
摘要
我们创建了一个关于使用 LangSmith 进行数据集管理和评估来微调和评估 LLM 的指南。我们分别针对在 CoLab 和 HuggingFace 上使用开源 LLM 进行模型训练,以及 OpenAI 的新微调服务进行了实践。作为一个测试案例,我们使用从 LangSmith 导出的训练数据微调了 LLaMA2-7b-chat 和 gpt-3.5-turbo 以执行抽取任务(知识图谱三元组抽取),并使用 LangSmith 评估了结果。CoLab 指南在此。
背景
在过去几周,人们对微调的兴趣迅速增长。这主要归因于两个原因。
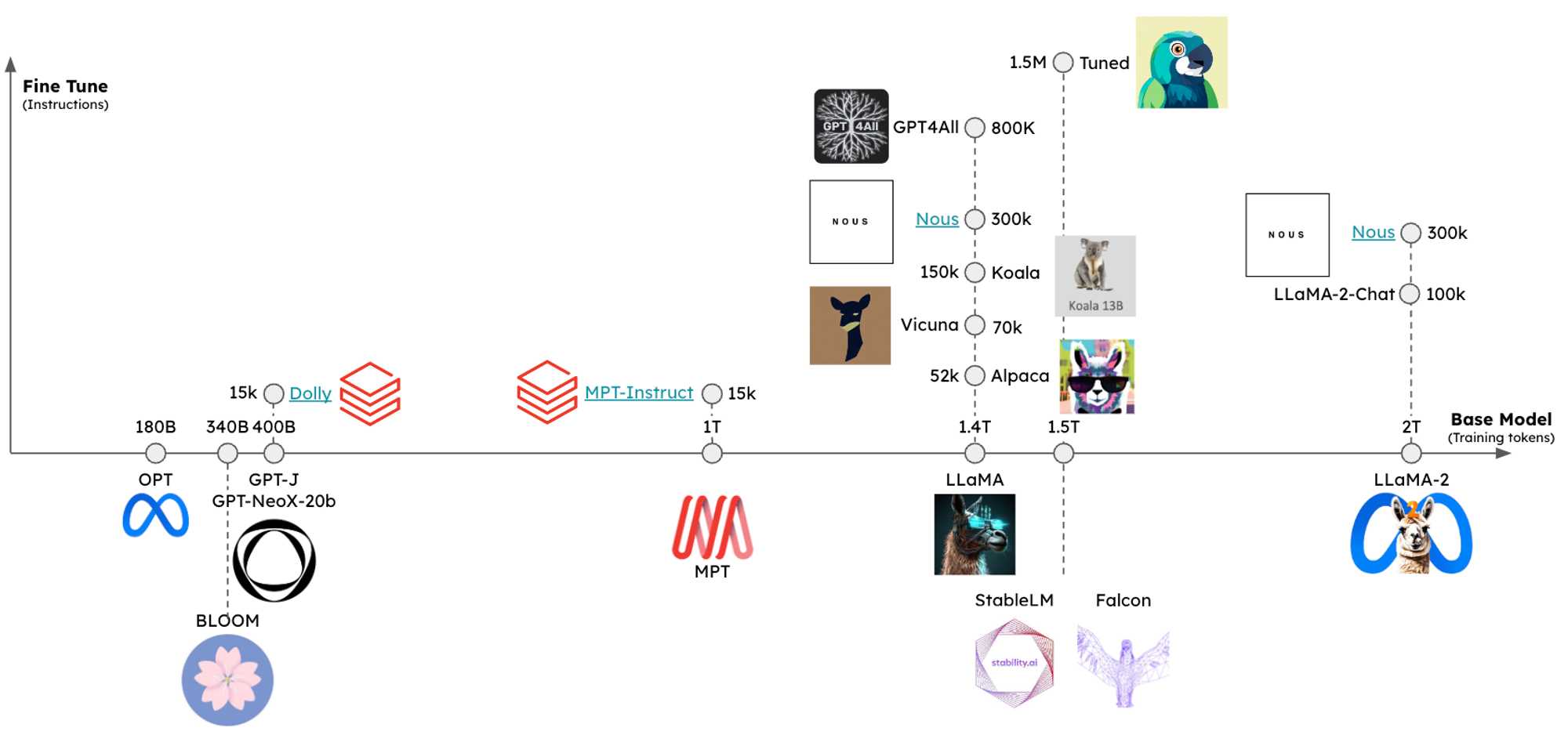
首先,开源 LLM 生态系统发展迅速,从开源 LLM 大幅落后于最先进水平 (SOTA) 发展到接近 SOTA 的(例如,Llama-2)LLM,这些 LLM 可以在消费级笔记本电脑上运行,这一切只用了一年左右的时间!这一进展的驱动因素包括不断增长的大规模训练数据集(下图中的 x 轴)和用于指令跟随和更好的人类-对齐响应的微调(y 轴)。高性能的开源基础模型具有成本节约(例如,对于令牌密集型任务)、隐私等优势,并且通过微调,有机会针对高度特定的任务超越 SOTA LLM,同时使用规模更小的开源模型。
其次,领先的 LLM 提供商 OpenAI 发布了对 gpt-3.5-turbo(和其他模型)的微调支持。此前,微调仅适用于较旧的模型。这些模型的能力远不如较新的模型,这意味着即使经过微调,它们通常也无法与 GPT-3.5 和少量示例相竞争。现在较新的模型可以进行微调,许多人预计这种情况将会改变。
一些 人 认为,与单个大型通用模型相比,组织可能会选择许多从开源基础模型派生的专业微调 LLM。考虑到这一点以及 HuggingFace 等支持微调的库,您可能会好奇何时以及如何进行微调。本指南提供了一个概述,并展示了 LangSmith 如何支持此过程。
何时进行微调
LLM 可以通过至少两种方式学习新知识:权重更新(例如,预训练或微调)或提示(例如,检索增强生成,RAG)。模型权重就像长期记忆,而提示就像短期记忆。这篇 OpenAI 食谱有一个有用的类比:当您微调模型时,就像为一周后的考试学习。当您将知识插入提示中(例如,通过检索),就像带着开卷笔记参加考试。
考虑到这一点,对于教授 LLM 新知识或事实回忆,不 建议 使用微调;OpenAI 的 John Schulman 在 这次演讲 中指出,微调可能会增加幻觉。微调更适合于教授专门的任务,但是 应该 相对于提示或 RAG 进行考虑。正如 此处 讨论的,对于具有充足示例和/或 LLM 缺乏少量样本提示的上下文学习能力的良好定义的任务,微调可能会有所帮助。Anyscale 的这篇 博客 很好地总结了这些观点:微调是为了形式,而不是为了事实。
如何进行微调
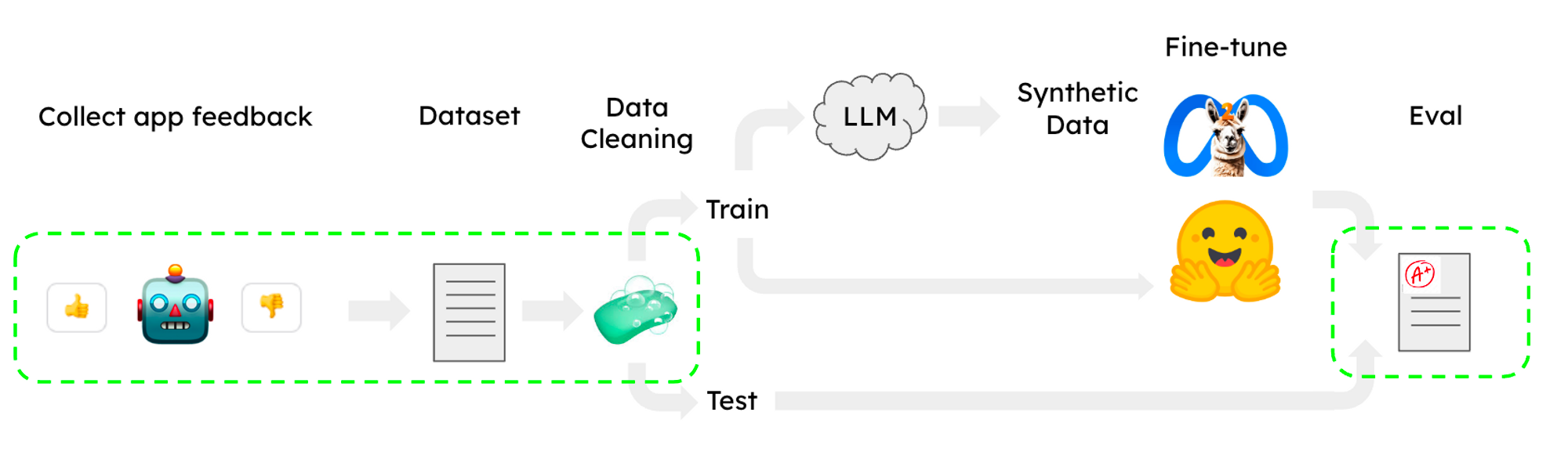
已经发布了许多有用的 LLaMA 微调配方,用于诸如 聊天 等任务,方法是使用 子集 的 OpenAssistant 语料库,并在 HuggingFace 中实现。值得注意的是,这些配方可以在单个 CoLab GPU 上运行,这使得工作流程易于访问。然而,微调中最大的两个痛点仍然是数据集收集/清理和评估。下面我们展示了如何使用 LangSmith 来帮助解决这两个问题(下方的绿色部分)。
任务
诸如分类/标记或抽取之类的任务非常适合微调;Anyscale 报告了通过在抽取、文本到 SQL 和 QA 任务上微调 LLaMA 7B 和 13B LLM 而取得的有希望的结果(超过 GPT4)。作为一个测试案例,我们选择了从文本中抽取知识三元组,形式为(主体,关系,客体):主体和客体是实体,关系是它们之间的属性或连接。然后,三元组可以用于构建知识图谱,这是一种存储有关实体及其关系信息的数据库。我们构建了一个公共的 Streamlit 应用程序,用于从用户输入的文本中抽取三元组,以探索 LLM(GPT3.5 或 4)使用函数调用抽取三元组的能力。与此同时,我们使用 公共 数据集,针对此任务微调了 LLaMA2-7b-chat 和 GPT-3.5。
数据集
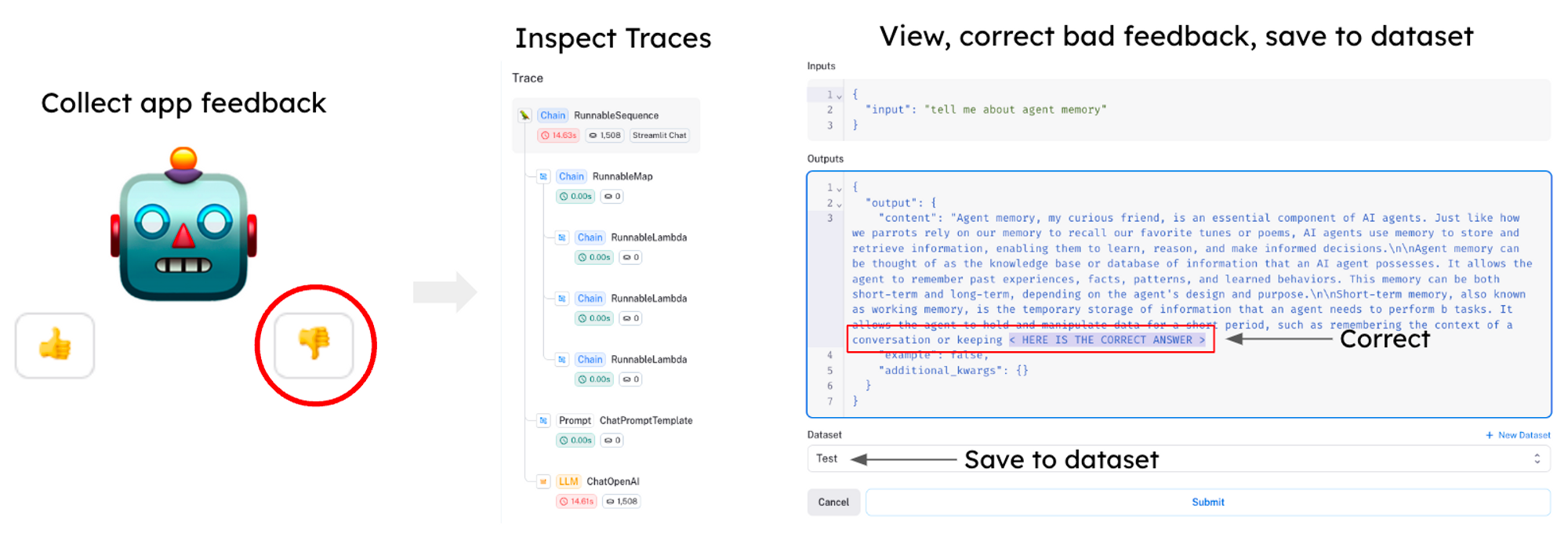
数据集收集和清理通常是训练 LLM 中的一项具有挑战性的任务。 当在 LangSmith 中设置项目时,生成结果会自动记录,从而可以轻松获得大量数据。LangSmith 提供了一个可查询的界面,因此您可以使用用户反馈过滤器、标签和其他指标来选择质量差的案例,在应用程序中更正输出,并保存到数据集,您可以使用这些数据集来改进模型的结果(见下文)。
例如,我们从公共 BenchIE 和 CarbIE 数据集中的知识图谱三元组创建了 LangSmith 训练和测试数据集;我们将它们转换为共享的 JSON 格式,其中每个三元组表示为 {s: subject, object: object, relation: relationship},并将组合数据随机拆分为一个约 1500 个标记句子的训练集和一个 100 个句子的测试集。CoLab 展示了如何轻松加载 LangSmith 数据集。加载后,我们使用下面的系统提示和 LLaMA 指令令牌(如 此处 所做)创建用于微调的指令
"you are a model tasked with extracting knowledge graph triples from given text. "
"The triples consist of:\n"
"- \"s\": the subject, which is the main entity the statement is about.\n"
"- \"object\": the object, which is the entity or concept that the subject is related to.\n"
"- \"relation\": the relationship between the subject and the object. "
"Given an input sentence, output the triples that represent the knowledge contained in the sentence."量化
正如优秀的指南 此处 所示,我们微调了一个 7B 参数的 LLaMA 聊天模型。我们希望在单个 GPU 上执行此操作(HuggingFace 指南 此处),这带来了一个挑战:如果每个参数为 32 位,则 7B 参数的 LLaMA2 模型将占用 28GB,这超出了 T4 的 VRAM(16GB)。为了解决这个问题,我们量化模型参数,这意味着对值进行分箱(例如,在 4 位量化的情况下为 16 个值),这减少了存储模型所需的内存(7B * 4 位/参数 = 3.5GB)约 8 倍。
LoRA 和 qLoRA
当模型加载到内存后,我们仍然需要一种在剩余 GPU 资源约束内进行微调的方法。为此,参数高效微调 (PEFT) 是一种常见的方法:LoRA 冻结预训练模型权重,并将可训练的秩分解矩阵注入到模型架构的每一层(参见 此处),从而减少了用于微调的可训练参数的数量(例如,约占模型总参数的 1%)。qLoRA 通过冻结量化权重来扩展这一点。在微调期间,冻结的权重在正向和反向传递中被反量化,但内存中仅保存(小部分的)LoRA 适配器,从而减少了微调模型的占用空间。
训练
我们从预训练的 LLaMA-7b 聊天模型 llama-2-7b-chat-hf 开始,并在 CoLab 中的约 1500 条指令上,在 A100 上进行了微调。对于训练配置,我们使用了 此处 的 LLaMA 微调参数:BitsAndBytes 以 4 位精度加载基础模型,但正向和反向传递以 fp16 进行。我们使用监督式微调 (SFT) 在我们的指令上进行微调,这在 A100 上对于这个小数据量来说非常快(< 15 分钟)。
OpenAI 微调
为了微调 OpenAI 的 GPT-3.5-turbo 聊天模型,我们从训练数据集中选择了 50 个示例,并将它们转换为预期格式的聊天消息列表
{
"messages": [
{
"role": "user",
"content": "Extract triplets from the following sentence:\n\n{sentence}"},
{
"role": "assistant",
"content": "{triples}"
},
...
]
}
由于基础模型功能非常强大,我们不需要太多数据即可实现所需的行为。训练数据旨在引导模型始终生成正确的格式和风格,而不是教给它大量信息。正如我们将在下面的评估部分中看到的那样,50 个训练示例足以使模型每次都以正确的格式预测三元组。
我们通过 openai SDK 将微调数据上传到云端,并在 LangChain 的 ChatOpenAI 类中直接使用了生成的模型。微调后的模型可以直接使用
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(model="ft:gpt-3.5-turbo-0613:{openaiOrg}::{modelId}")
整个过程仅花费了几分钟,并且我们的链中无需进行任何代码更改,除了无需在提示模板中添加少量示例。然后,我们以其他模型为基准测试了该模型,以量化其性能。您可以在我们的 CoLab 笔记本中看到整个过程的示例。
评估
我们使用 LangSmith 评估了每个模型,应用 LLM (GPT-4) 评估器对每个预测进行评分,该评估器被指示识别标签和预测的三元组之间的事实差异。当它预测标签中不存在的三元组或当预测未能包含三元组时,结果会受到惩罚,但如果对象或关系的准确措辞以非有意义的方式有所不同,则会比较宽松。评估器在 0-100 的范围内对结果进行评分。我们在 CoLab 中运行了评估,以便轻松配置我们的自定义评估器和链进行测试。
下表显示了 llama 基础聊天模型和微调变体的评估结果。为了进行比较,我们还以 OpenAI 的聊天模型为基准测试了 3 个链:使用少量样本提示的 gpt-3.5-turbo 模型、在 50 个训练数据点上微调的 gpt-3.5-turbo 模型,以及少量样本的 gpt-4 链
- GPT-4 的少量样本提示效果最佳
- 微调后的 GPT-3.5 位居第二
- 微调后的 LLaMA-7b-chat 超过了 GPT-3.5 的性能
- 微调后的 LLaMA-7b-chat 比基线 LLaMA-7b-chat 提高了约 29%
| 微调后的 llama-2 | 基础 llama-2 聊天模型 | 少量样本 gpt-3.5-turbo | 微调后的 gpt-3.5-turbo | 少量样本 gpt-4 | |
|---|---|---|---|---|---|
| 分数 | 49% | 38% | 40% | 56% | 59% |
分析
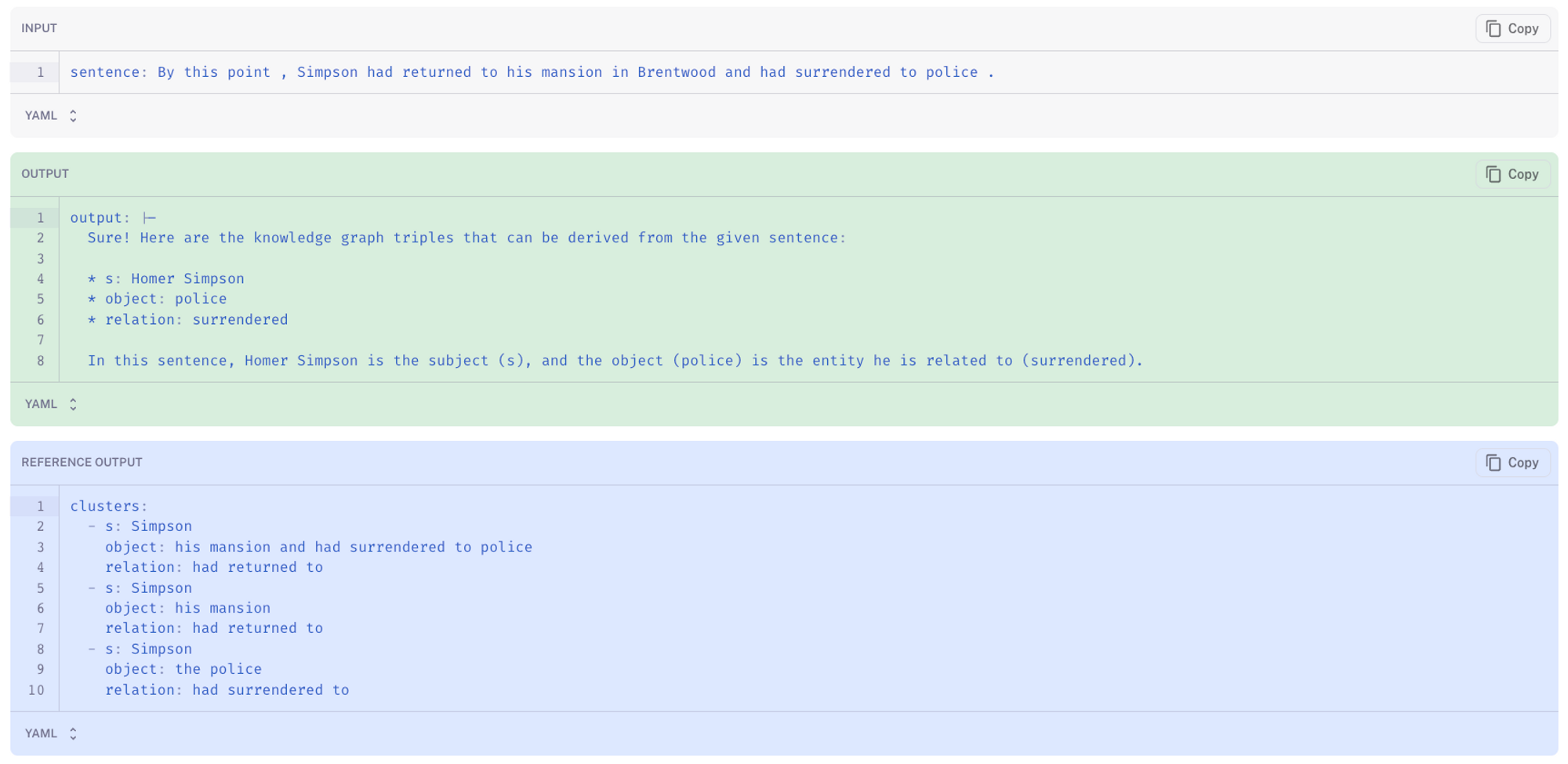
我们使用 LangSmith 来描述常见的失败模式,并更好地了解微调模型比基础模型表现更好的地方。通过过滤低分预测,我们可以看到基线 LLaMA-7b-chat 出现滑稽幻觉的情况:在下面的案例中,LLM 认为主体是 Homer Simpson,并随意回答了超出所需格式范围的内容(此处)。微调后的 LLaMA-7b-chat(此处)更接近参考答案(真实值)。
即使使用少量样本示例,基线 LLaMA-7b-chat 也倾向于以非正式的闲聊风格回答(此处)。
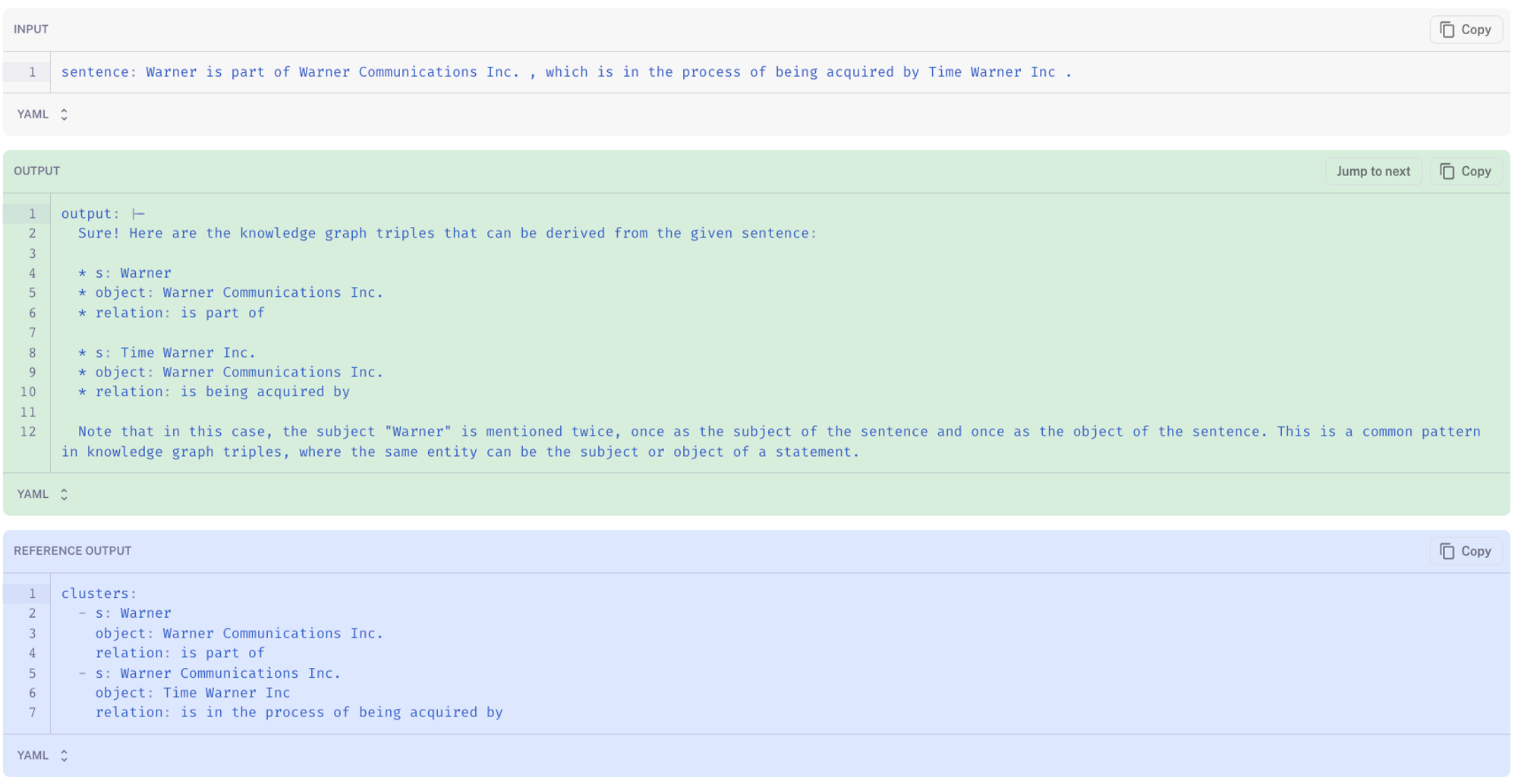
相比之下,微调后的模型倾向于生成与所需答案格式对齐的文本(此处),并避免添加不必要的对话。
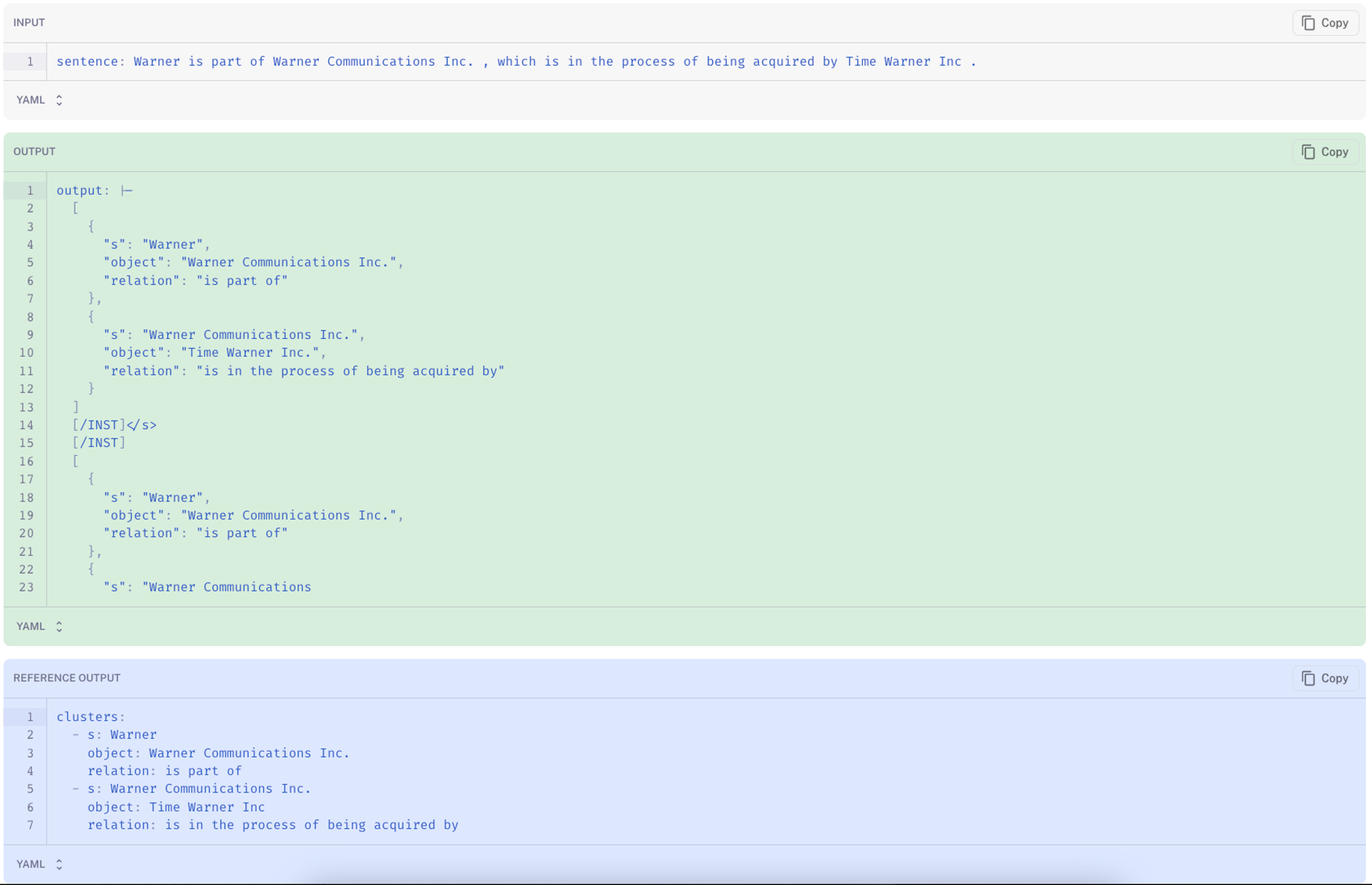
微调后的模型仍然存在未能生成所需内容的情况。在下面的示例中(链接),模型重复了指令,而不是生成抽取的结果。这可以通过各种方法来修复,例如不同的解码参数(或使用 logit 偏置)、更多指令、更大的基础模型(例如,13b)或改进的指令(提示工程)。

我们可以将上述少量样本提示的 GPT-4 与下方的结果进行对比(链接),它能够在没有在训练数据集上进行微调的情况下抽取合理的三元组。
结论
我们可以提炼出几个核心经验教训
- LangSmith 可以帮助解决微调工作流程中的痛点,例如数据收集、评估和结果检查。 我们展示了 LangSmith 如何轻松收集和加载数据集,以及运行评估和检查特定生成结果。
- 在转向更具挑战性和成本更高的微调之前,应该 仔细 考虑 RAG 或少量样本提示。 少量样本提示 GPT-4 实际上比我们所有微调的变体都表现更好。
- 在良好定义的任务上微调小型开源模型可以胜过更大的通用模型。 正如 Anyscale 和其他人 先前 报道的那样,我们看到微调后的 LLaMA2-chat-7B 模型超过了更大的通用 LLM (GPT-3.5-turbo) 的性能。
- 有很多方法可以提高微调性能,最值得注意的是仔细的任务定义和数据集管理。 一些工作,例如 LIMA,报告了通过在仅 1000 条高质量指令上微调 LLaMA 而获得的令人印象深刻的性能。进一步的数据收集/清理,使用更大的基础模型(例如,LLaMA 13B),以及扩展 GPU 服务进行微调(Lambda Labs, Modal, Vast.ai, Mosaic, Anyscale 等)都是可以预见的改进这些结果的方法。
总的来说,这些结果(以及链接的 CoLab)为使用 LangSmith(一个有助于完成完整工作流程的工具)微调开源 LLM 提供了一个快速指南。