重要链接
评估是持续改进您的 LLM 应用程序的过程。 这需要一种衡量应用程序性能的方法。
LLM 应用程序通常以自然语言生成输出,这很难使用硬编码规则来判断。 例如,相对于参考输出,简洁性或正确性等属性难以用典型的单元测试来表达。
使用“LLM-as-a-Judge”是评估 LLM 应用程序自然语言输出的一种流行方式。 这涉及将生成的输出(和其他信息)传递给单独的 LLM,并要求它判断输出。 虽然这已被证明在多种情况下很有用,但它提出了一个有趣的问题:您现在必须进行另一轮提示工程,以确保 LLM-as-a-Judge 表现良好。
LangSmith 为这个日益严重的问题提供了一个新颖的解决方案。 LangSmith 评估器现在具有“自我改进”功能,其中对 LLM-as-a-Judge 输出的人工修正被存储为少样本示例,然后在未来的迭代中反馈到提示中。
在这篇文章中,我们将讨论 LLM-as-a-Judge 评估器的兴起、一些促使我们找到这个解决方案的动机研究,然后深入探讨这究竟是如何实现的。 如果您想试用,可以在此免费注册 LangSmith。
LLM-as-a-Judge
以编程方式评估 LLM 输出通常很困难。 这很大程度上是由于缺乏良好的指标。 当然,如果您正在进行分类或命名实体提取或其他“传统”ML 任务,那么可以使用标准的 ML 指标。 但是,如果您正在进行更多“生成式”任务(大多数应用程序通常都是如此),那么就没有太多好的选择。
评估非常重要! 您不能只是启动一个应用程序并寄希望于最好的结果 - 您应该评估其在真实数据上的性能,对您的应用程序进行更改,然后确保更改不会导致回归。 我们看到构建者在在线和离线评估阶段都花费了大量时间 - 并因此构建了 LangSmith。
LangSmith 在您使用的指标方面不持意见(我们看到几乎每个人都定义了自己的自定义指标)。 我们与 Elastic 和 Rakuten 等出色的团队合作过,亲眼目睹了他们如何进行评估——我们注意到的一件事是“LLM-as-a-Judge”评估器的使用量正在增加。
“LLM-as-a-Judge”评估器只是一个使用 LLM 对输出进行评分的评估器。 当以编程方式评估应用程序很困难,并且唯一的其他方法是人工标注时,这通常很有用。 我们看到的关键用例包括
- 检测 RAG 幻觉(在线评估)
- 检测 RAG 正确性(离线评估)
- 检测 LLM 是否生成了有害或不适当的答案(离线和在线评估)
为什么这有效? 如果 LLM 首先生成答案,那么为什么使用 LLM 对结果进行评分实际上会起作用呢?
这里有两个因素在起作用。 首先,在评估期间,LLM 可以访问它在生成时没有的信息。 例如,在判断 RAG 正确性时,您为评估器 LLM 提供标准答案,并要求它与该答案进行比较。 显然,这是您当时没有的信息。 其次,对于 LLM 来说,判断答案的正确性比生成正确答案本身更容易。 任务的这种“简化”使 LLM-as-a-Judge 变得可行。
虽然此过程可以很好地工作,但它也存在复杂性。 您仍然必须为评估器提示进行另一轮提示工程,这可能非常耗时,并且会阻碍团队建立适当的评估系统。 通过 LangSmith,我们的目标是简化此评估过程。
动机研究
有两项动机研究促使我们实施解决方案。
第一项研究并不新鲜:语言模型擅长少样本学习。 如果您给 LLM 提供正确完成事情的示例,它们将模仿正确的行为。 这种方法在我们的客户端 LLM 应用程序中被广泛采用; 它在难以用指令解释 LLM 应该如何表现,并且期望输出具有特定格式的情况下尤其有效。 评估符合这两个标准!
另一项研究是新的:伯克利 Shreya Shankar 的一篇论文,题为谁来验证验证者? 使 LLM 辅助的 LLM 输出评估与人类偏好对齐。 本文解决了相同的问题,并且,虽然它提出了与我们不同的解决方案,但它有助于激发我们使用反馈收集作为一种以编程方式使 LLM 评估与人类偏好对齐的方法。
那么 - 我们是如何将这两个想法结合起来并构建我们的“自我改进”评估器的呢?
我们的解决方案:LangSmith 中的自我改进评估
基于最近的研究和 LLM-as-a-Judge 评估器的广泛采用,我们为 LangSmith 评估器开发了一种新颖的“自我改进”系统。 这种方法旨在简化使 LLM 评估与人类偏好对齐的过程,消除对大量提示工程的需求。 以下是它的工作原理
首先,将 LLM 设置为裁判(在线或离线): 用户可以轻松地在 LangSmith 中为在线或离线评估设置 LLM-as-a-Judge 评估器。 这种初始设置只需要最少的配置,因为系统旨在随着时间的推移而改进。 设置时,您可以指定应如何将少样本示例格式化到提示中。

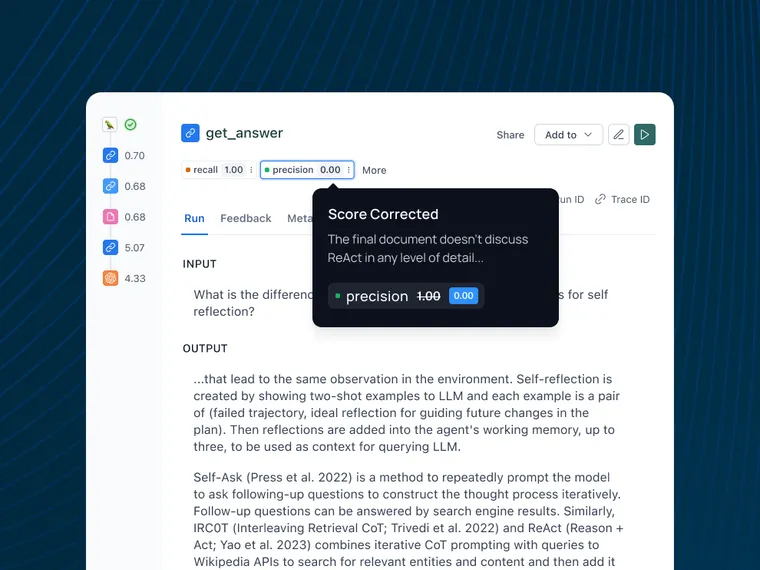
- 让它留下反馈:LLM 评估器提供有关生成输出的反馈,评估正确性、相关性或在先前步骤中指定为裁判一部分的任何其他标准等因素。
- 用户可以直接在应用程序中对该反馈进行更正: 当用户审查 LLM 的评估时,他们可以直接在 LangSmith 界面中修改或更正反馈。 此步骤对于捕获人类偏好和判断至关重要。
- 这些更正将存储为少样本示例: LangSmith 会自动将这些人工更正存储为少样本示例。 这创建了一个不断增长的人工对齐评估数据集,反映了您的团队或应用程序的特定偏好和标准。 您还可以在此流程中为您的更正留下解释。
- 下次评估器运行时,它将存储这些示例(以及可选的解释)并使用它们来告知其生成: 在随后的评估运行中,系统会将这些存储的示例合并到 LLM-as-a-Judge 的提示中。 通过利用语言模型的少样本学习能力,评估器会随着时间的推移越来越符合人类的偏好。
有关更多技术演示,请参阅本操作指南。
这种自我改进的循环使 LLM-as-a-Judge 能够根据真实世界的反馈来调整和完善其评估,从而消除手动提示调整或耗时的提示工程。 现在,团队可以专注于在必要时审查和更正评估,因为他们知道他们的输入直接提高了系统随时间推移的性能。
结论
LLM-as-a-Judge 评估器是评估生成式 AI 系统的强大工具,但在提示工程和人类偏好对齐方面提出了新的挑战。 LangSmith 的自我改进评估器为这个问题提供了一个优雅的解决方案,利用少样本学习和用户更正来整合人类反馈,以实现准确、相关的评估,而无需持续的手动干预。
随着 AI 的快速发展,自我改进的评估器将在弥合机器能力与人类期望之间的差距方面发挥关键作用。 通过 LangSmith,我们正在帮助团队以更大的信心和效率构建、评估和改进他们的 AI 应用程序。 如果您还没有 - 在此免费注册 LangSmith。