片段。
下面一行包含负责加载相关文档的代码行。如果您想更改文档加载的逻辑,则应更改此行代码。
loader = UnstructuredFileLoader("state_of_the_union.txt")
raw_documents = loader.load()分割文本
除了加载文本之外,我们还需要确保将其分成小块。这是必要的,以确保我们只将最小、最相关的文本片段传递给语言模型。为了分割文本,我们需要初始化一个文本分割器,然后在原始文档上调用它。
以下几行负责此操作。如果您想更改文本的分割方式,则应更改这些行
text_splitter = RecursiveCharacterTextSplitter()
documents = text_splitter.split_documents(raw_documents)创建嵌入并存储在向量数据库中
接下来,现在我们有了小的文本块,我们需要为每个文本片段创建嵌入,并将它们存储在向量数据库中。这样做是为了我们可以使用嵌入来查找最相关的文本片段,并将它们发送到语言模型。
这是通过以下几行代码完成的。在这里,我们使用 OpenAI 的嵌入和 FAISS 向量数据库。如果我们想更改使用的嵌入或使用的向量数据库,我们可以在这里更改它们。
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(documents, embeddings)最后,我们保存创建的向量数据库,以便稍后使用。这样,我们只需要运行一次摄取脚本。
with open("vectorstore.pkl", "wb") as f:
pickle.dump(vectorstore, f)这就是整个摄取脚本!在您根据自己的偏好修改此脚本后,您可以运行 `python ingest_data.py` 来运行该脚本。这应该会生成一个 `vectorstore.pkl` 文件。
查询数据
现在我们已经摄取了数据,我们可以在聊天机器人界面中使用它了。为了做到这一点,我们将使用 ChatVectorDBChain。为了自定义此链,我们可以更改一些内容。
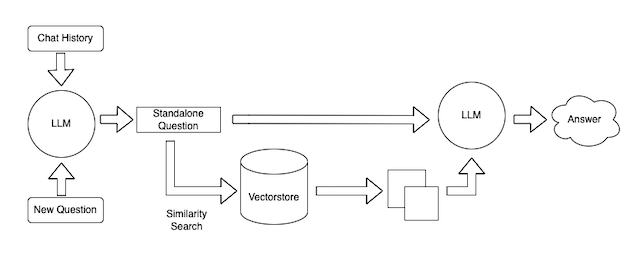
精简问题提示
我们可以控制的第一件事是接收聊天记录和新问题并生成独立完整问题的提示。这是必要的,因为这个独立的完整问题然后被用于查找相关文档。
这是一个非常重要的步骤。如果您仅使用新问题来查找相关文档,则您的聊天机器人对于后续问题将无法正常工作(因为之前的交流中可能存在查找相关文档所需的信息)。如果您嵌入整个聊天记录以及新问题来查找相关文档,您可能会拉入与对话不再相关的文档(如果新问题完全不相关)。因此,将聊天记录和新问题精简为独立完整问题的这一步骤非常重要。
此提示是 query_data.py 文件中的 CONDENSE_QUESTION_PROMPT。
问答提示
您可以使用的另一个杠杆是接收文档和独立完整问题以回答问题的提示。可以自定义此提示,以使您的聊天机器人具有特定的对话风格。
此提示是 query_data.py 文件中的 QA_PROMPT
注意:当使用 GitHub 仓库时,您必须更改此提示。那里的当前提示指定他们应该只回答关于国情咨文演讲的问题,这对于虚拟示例有效,但可能不适用于您的用例。
语言模型
最后一个可以使用的杠杆是您用于驱动聊天机器人的语言模型。在我们的示例中,我们使用 OpenAI LLM,但这可以很容易地替换为 LangChain 支持的其他语言模型,您甚至可以编写自己的包装器。
整合在一起
在完成所有必要的自定义并运行 python ingest_data.py 后,您如何与此聊天机器人交互?
我们通过一个非常简单的界面公开了您可以执行此操作的方式。您只需运行 python cli_app.py 即可访问此界面,这将在终端中打开一种提问和获取答案的方式。试试看!
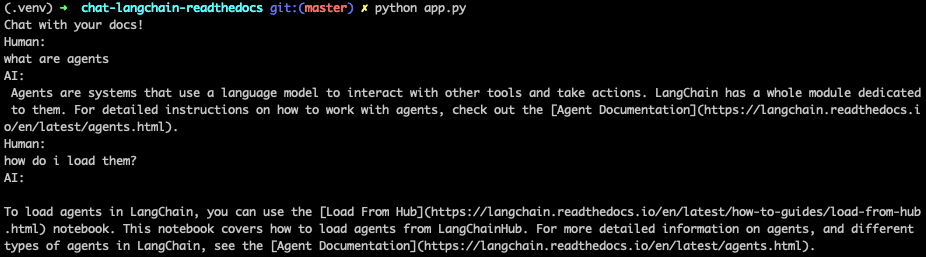
我们还有一个通过 Gradio 部署此应用程序的示例!您可以通过运行 python app.py 来做到这一点。这也可以很容易地部署到 Hugging Face Spaces - 请参阅此处的示例空间。